Chapter 27 Cookbook
The chapter provide a series of “Cookbook” receipes for starting different types of analysis scripts.
27.1 Required Packages
The data files below are used in this chapter.
| Required Data |
|---|
| data_ex_between.csv |
| data_ex_within.csv |
| data_food.csv |
| data_item_scoring.csv |
| data_item_time.csv |
The following CRAN packages must be installed:
| Required CRAN Packages |
|---|
| apaTables |
| Hmisc |
| janitor |
| psych |
| skimr |
| tidyverse |
Important Note: You should NOT use library(psych) at any point! There are major conflicts between the psych package and the tidyverse. We will access the psych package commands by preceding each command with psych:: instead of using library(psych).
27.2 Following the examples
Below we present example scripts transforming raw data to analytic data for various study designs (experimental and survey). These examples illustrate the value of using the naming conventions outlined previously. Don’t just read the example - follow along with the projects by creating a separate script for each example. Resist the urge to cut and paste from this document - type the script yourself.
When first learning iPhone/Mac software development, I did so by taking a course at Big Nerd Ranch - yes, that’s a real place. They advised in their material (and now book) the following: “We have learned that “going through the motions” is much more important than it sounds. Many times we will ask you to start typing in code before you understand it. We realize that you may feel like a trained monkey typing in a bunch of code that you do not fully grasp. But the best way to learn coding is to find and fix your typos. Far from being a drag, this basic debugging is where you really learn the ins and outs of the code. That is why we encourage you to type in the code yourself. You could just download it, but copying and pasting is not programming. We want better for you and your skills.”, p. xiv, (Keur and Hillegass 2020). This is excellent advice for a beginning statistician or data scientist as well. And as an aside: if you want to learn iPhone programming you can’t go wrong with the Big Nerd Ranch guide!
As you work through this chapter, create your own new script for each example. In light of the above advice, avoid copying and pasting code - type it out; you will be the better for it.
Getting started:
The Class: R Studio in the Cloud Assignment
- The data should be in the assignment project automatically. Just start the assignment.
For everyone in the class, that’s it.
For those of you not in the class, and reading this work, see the two options below:
R Studio Cloud, custom project
Create a new Project using the web interface
Upload all the example data files into the project. The data files needed are listed at the beginning of this chapter. The upload button can be found on the Files tab.
R Studio Computer, custom project
Create a folder on your computer for the example
Place all the example data files in that folder. The data files needed are listed at the beginning of this chapter.
Use the menu item File > New Project… to start the project
On the window that appears select “Existing Directory”
On the next screen, press the “Browse” button and find/select the folder with your data
Press the Create Project Button
Regardless of whether your are working from the cloud, or locally, you should now have an R Studio project with your data files in it.
We anticipate that many people will doubtless want to refer back to an encapsulated set of instructions for each design. Therefore the example for each design is written in a way that it stands alone. A consequence of this approach is that there is some redundancy in the code across examples. We see this a strength - because readers will see the commonalities across differ types of designs.
As you make a script for each example:
Recall the instruction from Chapter 1 about putting the date and your name in the script via comments.
Recall the instruction from Chapter 1 about running library(tidyverse) before you type the rest of each script - this provides you with tidyverse autocomplete for the script.
After you type each new block of code in an example, save your script.
After you type each new block of code in an example, do two additional things: 1) Session Restart R, 2) Run your script using Source with Echo.
27.3 Entering data into spreadsheets
The first example uses a data file data_ex_between.csv that corresponds to a fictitious example where we recorded the run times for a number of male and female participants. How did we create this data file? We used a spreadsheet to enter the data, as illustrated in Figure 27.1. Programs like Microsoft Excel and Google Sheets are good options for entering data.
FIGURE 27.1: Spreadsheet entry of running data
The key to using these types of programs is to save the data as a .csv file when you are done. CSV is short for Comma Separated Values. After entering the data in Figure 27.1 we saved it as data_ex_between.csv. There is no need to do so, but if you were to open this file in a text editor (such as TextEdit on a Mac or Notepad on Windows) you would see the information displayed in Figure 27.2. You can see there is one row per person and the columns are created by separating each values by a comma; hence, comma separated values.

FIGURE 27.2: Text view of CSV data
There are many ways to save data, but the CSV data is one of the better ones because it is a non-proprietary format. Some software, such as SPSS, uses a proprietary format (e.g., .sav for SPSS) this makes it challenging to access that data if you don’t have that (often expensive) software. One of our goals as scientists is to make it easy for others to audit our work - that allows science to be self-correcting. Therefore, choose an open format for your data like .csv.
27.4 Experiment: Between
This section outlines a workflow appropriate for when you plan to a conduct independent-groups t-test or a between-participants ANOVA.
To Begin:
Use the Files tab to confirm you have the data: data_ex_between.csv
Start a new script for this example. Don’t forget to start the script name with “script_”.
As noted previously, these data correspond to a design where the researcher is interested in comparing run times (elapsed_time) based on sex (male/female).
# Date: YYYY-MM-DD
# Name: your name here
# Example: Between-participant experiment
# Load data
library(tidyverse)
my_missing_value_codes <- c("-999", "", "NA")
raw_data_between <- read_csv(file = "data_ex_between.csv",
na = my_missing_value_codes)We load the initial data into a raw_data_between data set but immediately make a copy that we will work with called analytic_data_between. It’s good to keep a copy of the raw data for reference in the event that you encounter problems.
After loading the data we do initial cleaning to remove empty row/columns and ensure proper naming for columns:
library(janitor)
# Initial cleaning
analytic_data_between <- analytic_data_between %>%
remove_empty("rows") %>%
remove_empty("cols") %>%
clean_names()You can confirm the column names follow our naming convention with the glimpse() command.
## Rows: 6
## Columns: 3
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <chr> "male", "female", "male", "female", "…
## $ elapsed_time <dbl> 40, 35, 38, 33, 42, 3627.4.1 Creating factors
Following initial cleaning, we identify categorical variables as factors. If you plan to conduct an ANOVA - it’s critical that all predictor variables are converted to factors. Inspect the glimpse() output - if you followed our data entry naming conventions, categorical variables should be of the type character. We have one variable, sex, that is a categorical variable of type character (i.e., chr). The participant id column is categorical as well, but of type double (i.e., dbl) which is a numeric column.
## Rows: 6
## Columns: 3
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <chr> "male", "female", "male", "female", "…
## $ elapsed_time <dbl> 40, 35, 38, 33, 42, 36You can quickly convert all character columns to factors using the code below. In this case, the code just converts the sex column to a factor. Because there is only one column (sex) being converted to a factor, we could have treated it the same way as the id column below. However, we use this code because of its broad applicability to many scripts.
analytic_data_between <- analytic_data_between %>%
mutate(across(.cols = where(is.character),
.fns = as_factor))The participant identification number in the id column is a numeric column, so it was not converted by the above code. The id column is converted to a factor with the code below.
You can ensure both the sex and id columns are now factors using the glimpse() command.
## Rows: 6
## Columns: 3
## $ id <fct> 1, 2, 3, 4, 5, 6
## $ sex <fct> male, female, male, female, male, fem…
## $ elapsed_time <dbl> 40, 35, 38, 33, 42, 36This example is so small it’s clear you didn’t miss converting any columns to factors. In general, however, at this point you should inspect the output of the glimpse() command and make sure you have converted all categorical variables to factors - especially those you will use as predictors.
27.4.2 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels:
## id sex
## 1:1 male :3
## 2:1 female:3
## 3:1
## 4:1
## 5:1
## 6:1The order of the levels influences how graphs are generated. In these data, the sex column has two levels: male and female in that order. The code below adjusts the order of the sex variable because we want the x-axis of a future graph to display columns in the left to right order: female, male.
You can see the new order of the factor levels with summary():
## id sex
## 1:1 female:3
## 2:1 male :3
## 3:1
## 4:1
## 5:1
## 6:127.4.3 Numeric screening
For numeric variables, you should search for impossible values. For example, in the context of this example you want to ensure that none of the elapsed_times are impossible, or so large they appear to be data entry errors. One option for doing so is the summary command again. This time, however, we use “is.numeric” in the where() command.
## elapsed_time
## Min. :33.0
## 1st Qu.:35.2
## Median :37.0
## Mean :37.3
## 3rd Qu.:39.5
## Max. :42.0Scan the min and max values to ensure there are not any impossible values. If necessary, go back to the original data source and fix these impossible values. Alternatively, you might need to change them to missing values (i.e., NA values).
In this example all the values are reasonable values. However, if we discovered an out of range value (or values) for elapsed time, we could convert those values to missing values with the code below. This code changes (i.e., mutates) a value in the elapsed_time column to become NA (not available or missing) if that value is less than zero. If the value is greater than, or equal to zero, it stays the same. Note that when using this command we have to be very specific in terms of specifying our missing value. It usually needs to be one of NA_real_ or NA_character_. For numeric columns use NA_real_ and for character columns use NA_character_.
analytic_data_between <- analytic_data_between %>%
mutate(elapsed_time = case_when(
elapsed_time < 0 ~ NA_real_,
elapsed_time >= 0 ~ elapsed_time))Once you are done numeric screening, the data is ready for analysis.
27.5 Within Data Entry
If you have a study that involves within-participant predictors naming conventions can become examples. When you have a single repeated measures predictor like occasion in the previous running example, it is often necessary to spread the level of that variable over multiple columns (e.g., march, may, july).
