Chapter 11 Percentiles
In the previous chapter, we calculated z-scores for males in our sample. We calculated the z-scores using three different frames of references: all sample data (male and female), male sample data, and Canadian males. Recall that a z-score provides information relative to a frame of reference (e.g., all sample data, male sample data, Canadian males). For a given frame a reference, a z-score of 0 represents the mean of that frame of reference. Positive z-scores indicate participants above the mean for the frame of reference whereas negative z-score indicate participants below the mean for the frame of reference. A value of 1 corresponds to one standard deviation. Therefore, a person with a z-score of 2 is two standard deviations above the mean.
11.1 Assuming a normal distribution approach
11.1.1 A single case
If we assume our frame of reference has a normal distribution, we can calculate for one person the proportion of people who scored the same or lower than them. We multiply that proportion by 100 and we have the percentage, The percentage indicates the percentage of people who score the same or lower than them. We refer to this number as the percentile for that person.
Imagine a person has a z-score of 0 relative to some reference group. If the distribution is normal, we can determine the proportion of people, in the reference group, that have the same score or a lower score using the command pnorm() command below. We simply put the z-score in the brackets of the pnorm() command:
pnorm(0)## [1] 0.5We see that the proportion of people in the reference group with a z-score of zero or lower is 0.50.
We can convert this proportion to a percentage by mulitplying it by 1000:
0.500 * 100## [1] 50We see the percentage is 50%. This indicates that 50% of the reference group had a z-score of 0 or lower – assuming the distribution is normal. We illustrate this graphically below:
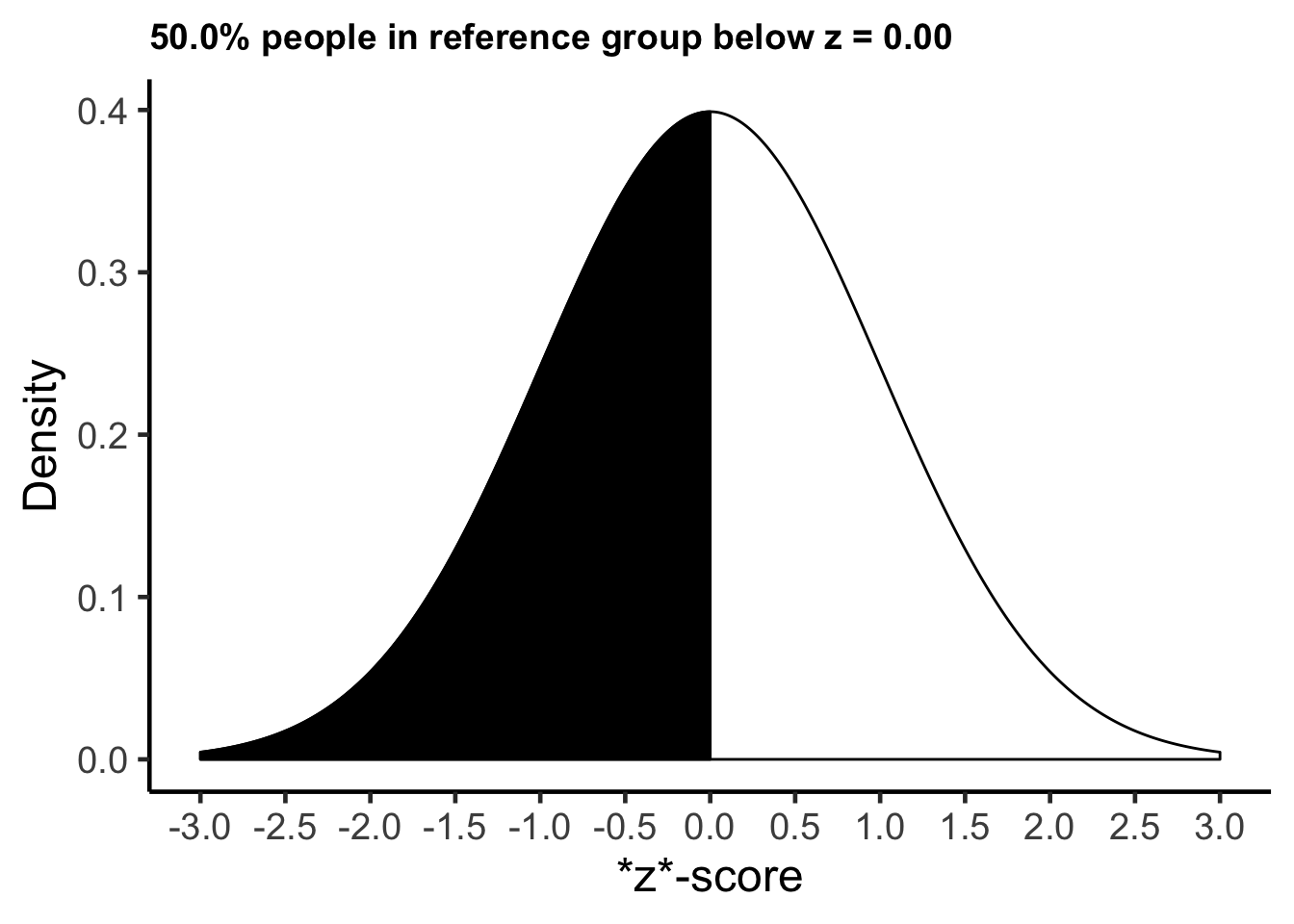
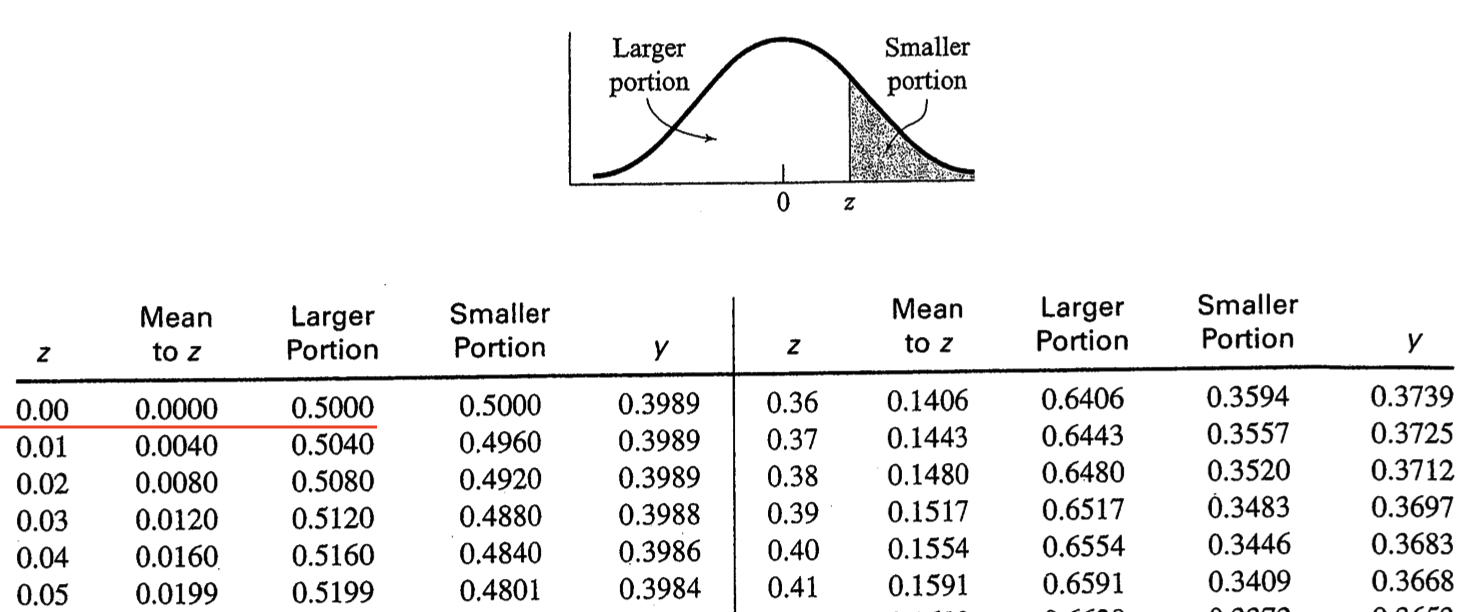
Of course, the pnorm(0) command is the same as looking up a value of zero in a z-table – as illustrated below. Examine the first row that is underlined in red. Notice the value of 0 in the z column (indicating a z-score of zero). Then examine the “Larger portion” column and notice the .50 value. This .50 indicates the proportion of the distribution is below a z-score of zero (i.e., .50 or 50%). As noted, examining the table in this way is the same as running pnorm(0) command.
