3Bivariate Regression: A Lens for Understanding Intervals
3.1 Model
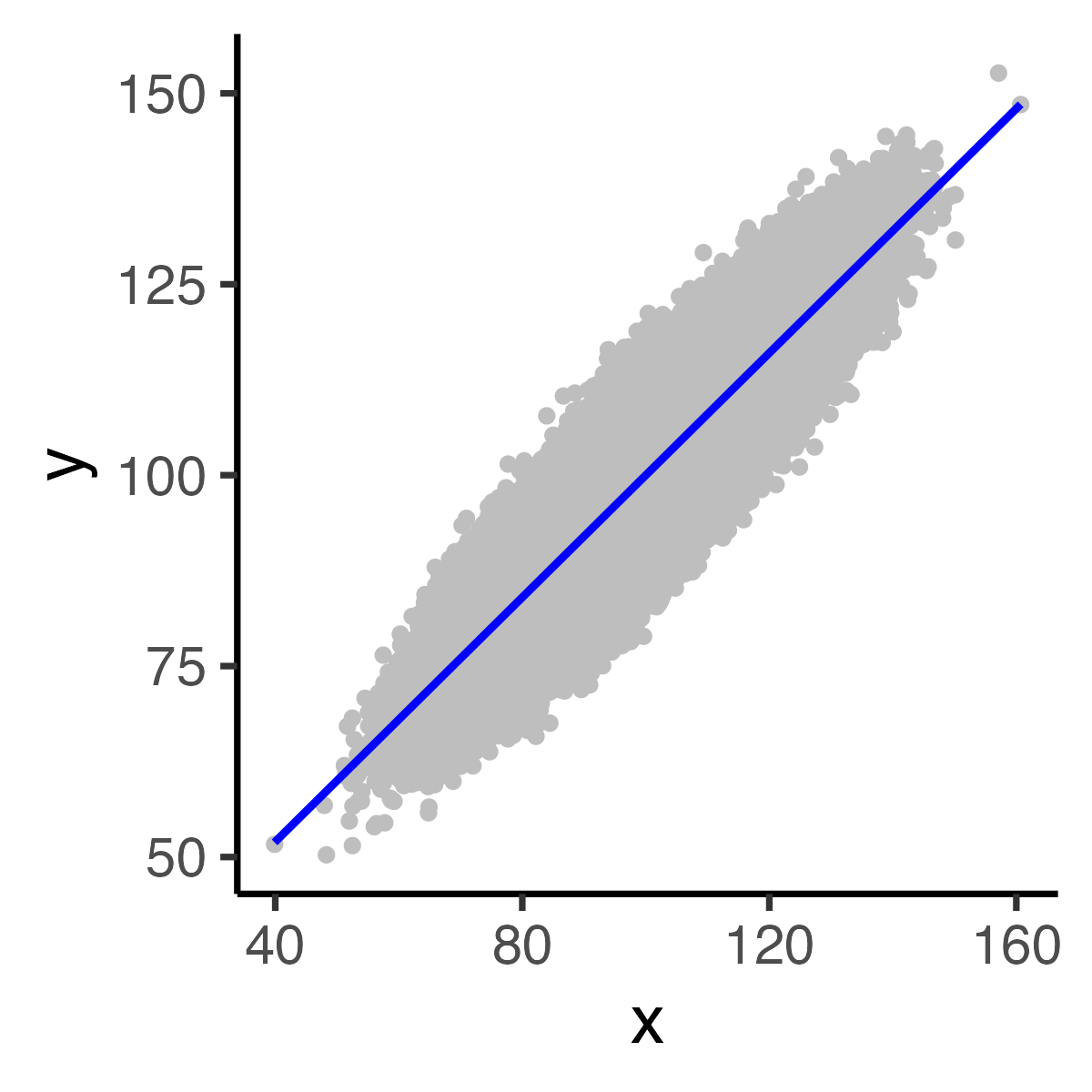
We make a regression predicting \(y\) using \(x\) with the code below. Notice the regression line has a slope of .80 and an intercept of 20.
# Will use the generic labels of y and x in the regression demonstration# We create variables with these labelsy <- truex <- observed# Create the regression model relating x to y using the lm() command. lm() is linear model.my_model <-lm(y ~ x)print(my_model)
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
20.0 0.8
3.1.1 Using the Model: Predicted Values
We graph the relation between \(x\)-values and \(y\)-values with the code below. We include the regression line described in the output above using the geom_smooth() command. Warning: This make take a few minutes to plot.
# Create a data frame (spreadsheet style) version of the datamy_df <-data.frame(y, x)# Plot the data and use geom_smooth() # to show regression lineggplot(data = my_df,mapping =aes(x = x,y = y)) +geom_point(color ="grey") +geom_smooth(method = lm,formula = y ~ x,color ="blue") +theme_classic(18)
3.1.2 Predicted Values With the Regression Equation
Using \(x=120\) we create a predicted value for \(y\) (i.e., a \(\hat{y}-value\)) for the graph above. This predicted value is the spot on the regression line above \(x=120\). We do so with knowledge of the full regression equation, including the intercept.
b =0.80# the slopeintercept =20yhat = b*(120) + interceptprint(yhat)
[1] 116
3.1.3 Predicted Values Without the Regression Equation
A predicted value can be created without a regression equation - as explained in the paper. As before, using \(x=120\) we create a predicted value for \(y\) (i.e., a \(\hat{y}-value\)) for the graph above. We do so WITHOUT knowledge of the full regression equation - we do not know the intercept but we do know the mean of \(x\) and the mean of \(y\). The regression line will always run through the point (\(\bar{x}, \bar{y}\)) - so this is used as a frame of reference. Because we do not know true scores in an applied context, we use this approach to generated predicted values for measurement intervals.
b =0.80# the slopeyhat =mean(y) + b*(120-mean(x))print(yhat)
[1] 116
3.1.4 Interpretion of Predicted Values
The predicted value of \(y\) (i.e., \(\hat{y}-value\)) is an estimate of the mean value of \(y\) for those test takers with the specified value of \(x\). In this example \(x = 120\). For participants with score of 120 on the \(x\)-axis we calculate the mean value of their \(y\) scores. We see the resulting mean is the same as the \(\hat{y}-value\) above.
people_with_x_equal_120 <-round(x) ==120# mean y-value for these peopleprint( mean( y[people_with_x_equal_120] ) )
[1] 115.9464
In the previous step, we estimated a mean \(y\)-value as \(\hat{y}=116\) for people with an observed score of 120. In this simulation we correspondingly found a mean \(y\)-value of 116 (rounded).
3.2 Errors
Notice in the output below that residual standard error is 4.47. This value is the standard deviation of the residuals around the regression line.
summary(my_model)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-20.8089 -3.0177 -0.0016 3.0176 21.6884
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.00000 0.04025 496.9 <2e-16 ***
x 0.80000 0.00040 2000.0 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.472 on 999998 degrees of freedom
Multiple R-squared: 0.8, Adjusted R-squared: 0.8
F-statistic: 4e+06 on 1 and 999998 DF, p-value: < 2.2e-16
We can obtain the same 4.47 value using the equation below. This equation is central to the derivation of the error equations for Standard Error of Estimation and Standard Error of Measurement.