When you have multiple repeated-measures predictors the situation is even more complicated. In this case, each column name needs to represent the levels of multiple repeated measures predictors at the time of data entry. For example, imagine you are a food researcher interested in taste ratings (the dependent variable) for various foods and contexts. You have a predictor, food type (i.e., food_type), with three levels (pizza, steak, burger). You have a second predictor, temperature, with two levels (hot, cold). All participants taste all foods at all temperatures. Thus, six columns are required to record taste rating for each participant: pizza_hot, pizza_cold, steak_hot, steak_cold, burger_hot, and burger_cold. Notice how each name contains one level of each predictor variable. The levels by the two predictor variables are separated by a single underscore. This should be the only underscore in the variable name because that underscore will be used by the computer when changing the data to the tidy format. If you had two underscores in a name like “italian_pizza_hot” you would confuse the pivot_longer() command when it attempts to create a tidy version of the data. The computer would think there were three repeated-measures predictors instead of two. Thus, when dealing with repeated measures predictors, only use underscores to separate levels of predictor variables in column names.
27.6 Experiment: Within one-way
This section outlines a workflow appropriate for when you have a repeated measures design with a single repeated measures predictor. The data corresponds to a design where the researcher is interested in comparing run times (elapsed_time) across three different occasions (march/may/july).
To Begin:
Use the Files tab to confirm you have the data: data_ex_within.csv
Start a new script for this example. Don’t forget to start the script name with “script_”.
# Date: YYYY-MM-DD
# Name: your name here
# Example: Within-participant experiment
# Load data
library(tidyverse)
my_missing_value_codes <- c("-999", "", "NA")
raw_data_within <- read_csv(file = "data_ex_within.csv",
na = my_missing_value_codes)We load the initial data into raw_data_within but immediately make a copy that we will work with called analytic_data_within. It’s good to keep a copy of the raw data for reference if you encounter problems.
After loading the data we do initial cleaning to remove empty row/columns and ensure proper naming for columns:
library(janitor)
# Initial cleaning
analytic_data_within <- analytic_data_within %>%
remove_empty("rows") %>%
remove_empty("cols") %>%
clean_names()You can confirm the column names following our naming convention with the glimpse command - and see the data type for each column.
## Rows: 6
## Columns: 5
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <chr> "male", "female", "male", "female", "male", …
## $ march <dbl> 40, 35, 38, 33, 42, 36
## $ may <dbl> 37, 32, 35, 30, 39, 33
## $ july <dbl> 35, 30, 33, 28, 37, 3127.6.1 Creating factors
Following initial cleaning, we identify categorical variables as factors. If you plan to conduct an ANOVA - it’s critical that all predictor variables are converted to factors. Inspect the glimpse() output - if you followed our data entry naming conventions, categorical variables should be of the type character.
## Rows: 6
## Columns: 5
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <chr> "male", "female", "male", "female", "male", …
## $ march <dbl> 40, 35, 38, 33, 42, 36
## $ may <dbl> 37, 32, 35, 30, 39, 33
## $ july <dbl> 35, 30, 33, 28, 37, 31We have one variable, sex, that is a categorical variable of type character (i.e., chr). The participant id column is categorical as well, but of type double (i.e., dbl) which is a numeric column.
You can quickly convert all character columns to factors using the code below. In this case, this just converts the sex column to a factor. Because there is only one column (sex) being converted to a factor, we could have treated it the same was as the id column below. However, we use this code because of its broad applicability to many scripts.
analytic_data_within <- analytic_data_within %>%
mutate(across(.cols = where(is.character),
.fns = as_factor))The participant identification number in the id column is a numeric column, so it was not converted by the above code. The id column is converted to a factor with the code below.
You can ensure both the sex and id columns are now factors using the glimpse() command.
## Rows: 6
## Columns: 5
## $ id <fct> 1, 2, 3, 4, 5, 6
## $ sex <fct> male, female, male, female, male, female
## $ march <dbl> 40, 35, 38, 33, 42, 36
## $ may <dbl> 37, 32, 35, 30, 39, 33
## $ july <dbl> 35, 30, 33, 28, 37, 31This example is so small it’s clear you didn’t miss converting any columns to factors. In general, however, at this point you should inspect the output of the glimpse() command and make sure you have converted all categorical variables to factors - especially those you will use as predictors.
27.6.2 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels:
## id sex
## 1:1 male :3
## 2:1 female:3
## 3:1
## 4:1
## 5:1
## 6:1The order of the levels influences how graphs are generated. In these data, the sex column has two levels: male and female in that order. The code below adjusts the order of the sex variable because we want the x-axis of a future graph to display columns in the left to right order: female, male.
You can see the new order of the factor levels with summary():
## id sex
## 1:1 female:3
## 2:1 male :3
## 3:1
## 4:1
## 5:1
## 6:127.6.3 Numeric screening
For numeric variables, it is important to find and remove impossible values. For example, in the context of this example you want to ensure none of the elapsed_times are impossible (i.e., negative) or clearly data entry errors.
Because we have several numeric columns that we are screening, we use the skim() command from the skimr package. The skim() command quickly provides basic descriptive statistics. In the output for this command there are also several columns that begin with p: p0, p25, p50, p75, and p100 (p25 and p75 omitted in output due to space). These columns correspond to the 0th, 25th, 50th, 75th, and 100th percentiles, respectively. The minimum and maximum values for the data column are indicated under the p0 and p100 labels. The median is the 50th percentile (p50). The interquartile range is the range between p25 and p75.
## skim_variable n_missing mean sd p0 p50 p100
## 1 march 0 37.33 3.33 33 37 42
## 2 may 0 34.33 3.33 30 34 39
## 3 july 0 32.33 3.33 28 32 37Scan the minimum and maximum values (p0 and p100) to ensure there are not any impossible values. If necessary, go back to the original data source and fix these impossible values. Alternatively, you might need to change them to missing values (i.e., NA values).
In this example all the values are reasonable values. However, if we discovered an out of range value (or values) for elapsed time we could convert those values to missing values with the code below. This code changes (i.e., mutates) a value in the march column to become NA (not available or missing) if that value is less than zero. If the value is greater than or equal to zero, it stays the same. Note that when using this command we have to be very specific in terms of specifying our missing value. It usually needs to be one of NA_real_ or NA_character_. For numeric columns use NA_real_ and for character columns use NA_character_.
27.6.4 Pivot to tidy data
The analytic data in it’s current form does not conform to the tidy data specification. Inspect the data with the print() command. Notice thatthere is not a column for occasion (with levels march/may/july). Instead, there are three columns each of which represents a level of occasion. The levels of occasion are spread across three columns called march, may, and july. Each of these columns contains elapsed time for participants in that month.
## # A tibble: 6 × 5
## id sex march may july
## <fct> <fct> <dbl> <dbl> <dbl>
## 1 1 male 40 37 35
## 2 2 female 35 32 30
## 3 3 male 38 35 33
## 4 4 female 33 30 28
## 5 5 male 42 39 37
## 6 6 female 36 33 31The pivot_longer() command below coverts our data to the tidy data format. In this command we specify the columns march, may, and july are all levels of a single variable called occasion. We specify the columns involved with the cols argument. The code march:july after the cols argument selects the march column, the july column, and all the columns in-between. Each column contains elapsed times at level of the variable occasion. The names_to argument is used to indicate that a new column called occasion should be created to hold the different months. The value_to argument is used to indicate that a new column called elapsed_time should created to hold all the values from the march, may, and july columns.
analytic_data_within_tidy <- analytic_data_within %>%
pivot_longer(cols = march:july,
names_to = "occasion",
values_to = "elapsed_time"
)You can see the data in the new format below.
## # A tibble: 18 × 4
## id sex occasion elapsed_time
## <fct> <fct> <chr> <dbl>
## 1 1 male march 40
## 2 1 male may 37
## 3 1 male july 35
## 4 2 female march 35
## 5 2 female may 32
## 6 2 female july 30
## 7 3 male march 38
## 8 3 male may 35
## 9 3 male july 33
## 10 4 female march 33
## 11 4 female may 30
## 12 4 female july 28
## 13 5 male march 42
## 14 5 male may 39
## 15 5 male july 37
## 16 6 female march 36
## 17 6 female may 33
## 18 6 female july 31Notice that the new column occasion is of the type character. We need it to be a factor. So use the code below to do so:
You can confirm that occasion is now a factor with the glimpse() command. Once this is complete, you are done preparing your one-way within participant analytic data.
## Rows: 18
## Columns: 4
## $ id <fct> 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5…
## $ sex <fct> male, male, male, female, female, fem…
## $ occasion <fct> march, may, july, march, may, july, m…
## $ elapsed_time <dbl> 40, 37, 35, 35, 32, 30, 38, 35, 33, 3…You now have two data sets analytic_data_within and analytic_data_within_tidy. You can calculate descriptive statistics, correlations and general cross-sectional analyses using the analytic_data_within data set. If you want to conduct a repeated measures ANOVA you use the analytic_data_within_tidy data set. Both data sets are now ready for analysis.
27.7 Experiment: Within N-way
This section outlines a workflow appropriate for when you have a repeated measures design with multiple repeated measures predictors. The data corresponds to a design where the researcher is interested in assessing the taste of food as a function of food type (pizza/steak/burger) and temperature (hot/cold).