11.1.2 Many cases using R
Let’s return to the male_height_data from the previous chapter. We begin with the data set as it existed at the end of the last chapter. We take only a few essential columns from that data and place them into a new data set called male_height_canada_percentiles with commands below. Note that we use arrange(desc(cm_height)) to sort the order of the rows so that the tallest people are at the top of the table. The desc() function makes the order of the rows based on cm_height descending.
male_height_canada_percentiles <- male_height_data %>%
select(name, cm_height, z_canada_male) %>%
arrange(desc(cm_height))
print(male_height_canada_percentiles)## # A tibble: 10 × 3
## name cm_height z_canada_male
## <chr> <dbl> <dbl>
## 1 John 190 0.542
## 2 Basheer 185 -0.153
## 3 Rick 183 -0.431
## 4 Matt 180 -0.847
## 5 Sean 179 -0.986
## 6 Eli 174 -1.68
## 7 Tim 173 -1.82
## 8 Jamal 172 -1.96
## 9 Jim 168 -2.51
## 10 Steve 165 -2.93For each person we will calculate the proportion of the distribution of Canadian males that the same height or shorter than them via the normal distribution. We will place this information in the proportion_lower column. The proportion_lower column is calculated via the mutate() command using pnorm(). Following creation of the proportion_lower column we create the percentile column by multiplying the proportion_lower column by 100 - again using the mutate() command:
male_height_canada_percentiles <- male_height_canada_percentiles %>%
mutate(proportion_lower = pnorm(z_canada_male)) %>%
mutate(percentile = proportion_lower * 100)
print(male_height_canada_percentiles)## # A tibble: 10 × 5
## name cm_height z_canada_male proportion_lower percentile
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 John 190 0.542 0.706 70.6
## 2 Basheer 185 -0.153 0.439 43.9
## 3 Rick 183 -0.431 0.333 33.3
## 4 Matt 180 -0.847 0.198 19.8
## 5 Sean 179 -0.986 0.162 16.2
## 6 Eli 174 -1.68 0.0464 4.64
## 7 Tim 173 -1.82 0.0344 3.44
## 8 Jamal 172 -1.96 0.0251 2.51
## 9 Jim 168 -2.51 0.00597 0.597
## 10 Steve 165 -2.93 0.00169 0.169Examine the pattern of results for these males. Pay particular attention to the percentile column for Rick, Basheer, and John. For each of these cases we create a graph (based on the numbers in the table above) to illustrate the percentage of Canadian males that are shorter (i.e., have lower height values). Keep in mind, when we calculate the “percentage lower” the resulting number is always for the same frame of reference that we used to calculate the z-score. In this case, the z-scores (z_canada_male) used all Canadian males as the frame of reference.
11.1.2.1 Rick
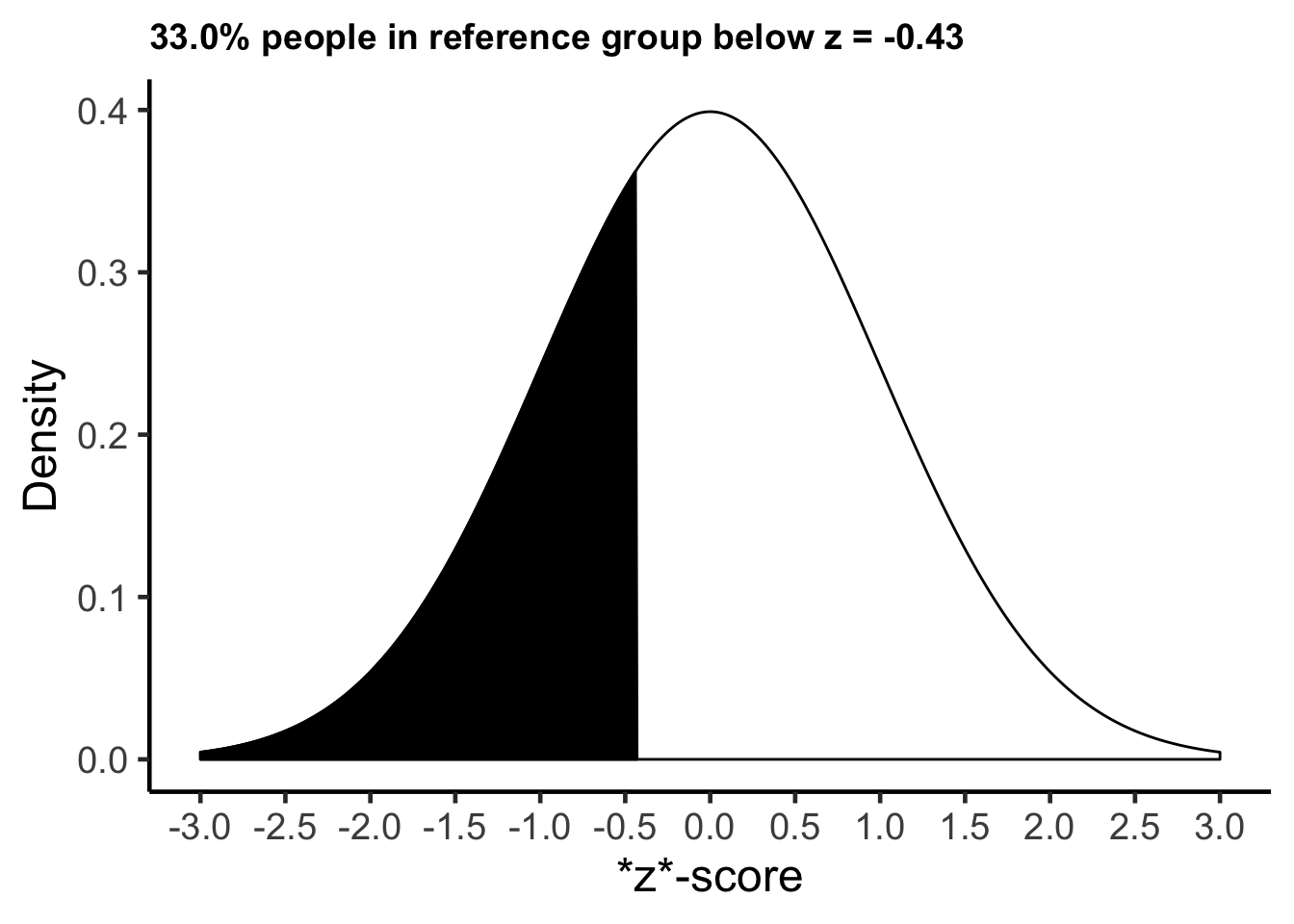
Rick had a z-score of \(z\) = -0.43 when using all Canadian males as a frame of reference. He is 0.43 standard deviations shorter than the average Canadian male. If we assume the heights of Canadian males are normally distributed, as we did in the calculations above, we find that 33% of Canadian males are shorter than Rick. We say Rick is in the 33rd percentile.