To Begin:
Use the Files tab to confirm you have the data: data_food.csv
Start a new script for this example. Don’t forget to start the script name with “script_”.
# Date: YYYY-MM-DD
# Name: your name here
# Example: 2-way within-participant experiment
# Load data
library(tidyverse)
my_missing_value_codes <- c("-999", "", "NA")
raw_data_within_nway <- read_csv(file = "data_food.csv",
na = my_missing_value_codes)We load the initial data into raw_data_within_nway but immediately make a copy that we will work with called analytic_data_within_nway. It’s good to keep a copy of the raw data for reference if you encounter problems.
After loading the data we do initial cleaning to remove empty row/columns and ensure proper naming for columns:
library(janitor)
# Initial cleaning
analytic_data_within_nway <- analytic_data_within_nway %>%
remove_empty("rows") %>%
remove_empty("cols") %>%
clean_names()You can confirm the column names following our naming convention with the glimpse command - and see the data type for each column.
## Rows: 6
## Columns: 8
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <dbl> 1, 2, 1, 2, 1, 2
## $ pizza_hot <dbl> 7, 8, 7, 8, 7, 9
## $ pizza_cold <dbl> 6, 7, 5, 7, 6, 7
## $ steak_hot <dbl> 6, 6, 7, 7, 8, 7
## $ steak_cold <dbl> 3, 3, 4, 5, 7, 8
## $ burger_hot <dbl> 7, 8, 7, 8, 7, 8
## $ burger_cold <dbl> 4, 3, 3, 3, 2, 527.7.1 Creating factors
Following initial cleaning, we identify categorical variables as factors. If you plan to conduct an ANOVA - it’s critical that all predictor variables are converted to factors. In this example, there are two categorical variables id and sex, but both are represented numerically. As revealed by the glimpse() output.
## Rows: 6
## Columns: 8
## $ id <dbl> 1, 2, 3, 4, 5, 6
## $ sex <dbl> 1, 2, 1, 2, 1, 2
## $ pizza_hot <dbl> 7, 8, 7, 8, 7, 9
## $ pizza_cold <dbl> 6, 7, 5, 7, 6, 7
## $ steak_hot <dbl> 6, 6, 7, 7, 8, 7
## $ steak_cold <dbl> 3, 3, 4, 5, 7, 8
## $ burger_hot <dbl> 7, 8, 7, 8, 7, 8
## $ burger_cold <dbl> 4, 3, 3, 3, 2, 5We convert both the sex and id columns to factors with the mutate() command below:
analytic_data_within_nway <- analytic_data_within_nway %>%
mutate(id = as_factor(id),
sex = as_factor(sex))The sex column is a factor but we have to tell the computer that 1 indicates male and 2 indicates female.
analytic_data_within_nway <- analytic_data_within_nway %>%
mutate(sex = fct_recode(sex,
male = "1",
female = "2"))You can ensure all of these columns are now factors using the glimpse() command.
## Rows: 6
## Columns: 8
## $ id <fct> 1, 2, 3, 4, 5, 6
## $ sex <fct> male, female, male, female, male, fema…
## $ pizza_hot <dbl> 7, 8, 7, 8, 7, 9
## $ pizza_cold <dbl> 6, 7, 5, 7, 6, 7
## $ steak_hot <dbl> 6, 6, 7, 7, 8, 7
## $ steak_cold <dbl> 3, 3, 4, 5, 7, 8
## $ burger_hot <dbl> 7, 8, 7, 8, 7, 8
## $ burger_cold <dbl> 4, 3, 3, 3, 2, 5Inspect the output of the glimpse() command and make sure you have converted all categorical variables to factors - especially those you will use as predictors. As noted in the previous examples, its common to have additional columns that are categorical predictors but appear in the glimpse() output as being of the type character. That is not the case in these data, but if it were the command below would turn them into factors:
27.7.2 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels:
## id sex
## 1:1 male :3
## 2:1 female:3
## 3:1
## 4:1
## 5:1
## 6:1The order of the levels influences how graphs are generated. In these data, the sex column has two levels: male and female in that order. The code below adjusts the order of the sex variable because we want the x-axis of a future graph to display columns in the left to right order: female, male.
analytic_data_within_nway <- analytic_data_within_nway %>%
mutate(sex = fct_relevel(sex,
"female",
"male"))You can see the new order of the factor levels with summary():
## id sex
## 1:1 female:3
## 2:1 male :3
## 3:1
## 4:1
## 5:1
## 6:127.7.3 Numeric screening
For numeric variables, it’s important find and remove impossible values. For example, in the context of this example you want to ensure none of the taste ratings the six columns (pizza_hot, pizza_cold, steak_hot, steak_cold, burger_hot, and burger_cold) are outside the range of the 1 to 10 rating scale.
Because we have several numeric columns that we are screening, we use the skim() command from the skimr package. The skim() command quickly provides basic descriptive statistics. In the output for this command there are also several columns that begin with p: p0, p25, p50, p75, and p100 (p25 and p75 omitted in output due to space). These columns correspond to the 0th, 25th, 50th, 75th, and 100th percentiles, respectively. The minimum and maximum values for the data column are indicated under the p0 and p100 labels. The median is the 50th percentile (p50). The interquartile range is the range between p25 and p75.
## skim_variable n_missing mean sd p0 p50 p100
## 1 pizza_hot 0 7.67 0.82 7 7.5 9
## 2 pizza_cold 0 6.33 0.82 5 6.5 7
## 3 steak_hot 0 6.83 0.75 6 7.0 8
## 4 steak_cold 0 5.00 2.10 3 4.5 8
## 5 burger_hot 0 7.50 0.55 7 7.5 8
## 6 burger_cold 0 3.33 1.03 2 3.0 5Scan the minimum and maximum values (p0 and p100) to ensure there are not any impossible values. That is, ensure all values are inside the 1 to 10 range for the dependent variable. If necessary, get back to the original data source and fix these impossible values. Alternatively, you might need to change them to missing values (i.e., NA values).
In this example all the values are reasonable values. However, if we discovered an out-of-range value (or values) for elapsed time we could convert those values to missing values with the code below. This code changes (i.e., mutates) a value in the pizza_hot column to become NA (not available or missing) if that value is outside the 1 to 10 range of the rating scale. Note that when using this command we have to be very specific in terms of specifying our missing value. It usually needs to be one of NA_real_ or NA_character_. For numeric columns use NA_real_ and for character columns use NA_character_.
# Values lower than 1 are converted to missing values
analytic_data_within_nway <- analytic_data_within_nway %>%
mutate(pizza_hot = case_when(
pizza_hot < 1 ~ NA_real_,
pizza_hot >= 1 ~ pizza_hot))
# Values greater than 10 are converted to missing values
analytic_data_within_nway <- analytic_data_within_nway %>%
mutate(pizza_hot = case_when(
pizza_hot > 10 ~ NA_real_,
pizza_hot <= 10 ~ pizza_hot))27.7.4 Pivot to tidy data
The analytic data in its current form does not conform to the tidy data specification. Inspect the data with the print() command. Notice that columns do not exist for temperature (with levels hot/cold) or food type (with levels pizza/steak/burger). Instead, there are six columns that are combinations of the levels of these variables (i.e., pizza_hot, pizza_cold, steak_hot, steak_cold, burger_hot, and burger_cold). Each of these columns contains taste ratings on a 1 to 10 point scale.
## # A tibble: 6 × 8
## id sex pizza_hot pizza_cold steak_hot steak_cold
## <fct> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 1 male 7 6 6 3
## 2 2 female 8 7 6 3
## 3 3 male 7 5 7 4
## 4 4 female 8 7 7 5
## 5 5 male 7 6 8 7
## 6 6 female 9 7 7 8
## # ℹ 2 more variables: burger_hot <dbl>, burger_cold <dbl>We need to restructure the data into the tidy data format so that we have a food_type column and a temperature column to properly represent these predictors. As well, we need a column that contains all of the taste ratings that is clearly labeled taste. Doing all of these things will ensure we have one variable per column and one observation per row - consistent with the requirements of tidy data. The pivot_longer() command below coverts our data to the tidy data format.
In this command we specify the columns march, may, and july are all levels of a single variable called occasion. We specify the columns involved with the cols argument. The code pizza_hot:burger_cold after the cols argument selects the pizza_hot column, the burger_cold column, and all the columns in between. Each column contains taste ratings at a combination of the levels for the variables food_type and temperature. The names_to argument is used to indicate that two new columns should be created to represent food and temperature. Notice the order food then temperature. This is consistent with our naming convention; in the column name pizza_hot the food_type is specified before temperature. The value_to argument is used to indicate that a new column called taste should created to hold all the values from the pizza_hot, pizza_cold, steak_hot, steak_cold, burger_hot, and burger_cold columns.
analytic_data_nway_tidy <- analytic_data_within_nway %>%
pivot_longer(cols = pizza_hot:burger_cold,
names_to = c("food_type", "temperature"),
names_sep = "_",
values_to = "taste"
)You can see the data in the new format below.
## # A tibble: 36 × 5
## id sex food_type temperature taste
## <fct> <fct> <chr> <chr> <dbl>
## 1 1 male pizza hot 7
## 2 1 male pizza cold 6
## 3 1 male steak hot 6
## 4 1 male steak cold 3
## 5 1 male burger hot 7
## 6 1 male burger cold 4
## 7 2 female pizza hot 8
## 8 2 female pizza cold 7
## 9 2 female steak hot 6
## 10 2 female steak cold 3
## # ℹ 26 more rowsNotice that the new column occasion is of the type character. We need it to be a factor. Use the code below to do so:
analytic_data_nway_tidy <- analytic_data_nway_tidy %>%
mutate(food = as_factor(food_type),
temperature = as_factor(temperature))You can confirm that occasion is now a factor with the glimpse() command. Once this is complete, you are done preparing your one-way within participant analytic data.
## Rows: 36
## Columns: 6
## $ id <fct> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3,…
## $ sex <fct> male, male, male, male, male, male, fe…
## $ food_type <chr> "pizza", "pizza", "steak", "steak", "b…
## $ temperature <fct> hot, cold, hot, cold, hot, cold, hot, …
## $ taste <dbl> 7, 6, 6, 3, 7, 4, 8, 7, 6, 3, 8, 3, 7,…
## $ food <fct> pizza, pizza, steak, steak, burger, bu…You now have two data sets analytic_data_within_nway and analytic_data_nway_tidy. You can calculate descriptive statistics, correlations and general cross-sectional analyses using the analytic_data_within_nway data set. If you want to conduct a repeated measures ANOVA you use the analytic_data_nway_tidy data set. Both data sets are now ready for analysis.
27.8 Surveys: Single Occassion
This section outlines a workflow appropriate for when you have cross-sectional single occasion survey data. The data corresponds to a design where the researcher has measured, age, sex, eye color, self-esteem, and job satisfaction. Two of these, self-esteem and job satisfaction, were measured with multi-item scales with reverse-keyed items.
To Begin:
Use the Files tab to confirm you have the data: data_item_scoring.csv
Start a new script for this example. Don’t forget to start the script name with “script_”.
# Date: YYYY-MM-DD
# Name: your name here
# Example: Single occasion survey
# Load data
library(tidyverse)
my_missing_value_codes <- c("-999", "", "NA")
raw_data_survey <- read_csv(file = "data_item_scoring.csv",
na = my_missing_value_codes)We load the initial data into a raw_data_survey but immediately make a copy we will work with called analytic_data_survey. It’s good to keep a copy of the raw data for reference if you encounter problems.
Remove empty row and columns from your data using the remove_empty_cols() and remove_empty_rows(), respectively. As well, clean the names of your columns to ensure they conform to tidyverse naming conventions.
library(janitor)
# Initial cleaning
analytic_data_survey <- analytic_data_survey %>%
remove_empty("rows") %>%
remove_empty("cols") %>%
clean_names()You can confirm the column names following our naming convention with the glimpse command - and see the data type for each column.
## Rows: 300
## Columns: 14
## $ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22,…
## $ sex <chr> "male", "female", "male", "fema…
## $ eye_color <chr> "blue", "brown", "hazel", "blue…
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, N…
## $ esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2, 2,…
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3…
## $ jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2, 2, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4,…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, …27.8.1 Creating factors
Following initial cleaning, we identify categorical variables as factors. If you plan to conduct an ANOVA - it’s critical that all predictor variables are converted to factors. Inspect the glimpse() output - if you followed our data entry naming conventions, categorical variables should be of the type character.
## Rows: 300
## Columns: 14
## $ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22,…
## $ sex <chr> "male", "female", "male", "fema…
## $ eye_color <chr> "blue", "brown", "hazel", "blue…
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, N…
## $ esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2, 2,…
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3…
## $ jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2, 2, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4,…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, …We have two variables, sex and eye_color, that are categorical variable of type character (i.e., chr). The participant id column is categorical as well, but of type double (i.e., dbl) which is a numeric column. You can quickly convert all character columns to factors using the code below:
analytic_data_survey <- analytic_data_survey %>%
mutate(across(.cols = where(is.character),
.fns = as_factor))The participant identification number in the id column is a numeric column, so we have to handle that column on its own.
You can ensure all of these columns are now factors using the glimpse() command.
## Rows: 300
## Columns: 14
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22,…
## $ sex <fct> male, female, male, female, mal…
## $ eye_color <fct> blue, brown, hazel, blue, NA, h…
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, N…
## $ esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2, 2,…
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3…
## $ jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2, 2, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4,…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, …Inspect the output of the glimpse() command and make sure you have converted all categorical variables to factors - especially those you will use as predictors.
Note: f you have factors like sex that have numeric data in the column (e.g, 1 and 2) instead of male/female you need to handle the situation differently. The preceding section, Experiment: Within N-way, illustrates how to handle this scenario.
27.8.2 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels:
## id sex eye_color
## 1 : 1 male :147 blue : 99
## 2 : 1 female :149 brown: 98
## 3 : 1 intersex: 2 hazel:100
## 4 : 1 NAs : 2 NAs : 3
## 5 : 1
## 6 : 1
## (Other):294Also inspect the output of the above summary() command paying attention to the order of the levels in the factors. The order influences how text output and graphs are generated. In these data, the sex column has two levels: male and female in that order. Below we adjust the order of the sex variable because we want the x-axis of a future graph to display columns in the left to right order: female, male.
analytic_data_survey <- analytic_data_survey %>%
mutate(sex = fct_relevel(sex,
"intersex",
"female",
"male"))For eye color, we want a future graph to have the most common eye colors on the left so we reorder the factor levels:
You can see the new order of the factor levels with summary():
## id sex eye_color
## 1 : 1 intersex: 2 hazel:100
## 2 : 1 female :149 blue : 99
## 3 : 1 male :147 brown: 98
## 4 : 1 NAs : 2 NAs : 3
## 5 : 1
## 6 : 1
## (Other):29427.8.3 Numeric screening
For numeric variables, it’s important to find and remove impossible values. For example, in the context of this example you want to ensure none of the Likert responses are impossible (e.g., outside the 1- to 5-point rating scale) or clearly data entry errors.
Because we have several numeric columns that we are screening, we use the skim() command from the skimr package. The skim() command quickly provides basic descriptive statistics. In the output for this command there are also several columns that begin with p: p0, p25, p50, p75, and p100 (p25 and p75 omitted in output due to space). These columns correspond to the 0th, 25th, 50th, 75th, and 100th percentiles, respectively. The minimum and maximum values for the data column are indicated under the p0 and p100 labels. The median is the 50th percentile (p50). The interquartile range is the range between p25 and p75.
Start by examining the range of non-scale items. In this case it’s only age. Examine the output to see if any of the age values are unreasonable. As noted, in the output p0 and p100 indicate the 0th percentile and the 100th percentile; that is the minimum and maximum values for the variable. Check to make sure none of the age values are unreasonably low or high. If they are, you may need to check the original data source or replace them with missing values.
## skim_variable n_missing mean sd p0 p50 p100
## 1 age 3 20.52 2.05 17 20 24With respect to the multi-item scales, it makes sense to look at sets of items rather than all of the items at once. This is because sometimes items from different scales use different response ranges. For example, one measure might use a response scale with a range from 1 to 5; whereas another measure might use a response scale with a range from 1 to 7. This is undesirable from a psychometric point of view, as discussed previously, but if it happens in your data - look at the scale items separately to make it easy to see out of range values.
We begin by looking at the items in the first scale, self-esteem. Possible items responses for this scale range from 1 to 5; make sure all responses are in this range. If any values fall outside this range, you may need to check the original data source or replace them with missing values - as described previously.
## skim_variable n_missing mean sd p0 p50 p100
## 1 esteem1_likert5 24 3.39 0.54 3 3 5
## 2 esteem2_likert5 28 2.35 0.48 2 2 3
## 3 esteem3_likert5 31 3.96 0.37 3 4 5
## 4 esteem4_likert5 15 3.54 0.50 3 4 4
## 5 esteem5_likert5rev 35 2.22 0.47 1 2 3Follow the same process for the job satisfaction items. Write that code on your own now.
Possible item responses for the job satisfaction scale range from 1 to 5, make sure all responses are in this range. If any values fall outside this range, you may need to check the original data source or replace them with missing values - as described previously.
## skim_variable n_missing mean sd p0 p50 p100
## 1 jobsat1_likert5 25 3.34 0.51 3 3 5
## 2 jobsat2_likert5rev 27 1.51 0.61 1 1 3
## 3 jobsat3_likert5 28 2.84 0.37 2 3 3
## 4 jobsat4_likert5 35 4.29 0.70 3 4 5
## 5 jobsat5_likert5 24 4.57 0.61 3 5 527.8.4 Scale scores
For each person, scale scores involve averaging scores from several items to create an overall score. The first step in the creation of scales is correcting the values of any reverse-keyed items.
27.8.4.1 Reverse-key items
The way you deal with reverse-keyed items depends on how you scored them. Imagine you had a 5-point scale. You could have scored the scale with the values 1, 2, 3, 4, and 5. Alternatively, you could have scored the scale with the values 0, 1, 2, 3, and 4. The mathematical approach you use to correcting reverse-keyed items depends upon whether the scale starts with 1 or 0.
In this example, we scored the data using the value 1 to 5; so that is the approach illustrated here. See the extra information box for details on how to fixed reverse-keyed items when the scale begins with zero.