11.1.2.2 Basheer
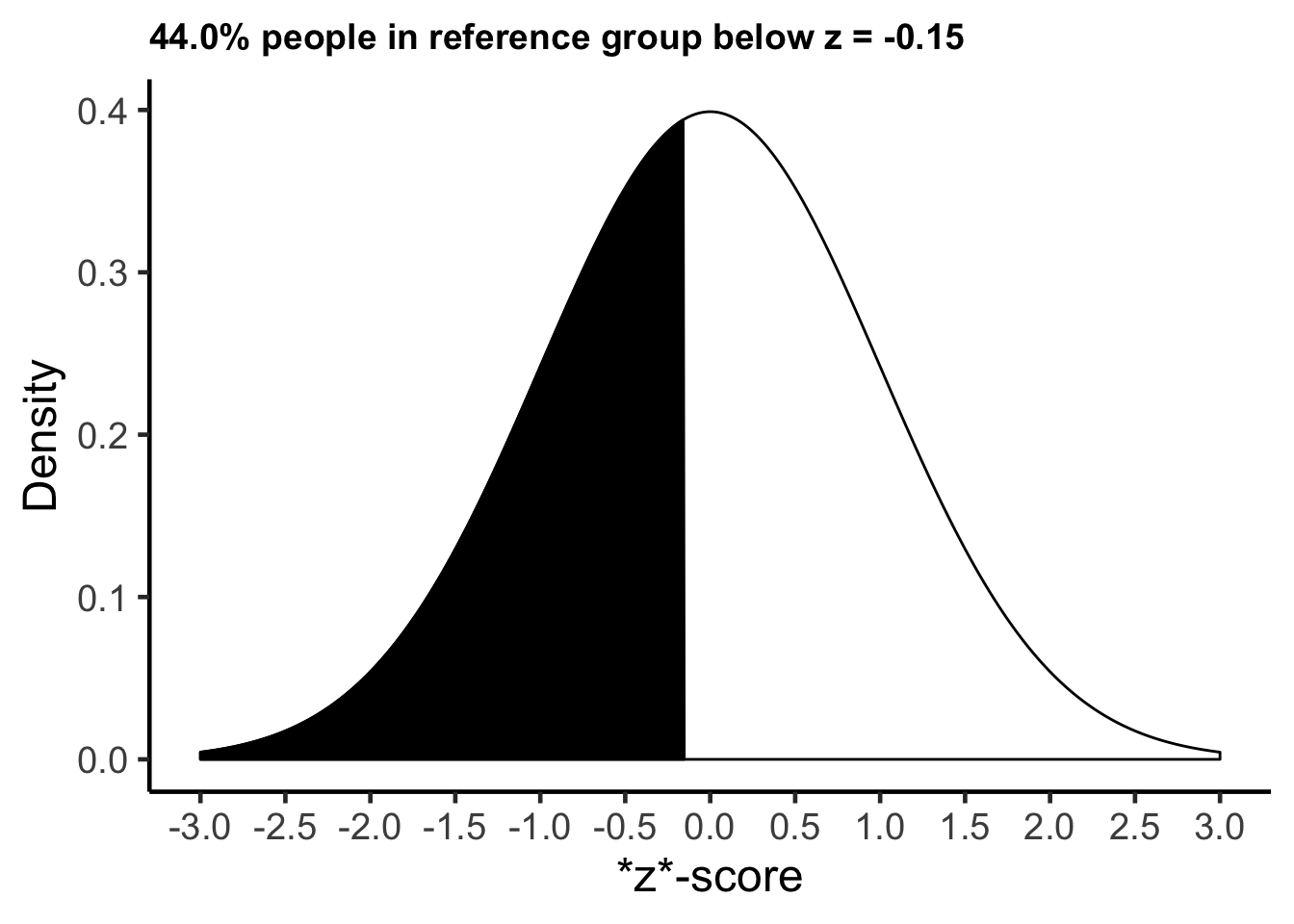
Basheer had a z-score of \(z\) = -0.15 when using all Canadian males as a frame of reference. He is 0.15 standard deviations shorter than the average Canadian male. If we assume the heights of Canadian males are normally distributed, as we did in the calculations above, we find that 44% of Canadian males are shorter than Basheer. We say Basheer is in the 44th percentile.