In this data file all the reverse-keyed items were identified with the suffix “_likert5rev” in the column names. This suffix indicates the item was reverse keyed and that the original scale used the response points 1 to 5. We can see those items with the glimpse() command below. Notice that there are two reverse-keyed items - each on difference scales.
## Rows: 300
## Columns: 2
## $ esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2, 2,…
## $ jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2, 2, …To correct a reverse-keyed item where the lowest possible rating is 1 (i.e, 1 on a 1 to 5 scale), we simply subtract all the scores from a value one more than the highest point possible on the scale (i.e., one more than 5). For example, if a 1 to 5 response scale was used we subtract each response from 6 to obtain the recoded value.
| Original value | Math | Recoded value |
|---|---|---|
| 1 | 6 - 1 | 5 |
| 2 | 6 - 2 | 4 |
| 3 | 6 - 3 | 3 |
| 4 | 6 - 4 | 2 |
| 5 | 6 - 5 | 1 |
The code below:
- selects columns that end with “_likert5rev” (i.e., both esteem and jobsat scales)
- subtracts the values in those columns from 6
- renames the columns by removing “_likert5rev” from the name because the reverse coding is complete
analytic_data_survey <- analytic_data_survey %>%
mutate(6 - across(.cols = ends_with("_likert5rev")) ) %>%
rename_with(.fn = str_replace,
.cols = ends_with("_likert5rev"),
pattern = "_likert5rev",
replacement = "_likert5")You can use the glimpse() command to see the result of your work. If you compare these new values to those obtained from the previous glimpse() command you can see they have changed. Also notice the column names no longer indicate the items are reverse keyed.
## Rows: 300
## Columns: 14
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,…
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22, 17…
## $ sex <fct> male, female, male, female, male, …
## $ eye_color <fct> blue, brown, hazel, blue, NA, haze…
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3, 4…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, 4, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, NA, …
## $ esteem5_likert5 <dbl> 4, 4, 4, 4, 4, NA, NA, 4, 4, 4, 3,…
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3, 4…
## $ jobsat2_likert5 <dbl> 5, 5, 5, NA, 5, 5, 4, 5, 4, 4, 3, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4, NA…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, 4, …If your scale had used response options numbered 0 to 4 the math is different. For each item you would use subtract values from the highest possible point (i.e, 4) instead of one larger than the highest possible point.
| Original value | Math | Recoded value |
|---|---|---|
| 0 | 4 - 0 | 4 |
| 1 | 4 - 1 | 3 |
| 2 | 4 - 2 | 2 |
| 3 | 4 - 3 | 1 |
| 4 | 4 - 4 | 0 |
Thus, the mutate command would instead be:
mutate(4 - across(.cols = ends_with(“_likert5rev”)) )27.8.4.2 Creating scores
The process we use for creating scale scores deletes item-level data from analytic_data_survey. This is a desirable aspect of the process because it removes information that we are no longer interested in from our analytic data. That said, before we create scale score, we create a backup on the item-level data called analytic_data_survey_items. We will need to use this backup later to compute the reliability of the scales we are creating.
We want to make a self_esteem scale and plan to select items using starts_with(“esteem”). But prior to doing this we make sure the start_with() command only gives us the items we want - and not additional unwanted items. The output below confirms there are not problems associated with using starts_with(“esteem”).
## Rows: 300
## Columns: 5
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3, 4…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, 4, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, NA, …
## $ esteem5_likert5 <dbl> 4, 4, 4, 4, 4, NA, NA, 4, 4, 4, 3,…Likewise, we want to make a job_sat scale and plan to select items using starts_with(“jobsat”). The code and output below using starts_with(“jobsat”) only returns the items we are interested in.
## Rows: 300
## Columns: 5
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3, 4…
## $ jobsat2_likert5 <dbl> 5, 5, 5, NA, 5, 5, 4, 5, 4, 4, 3, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4, NA…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, 4, …We calculate the scale scores using the rowwise() command. The mean() command provides the mean of columns by default - not people. We use the rowwise() command in the code below to make the mean() command work across columns (within participants) rather than within columns. The mutate command calculates the scale score for each person. The c_across() command combined with the starts_with() command ensures the items we want averaged together are the items that are averaged together. Notice there is a separate mutate line for each scale. The ungroup() command turns off the rowwise() command. We end the code block by removing the item-level data from the data set.
Important: Take note of how we name the scale variables (e.g., self_esteem, job_sat). We use a slightly different convention than our items. That is, these scale labels were picked so that they would not be selected by a starts_with(“esteem”) or starts_with(“jobsat”). Why - because we later use those commands to remove the item-level data. We would want the command designed to remove the item-level data to also remove the scale we just calculated! This example illustrates how carefully you need to think about your naming conventions.
analytic_data_survey <- analytic_data_survey %>%
rowwise() %>%
mutate(self_esteem = mean(c_across(starts_with("esteem")),
na.rm = TRUE)) %>%
mutate(job_sat = mean(c_across(starts_with("jobsat")),
na.rm = TRUE)) %>%
ungroup() %>%
select(-starts_with("esteem")) %>%
select(-starts_with("jobsat")) We can see our data now has the self_esteem column, a job_sat column, and that all of the item-level data has been removed.
## Rows: 300
## Columns: 6
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,…
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22, 17, NA…
## $ sex <fct> male, female, male, female, male, fema…
## $ eye_color <fct> blue, brown, hazel, blue, NA, hazel, b…
## $ self_esteem <dbl> 3.200, 3.800, 3.800, 3.000, 3.400, 3.5…
## $ job_sat <dbl> 4.00, 5.00, 4.40, 3.50, 4.00, 3.80, 3.…You now have two data sets analytic_data_survey and analytic_data_survey_items. You can calculate descriptive statistics, correlations and most analyses using the analytic_data_survey. To obtain the reliability of the scales you just created though you will need to use the analytic_data_survey_items. Both sets of data are ready for analysis.
27.9 Surveys: Multiple Occasions
This section outlines a workflow appropriate for when you have multiple occasion survey data. The data corresponds to a design where the researcher has measured, age, sex, eye color, self-esteem, and job satisfaction at each of two times points. Self-esteem and job satisfaction were measured with multi-item scales with reverse-keyed items.
To Begin:
Use the Files tab to confirm you have the data: data_item_time.csv
Start a new script for this example. Don’t forget to start the script name with “script_”.
# Date: YYYY-MM-DD
# Name: your name here
# Example: Multiple occasion survey
# Load data
library(tidyverse)
my_missing_value_codes <- c("-999", "", "NA")
raw_data_occasions <- read_csv(file = "data_item_time.csv",
na = my_missing_value_codes)We load the initial data into a raw_data_occasions but immediately make a copy we will work with called analytic_data_occasions. It’s good to keep a copy of the raw data for reference if you encounter problems.
Remove empty rows and columns from your data using the remove_empty(“rows”) and remove_empty(“cols”), respectively. As well, clean the names of your columns to ensure they conform to tidyverse naming conventions.
library(janitor)
# Initial cleaning
analytic_data_occasions <- analytic_data_occasions %>%
remove_empty("rows") %>%
remove_empty("cols") %>%
clean_names()You can confirm the column names following our naming convention with the glimpse command - and see the data type for each column.
## Rows: 300
## Columns: 24
## $ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23,…
## $ sex <chr> "male", "female", "male", "…
## $ eye_color <chr> "blue", "brown", "hazel", "…
## $ t1_esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, …
## $ t1_esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, …
## $ t1_esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4,…
## $ t1_esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, …
## $ t1_esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2…
## $ t1_jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, …
## $ t1_jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2,…
## $ t1_jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3,…
## $ t1_jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA…
## $ t1_jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5,…
## $ t2_esteem1_likert5 <dbl> 4, 5, 5, 4, NA, 4, 4, 5, 5,…
## $ t2_esteem2_likert5 <dbl> 3, 4, 4, 3, 3, 4, 3, 4, 4, …
## $ t2_esteem3_likert5 <dbl> 5, 5, 5, 4, 5, 5, 3, 5, 5, …
## $ t2_esteem4_likert5 <dbl> 4, 5, 5, 4, 5, 5, 5, 5, 4, …
## $ t2_esteem5_likert5rev <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ t2_jobsat1_likert5 <dbl> 4, 6, 5, 4, 4, 4, 4, 6, 4, …
## $ t2_jobsat2_likert5rev5 <dbl> 2, 2, 2, 3, 2, 2, 3, 2, 3, …
## $ t2_jobsat3_likert5 <dbl> 4, 3, 4, 4, 4, 4, 4, 4, 4, …
## $ t2_jobsat4_likert5 <dbl> 3, 6, 6, 5, 5, 5, 5, 6, 3, …
## $ t2_jobsat5_likert5 <dbl> 6, 3, 6, 5, NA, 5, 5, 6, 6,…27.9.1 Creating factors
Following initial cleaning, we identify categorical variables as factors. If you plan to conduct an ANOVA - it’s critical that all predictor variables are converted to factors. Inspect the glimpse() output - if you followed our data entry naming conventions, categorical variables should be of the type character.
## Rows: 300
## Columns: 24
## $ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23,…
## $ sex <chr> "male", "female", "male", "…
## $ eye_color <chr> "blue", "brown", "hazel", "…
## $ t1_esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, …
## $ t1_esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, …
## $ t1_esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4,…
## $ t1_esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, …
## $ t1_esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2…
## $ t1_jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, …
## $ t1_jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2,…
## $ t1_jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3,…
## $ t1_jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA…
## $ t1_jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5,…
## $ t2_esteem1_likert5 <dbl> 4, 5, 5, 4, NA, 4, 4, 5, 5,…
## $ t2_esteem2_likert5 <dbl> 3, 4, 4, 3, 3, 4, 3, 4, 4, …
## $ t2_esteem3_likert5 <dbl> 5, 5, 5, 4, 5, 5, 3, 5, 5, …
## $ t2_esteem4_likert5 <dbl> 4, 5, 5, 4, 5, 5, 5, 5, 4, …
## $ t2_esteem5_likert5rev <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ t2_jobsat1_likert5 <dbl> 4, 6, 5, 4, 4, 4, 4, 6, 4, …
## $ t2_jobsat2_likert5rev5 <dbl> 2, 2, 2, 3, 2, 2, 3, 2, 3, …
## $ t2_jobsat3_likert5 <dbl> 4, 3, 4, 4, 4, 4, 4, 4, 4, …
## $ t2_jobsat4_likert5 <dbl> 3, 6, 6, 5, 5, 5, 5, 6, 3, …
## $ t2_jobsat5_likert5 <dbl> 6, 3, 6, 5, NA, 5, 5, 6, 6,…We have two variables, sex and eye_color, that are categorical variable of type character (i.e., chr). The participant id column is categorical as well, but of type double (i.e., dbl) which is a numeric column. You can quickly convert all character columns to factors using the code below:
analytic_data_occasions <- analytic_data_occasions %>%
mutate(across(.cols = where(is.character),
.fns = as_factor))The participant identification number in the id column is numeric, so we have to handle that column on its own.
You can ensure all of these columns are now factors using the glimpse() command.
## Rows: 300
## Columns: 24
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23,…
## $ sex <fct> male, female, male, female,…
## $ eye_color <fct> blue, brown, hazel, blue, N…
## $ t1_esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, …
## $ t1_esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, …
## $ t1_esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4,…
## $ t1_esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, …
## $ t1_esteem5_likert5rev <dbl> 2, 2, 2, 2, 2, NA, NA, 2, 2…
## $ t1_jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, …
## $ t1_jobsat2_likert5rev <dbl> 1, 1, 1, NA, 1, 1, 2, 1, 2,…
## $ t1_jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3,…
## $ t1_jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA…
## $ t1_jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5,…
## $ t2_esteem1_likert5 <dbl> 4, 5, 5, 4, NA, 4, 4, 5, 5,…
## $ t2_esteem2_likert5 <dbl> 3, 4, 4, 3, 3, 4, 3, 4, 4, …
## $ t2_esteem3_likert5 <dbl> 5, 5, 5, 4, 5, 5, 3, 5, 5, …
## $ t2_esteem4_likert5 <dbl> 4, 5, 5, 4, 5, 5, 5, 5, 4, …
## $ t2_esteem5_likert5rev <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ t2_jobsat1_likert5 <dbl> 4, 6, 5, 4, 4, 4, 4, 6, 4, …
## $ t2_jobsat2_likert5rev5 <dbl> 2, 2, 2, 3, 2, 2, 3, 2, 3, …
## $ t2_jobsat3_likert5 <dbl> 4, 3, 4, 4, 4, 4, 4, 4, 4, …
## $ t2_jobsat4_likert5 <dbl> 3, 6, 6, 5, 5, 5, 5, 6, 3, …
## $ t2_jobsat5_likert5 <dbl> 6, 3, 6, 5, NA, 5, 5, 6, 6,…Inspect the output of the glimpse() command and make sure you have converted all categorical variables to factors - especially those you will use as predictors.
Note: If you have factors like sex that have numeric data in the column (e.g, 1 and 2) instead of male/female you need to handle the situation differently. The preceding section, Experiment: Within N-way, illustrates how to handle this scenario.
27.9.2 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels:
## id sex eye_color
## 1 : 1 male :147 blue : 99
## 2 : 1 female :149 brown: 98
## 3 : 1 intersex: 2 hazel:100
## 4 : 1 NAs : 2 NAs : 3
## 5 : 1
## 6 : 1
## (Other):294Also inspect the output of the above summary() command paying attention to the order of the levels in the factors. The order influences how text output and graphs are generated. In these data, the sex column has two levels: male and female in that order. Below we adjust the order of the sex variable because we want the x-axis of a future graph to display columns in the left to right order: female, male.
analytic_data_occasions <- analytic_data_occasions %>%
mutate(sex = fct_relevel(sex,
"intersex",
"female",
"male"))For eye color, we want a future graph to have the most common eye colors on the left so we reorder the factor levels:
You can see the new order of the factor levels with summary():
## id sex eye_color
## 1 : 1 intersex: 2 hazel:100
## 2 : 1 female :149 blue : 99
## 3 : 1 male :147 brown: 98
## 4 : 1 NAs : 2 NAs : 3
## 5 : 1
## 6 : 1
## (Other):29427.9.3 Numeric screening
For numeric variables, it’s important to find and remove impossible values. For example, in the context of this example you want to ensure none of the Likert responses are impossible (e.g., outside the 1- to 5-point rating scale) or clearly data entry errors.
Because we have several numeric columns that we are screening, we use the skim() command from the skimr package. The skim() command quickly provides basic descriptive statistics. In the output for this command there are also several columns that begin with p: p0, p25, p50, p75, and p100 (p25 and p75 are omitted in output due to space). These columns correspond to the 0th, 25th, 50th, 75th, and 100th percentiles, respectively. The minimum and maximum values for the data column are indicated under the p0 and p100 labels. The median is the 50th percentile (p50). The interquartile range is the range between p25 and p75.
Start by examining the range of non-scale items. In this case it’s only age. Examine the output to see if any of the age values are unreasonable. As noted, p0 and p100 in the output indicate the 0th percentile and the 100th percentile; that is the minimum and maximum values for the variable. Check to make sure none of the age values are unreasonably low or high. If they are, you may need to check the original data source or replace them with missing values.
## skim_variable n_missing mean sd p0 p50 p100
## 1 age 3 20.52 2.05 17 20 24With respect to the multi-item scales, it makes sense to look at sets of items rather than all of the items at once. This is because sometimes items from different scales use different response ranges. For example, one measure might use a response scale with a range from 1 to 5; whereas another measure might use a response scale with a range from 1 to 7. This is undesirable from a psychometric point of view, as discussed previously, but if it happens in your data - look at the scale items separately to make it easy to see out of range values.
We begin by looking at the items in the first scale, self-esteem. Possible item responses for this scale range from 1 to 5. Make sure all responses are in this range. If any values fall outside this range, you may need to check the original data source or replace them with missing values - as described previously.
Because we want to select the self-esteem items from both time 1 and time 2 we cannot use the starts_with() command. Instead we use the contains() command in the code below.
## skim_variable n_missing mean sd p0 p50 p100
## 1 t1_esteem1_likert5 24 3.39 0.54 3 3 5
## 2 t1_esteem2_likert5 28 2.35 0.48 2 2 3
## 3 t1_esteem3_likert5 31 3.96 0.37 3 4 5
## 4 t1_esteem4_likert5 15 3.54 0.50 3 4 4
## 5 t1_esteem5_likert5rev 35 2.22 0.47 1 2 3
## 6 t2_esteem1_likert5 5 4.27 0.64 3 4 6
## 7 t2_esteem2_likert5 5 3.33 0.47 3 3 4
## 8 t2_esteem3_likert5 6 4.77 0.69 3 5 6
## 9 t2_esteem4_likert5 3 4.46 0.59 3 5 5
## 10 t2_esteem5_likert5rev 4 3.19 0.45 2 3 4Follow the same process for the job satisfaction items. Possible item responses for the job satisfaction scale range from 1 to 5, make sure all responses are in this range. If any values fall outside this range, you may need to check the original data source or replace them with missing values - as described previously.
## skim_variable n_missing mean sd p0 p50 p100
## 1 t1_jobsat1_likert5 25 3.34 0.51 3 3 5
## 2 t1_jobsat2_likert5rev 27 1.51 0.61 1 1 3
## 3 t1_jobsat3_likert5 28 2.84 0.37 2 3 3
## 4 t1_jobsat4_likert5 35 4.29 0.70 3 4 5
## 5 t1_jobsat5_likert5 24 4.57 0.61 3 5 5
## 6 t2_jobsat1_likert5 2 4.23 0.62 3 4 6
## 7 t2_jobsat2_likert5rev5 3 2.54 0.59 2 2 4
## 8 t2_jobsat3_likert5 5 3.76 0.43 3 4 4
## 9 t2_jobsat4_likert5 3 5.03 0.99 3 5 6
## 10 t2_jobsat5_likert5 3 5.36 0.92 3 6 627.9.4 Scale scores
For each person, scale scores involve averaging scores from several items to create an overall score. The first step in the creation of scales is correcting the values of any reverse-keyed items.
27.9.4.1 Reverse-key items
The way you deal with reverse-keyed items depends on how you scored them. Imagine you had a 5-point scale. You could have scored the scale with the values 1, 2, 3, 4, and 5. Alternatively, you could have scored the scale with the values 0, 1, 2, 3, and 4. The mathematical approach you use to correcting reverse-keyed items depends upon whether the scale starts with 1 or 0.