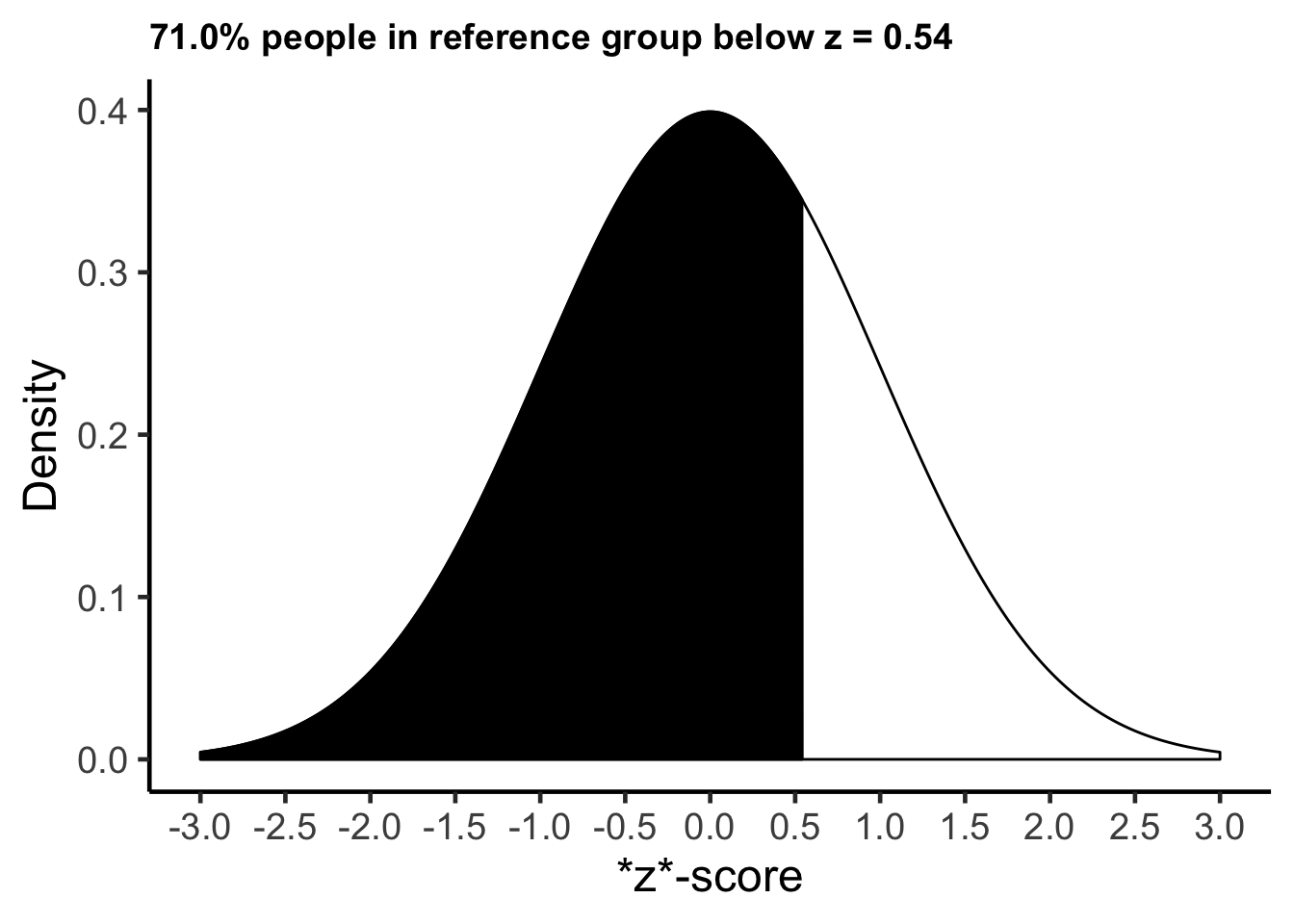
11.1.2.3 John
John had a z-score of \(z\) = .54 when using all Canadian males as a frame of reference. He is 0.54 standard deviations taller than the average Canadian male. If we assume the heights of Canadian males are normally distributed, as we did in the calculations above, we find that 71% of Canadian males are shorter than John. We say John is in the 71st percentile.