In this example, we scored the Likert items using the values 1 to 5. Therefore, we use the reverse keying approach for scales that being with 1. The preceding section, “Surveys: Single occasion”, describes how the math differs when the response scale starts with 0. We encourage you to read that section before going further if you have not done so already.
In this data file all the reverse-keyed items were identified with the suffix “_likert5rev” in the column names. This suffix indicates the item was reverse keyed and that the original scale used the response points 1 to 5. We can see those items with the glimpse() command below. Notice that there are two reverse-keyed items - each on difference scales.
## Rows: 300
## Columns: 0To correct reverse-keyed items where the lowest possible rating is 1 (i.e, 1 on a 1 to 5 scale), we simply subtract all the scores from a value one more than the highest possible rating (i.e., 6).
The code below:
- selects columns that end with “_likert5rev” (i.e., both esteem and jobsat scales)
- subtracts the values in those columns from 6
- renames the columns by removing “_likert5rev” from the name because the reverse coding is complete
analytic_data_occasions <- analytic_data_occasions %>%
mutate(6 - across(.cols = ends_with("_likert5rev")) ) %>%
rename_with(.fn = str_replace,
.cols = ends_with("_likert5rev"),
pattern = "_likert5rev",
replacement = "_likert5")You can use the glimpse() command to see the result of your work. If you compare these new values to those obtained from the previous glimpse() command you can see they have changed. Also notice the column names no longer indicate the items are reverse keyed.
27.9.4.2 Creating scores
The process we use for creating scale scores deletes item-level data from analytic_data_survey. This is a desirable aspect of the process because it removes information we no longer need. That said, before we create scale scores, we create a backup on the item-level data in analytic_data_survey called analytic_data_survey_items. We will need to use this backup later to compute the reliability of the scales we are creating.
We want to make a self_esteem scale and plan to select items using starts_with(“t1_esteem”). Prior to doing this we make sure the start_with() command only gives us the items we want - and not additional unwanted items. The output below confirms there are not problems associated with using starts_with(“t1_esteem”).
## Rows: 300
## Columns: 5
## $ t1_esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3…
## $ t1_esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2…
## $ t1_esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, …
## $ t1_esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, N…
## $ t1_esteem5_likert5 <dbl> 4, 4, 4, 4, 4, NA, NA, 4, 4, 4,…Repeat this set of commands using t2_esteem, t1_jobsat, and t2_jobsat. Make sure that those start_with() terms select only the relevant items and not others.
We calculate the scale scores using the rowwise() command. The mean() command provides the mean of columns by default - not people. We use the rowwise() command in the code below to make the mean() command work across columns (within participants) rather than within columns. The mutate command calculates the scale score for each person. The c_across() command combined with the starts_with() command ensures the items we want averaged together are the items that are averaged together. Notice that there is a separate mutate line for each scale. The ungroup() command turns off the rowwise() command. We end the code block by removing the item-level data from the data set.
Important: Take note of how the names of the scale variables (e.g., esteem_t1, jobsat_t1) use a slightly different convention than our items. That is, these scale labels were picked so that they would not be selected by a starts_with(“t1_esteem”) or starts_with(“t1_jobsat”). Why - because we later use those commands to remove the item-level data. We would want the command designed to remove the item-level data to also remove the scale we just calculated! This example illustrates how carefully you need to think about your naming conventions.
analytic_data_occasions <- analytic_data_occasions %>%
rowwise() %>%
mutate(esteem_t1 = mean(c_across(starts_with("t1_esteem")),
na.rm = TRUE)) %>%
mutate(esteem_t2 = mean(c_across(starts_with("t2_esteem")),
na.rm = TRUE)) %>%
mutate(jobsat_t1 = mean(c_across(starts_with("t1_jobsat")),
na.rm = TRUE)) %>%
mutate(jobsat_t2 = mean(c_across(starts_with("t2_jobsat")),
na.rm = TRUE)) %>%
ungroup() %>%
select(-starts_with("t1_esteem")) %>%
select(-starts_with("t2_esteem")) %>%
select(-starts_with("t1_jobsat")) %>%
select(-starts_with("t2_jobsat"))We can see our data now has the columns t1_esteem, t2_esteem, t1_jobsat, and t2_jobsat. As well, we can see that all of the item-level data has been removed from the data set.
## Rows: 300
## Columns: 8
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1…
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22, 17, NA, …
## $ sex <fct> male, female, male, female, male, female…
## $ eye_color <fct> blue, brown, hazel, blue, NA, hazel, blu…
## $ esteem_t1 <dbl> 3.200, 3.800, 3.800, 3.000, 3.400, 3.500…
## $ esteem_t2 <dbl> 3.8, 4.4, 4.4, 3.6, 4.0, 4.2, 3.6, 4.4, …
## $ jobsat_t1 <dbl> 4.00, 5.00, 4.40, 3.50, 4.00, 3.80, 3.60…
## $ jobsat_t2 <dbl> 3.80, 4.00, 4.60, 4.20, 3.75, 4.00, 4.20…27.9.5 Pivot to tidy data
The analytic data in its current form does not conform to the tidy data specification. Inspect the data with the print() command. Notice that a single column is not used to represent esteem, jobsat, or time. Rather, there are four columns that are a mix of these variables. The consequence of this is that there are two esteem ratings/observations on each row and two jobsat ratings/observations on each row. Tidy data is structured so that each variable is represented in a single column and each observation has its own row.
## # A tibble: 300 × 8
## id age sex eye_color esteem_t1 esteem_t2 jobsat_t1
## <fct> <dbl> <fct> <fct> <dbl> <dbl> <dbl>
## 1 1 23 male blue 3.2 3.8 4
## 2 2 22 fema… brown 3.8 4.4 5
## 3 3 18 male hazel 3.8 4.4 4.4
## 4 4 23 fema… blue 3 3.6 3.5
## 5 5 22 male <NA> 3.4 4 4
## 6 6 17 fema… hazel 3.5 4.2 3.8
## 7 7 23 male blue 3 3.6 3.6
## 8 8 22 fema… brown 3.8 4.4 4.6
## 9 9 17 male hazel 3.6 4.2 3.75
## 10 10 NA fema… blue 3.6 4.2 3.8
## # ℹ 290 more rows
## # ℹ 1 more variable: jobsat_t2 <dbl>The pivot_longer() command below coverts our data to the tidy data format. In this command we specify the columns with data by using esteem_t1:jobsat_t2; this selects these two columns and all of the columns between them. Each of these columns represents a dependent variable at a particular time in the format “variable_time” (e.g., esteem_t1). The code names_to = c(“.value”, “time”) explains this format to R. It indicates that the first part of the column name (e.g., esteem) contains the name of the variable (expressed in the code as “.value”). It also indicates that the second part of the column name represents time. The line names_sep = “_” tells the R that the underscore character is used to separate the first part of the name from the second part of the name. When this code is executed it creates a tidy version of data set stored in analytic_survey_tidy.
analytic_occasion_tidy <- analytic_data_occasions %>%
pivot_longer(esteem_t1:jobsat_t2,
names_to = c(".value", "time"),
names_sep = "_")You can see the new data with the print() command. Notice that each participant has multiple rows associated with them.
## # A tibble: 600 × 7
## id age sex eye_color time esteem jobsat
## <fct> <dbl> <fct> <fct> <chr> <dbl> <dbl>
## 1 1 23 male blue t1 3.2 4
## 2 1 23 male blue t2 3.8 3.8
## 3 2 22 female brown t1 3.8 5
## 4 2 22 female brown t2 4.4 4
## 5 3 18 male hazel t1 3.8 4.4
## 6 3 18 male hazel t2 4.4 4.6
## 7 4 23 female blue t1 3 3.5
## 8 4 23 female blue t2 3.6 4.2
## 9 5 22 male <NA> t1 3.4 4
## 10 5 22 male <NA> t2 4 3.75
## # ℹ 590 more rowsYou now have three data sets The data analytic_occasion_tidy is appropriate for conducting a repeated measures ANOVA or more complicated analyses. The data analytic_data_occasions is appropriate for calculating descriptive statistics and correlations. The data analytic_occasions_items is appropriate for calculating the reliability of the scales you constructed. These data are ready for analysis.
27.10 Basic descriptive statistics
Regardless of the design of the study, most researchers want to see descriptive statistics for the variables in their study. We offer three approaches for obtaining descriptive statistics below. For convenience we use the recent data set analytic_data_occasions. But recognize the commands below can be used with all the analytic data sets we created for the various designs.
27.10.1 skim()
One approach is the skim() command from the skimr package. The skim() command quickly provides the basic descriptive statistics. In the output for this command there are also several columns that begin with p: p0, p25, p50, p75, and p100 (p25 and p75 are omitted in output due to space). These columns correspond to the 0th, 25th, 50th, 75th, and 100th percentiles, respectively. The minimum and maximum values for the data column are indicated under the p0 and p100 labels. The median is the 50th percentile (p50). The interquartile range is the range between p25 and p75. Notice that we run this command on the “wide” version of the data (analytic_data_occasions) rather than tidy version of the data (analytic_occasion_tidy).
## skim_variable n_missing mean sd p0 p50 p100
## 1 age 3 20.52 2.05 17.0 20.0 24.00
## 2 esteem_t1 0 3.40 0.32 2.5 3.4 4.25
## 3 esteem_t2 0 3.93 0.34 3.2 4.0 4.80
## 4 jobsat_t1 0 3.91 0.43 2.0 4.0 5.00
## 5 jobsat_t2 0 4.18 0.34 3.0 4.2 4.8027.10.2 apa.cor.table()
Another approach is the apa.cor.table() command from the apaTables package. This quickly provides the basic descriptive statistics as well as correlations among variable. As well, it will even create a Word document with this information, see Figure 27.3. Notice that we run this command on the “wide” version of the data (analytic_data_occasions) rather than tidy version of the data (analytic_occasion_tidy).
library(apaTables)
analytic_data_survey %>%
select(where(is.numeric)) %>%
apa.cor.table(filename = "apa_descriptives.doc")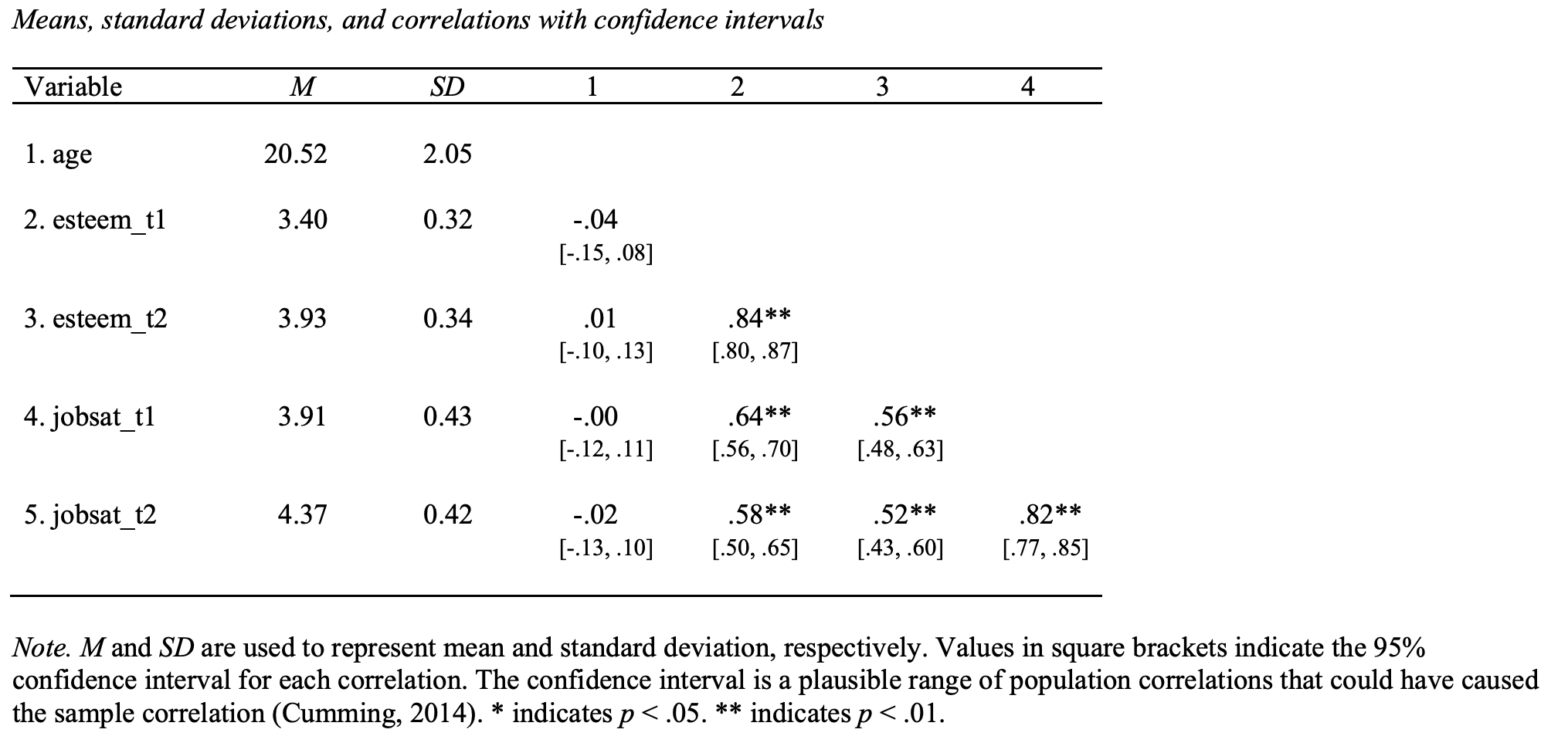
FIGURE 27.3: Word document created by apa.cor.table
27.10.3 tidyverse
A final approach uses tidyverse commands. This approach is oddly long - and we won’t describe how it works in detail. But, based on the information in the previous chapter you should be able to work out how this code works. Even though this code is long - it provide the ultimate in flexibility. If a new statistic is developed that you want to use, you can simply include the command for it in the desired_descriptives list and it will be included in your table. Notice that we run this command on the “wide” version of the data (analytic_data_occasions) rather than tidy version of the data (analytic_occasion_tidy).
library(tidyverse)
# HMisc package must be installed.
# Library command not needed for HMisc package.
desired_descriptives <- list(
mean = ~mean(.x, na.rm = TRUE),
CI95_LL = ~Hmisc::smean.cl.normal(.x)[2],
CI95_UL = ~Hmisc::smean.cl.normal(.x)[3],
sd = ~sd(.x, na.rm = TRUE),
min = ~min(.x, na.rm = TRUE),
max = ~max(.x, na.rm = TRUE),
n = ~sum(!is.na(.x))
)
row_sum <- analytic_data_occasions %>%
summarise(across(.cols = where(is.numeric),
.fns = desired_descriptives,
.names = "{col}___{fn}"))
long_summary <- row_sum %>%
pivot_longer(cols = everything(),
names_to = c("var", "stat"),
names_sep = c("___"),
values_to = "value")
summary_table <- long_summary %>%
pivot_wider(names_from = stat,
values_from = value)
# round to 3 decimals
summary_table_rounded <- summary_table %>%
mutate(across(.cols = where(is.numeric),
.fns= round,
digits = 3)) %>%
as.data.frame()
print(summary_table_rounded)## var mean CI95_LL CI95_UL sd min max n
## 1 age 20.522 20.288 20.756 2.048 17.0 24.00 297
## 2 esteem_t1 3.403 3.366 3.440 0.324 2.5 4.25 300
## 3 esteem_t2 3.927 3.889 3.966 0.337 3.2 4.80 300
## 4 jobsat_t1 3.905 3.856 3.955 0.435 2.0 5.00 300
## 5 jobsat_t2 4.184 4.146 4.223 0.338 3.0 4.80 30027.10.4 Cronbach’s alpha
If you want Cronbach’s alpha to estimate the reliability of the scale, you can use the alpha command from the psych package with the code below. Note we have to use the item-level data we previously created a copy of called analytic_data_survey_items. The glimpse() command illustrates this data set has all the original items (after reverse-key coding has been fixed).
## Rows: 300
## Columns: 14
## $ id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,…
## $ age <dbl> 23, 22, 18, 23, 22, 17, 23, 22, 17…
## $ sex <fct> male, female, male, female, male, …
## $ eye_color <fct> blue, brown, hazel, blue, NA, haze…
## $ esteem1_likert5 <dbl> 3, 4, 4, 3, 3, 3, 3, 4, 4, 4, 3, 4…
## $ esteem2_likert5 <dbl> 2, 3, 3, 2, 2, 3, 2, 3, 3, 3, 2, 2…
## $ esteem3_likert5 <dbl> 4, 4, 4, 3, 4, 4, NA, 4, 4, 3, 4, …
## $ esteem4_likert5 <dbl> 3, 4, 4, 3, 4, 4, 4, 4, 3, 4, NA, …
## $ esteem5_likert5 <dbl> 4, 4, 4, 4, 4, NA, NA, 4, 4, 4, 3,…
## $ jobsat1_likert5 <dbl> 3, 5, 4, 3, 3, 3, 3, 5, 3, 3, 3, 4…
## $ jobsat2_likert5 <dbl> 5, 5, 5, NA, 5, 5, 4, 5, 4, 4, 3, …
## $ jobsat3_likert5 <dbl> 3, NA, 3, 3, 3, 3, 3, 3, 3, 3, 3, …
## $ jobsat4_likert5 <dbl> NA, 5, 5, 4, 4, 4, 4, 5, NA, 4, NA…
## $ jobsat5_likert5 <dbl> 5, NA, 5, 4, 5, 4, 4, 5, 5, 5, 4, …We calculated reliability using psych::alpha() command. Cronbach’s alpha is labeled “raw alpha” in the output. Cronbach’s alpha is an estimate of the proportion of variability in observed scores that is due to actual differences among participants (rather than measurement error). Remember, never use library(psych), it will break the tidyverse packages. Instead, precede all psych package commands with psych:: as we do below with psych::alpha().
rxx_alpha <- analytic_data_occasions_items %>%
select(starts_with("t1_esteem")) %>%
psych::alpha()
print(rxx_alpha$total)## raw_alpha std.alpha G6(smc) average_r S/N ase mean
## 0.6622 0.6622 0.616 0.2817 1.961 0.03035 3.403
## sd median_r
## 0.3239 0.2919