11.2 Assumption free approach
The decision to assume a normal distribution, as we did above, depends on a few things. In order to make a normal distirbution assumption we would a) want to ensure we had a very large number of people in our frame of reference and b) that the shape was actually normal - as determined by a visual inspection of a histogram or a statistical test. If both of these things are true we can use the normal distribution to calculate a percentile for each person. If both of these things are not true - we need to use another approach. That’s the focus of this section.
Rank order the participants in the frame of reference by attribute of interest (e.g., height) so the larger numbers are at the top of the list
Determine how many people in the frame of reference have scores below each person on the attribute of interest.
Divide the “number below” by the total number of people in the frame of reference.
We will follow these steps using R.
We begin by creating a new data set called male_height_sample_percentiles we include just the name and cm_height columns in this data set.
male_height_sample_percentiles <- male_height_data %>%
select(name, cm_height)
print(male_height_sample_percentiles)## # A tibble: 10 × 2
## name cm_height
## <chr> <dbl>
## 1 John 190
## 2 Jim 168
## 3 Steve 165
## 4 Jamal 172
## 5 Eli 174
## 6 Sean 179
## 7 Basheer 185
## 8 Matt 180
## 9 Tim 173
## 10 Rick 183Step 1: Sort by height We sort the rows by height - ensuring the tallest males are at the top of the list by using the arrange(desc(cm_height)) command:
male_height_sample_percentiles <- male_height_sample_percentiles %>%
arrange(desc(cm_height))
print(male_height_sample_percentiles)## # A tibble: 10 × 2
## name cm_height
## <chr> <dbl>
## 1 John 190
## 2 Basheer 185
## 3 Rick 183
## 4 Matt 180
## 5 Sean 179
## 6 Eli 174
## 7 Tim 173
## 8 Jamal 172
## 9 Jim 168
## 10 Steve 165Step 2: Number below
Because the heights are now sorted we can determine the number of people on the list below each person just by their position in the list. For example, John is the tallest and there 9 people shorter than him. Basheer is the second tallest and there are 8 people shorter than him. We need a column of numbers with the values 9, 8, 7, 6, 5, 4, 3, 2, 1, 0. We use the command: n():1. The n() refers to the number of people in the data set. Correspondingly, n():1 creates the numbers 10, 9, 8, 7, 6, 5, 4, 3, 2, 1. We subtract 1 from these values to obtain 9, 8, 7, 6, 5, 4, 3, 2, 1, 0.
male_height_sample_percentiles <- male_height_sample_percentiles %>%
mutate(number_below = n():1 - 1)
print(male_height_sample_percentiles)## # A tibble: 10 × 3
## name cm_height number_below
## <chr> <dbl> <dbl>
## 1 John 190 9
## 2 Basheer 185 8
## 3 Rick 183 7
## 4 Matt 180 6
## 5 Sean 179 5
## 6 Eli 174 4
## 7 Tim 173 3
## 8 Jamal 172 2
## 9 Jim 168 1
## 10 Steve 165 0Step 3: Calculate percentile
We create a new column called proportion_lower using a mutate() command. In this column we index the proportion of people with the same height or a shorter height by dividing each value in the number_below column by the total number of people (obtained via the n() command). Following this we create a percentile column by multiplying the values in the proportion_lower column by 100.
male_height_sample_percentiles <- male_height_sample_percentiles %>%
mutate(proportion_lower = number_below / n()) %>%
mutate(percentile = proportion_lower * 100)
print(male_height_sample_percentiles)## # A tibble: 10 × 5
## name cm_height number_below proportion_lower percentile
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 John 190 9 0.9 90
## 2 Basheer 185 8 0.8 80
## 3 Rick 183 7 0.7 70
## 4 Matt 180 6 0.6 60
## 5 Sean 179 5 0.5 50
## 6 Eli 174 4 0.4 40
## 7 Tim 173 3 0.3 30
## 8 Jamal 172 2 0.2 20
## 9 Jim 168 1 0.1 10
## 10 Steve 165 0 0 0If you inspect the percentile column above you can see how we calculated the percentile for each person in the data set without using the normal distribution or z-scores.