Chapter 8 Qualtrics
8.1 Overview
Chapter 7 walked through the data-preparation workflow using a clean, already-entered spreadsheet. This chapter applies that same workflow to data collected with Qualtrics — the survey platform you are most likely to use — taking you from building the survey all the way to turning its raw export into analytic data.
There are two tasks covered in this chapter: 1) importing surveys into Qualtrics and 2) moving data from Qualtrics to R. An overview of each process is below.
1. Importing items into Qualtrics
- Create a survey codebook in Excel (or similar program) that has each item and the response options for it
- Convert the survey codebook to Qualtrics Advanced Text Format
- Import the items
- Tweak the survey after import
2. Qualtrics Data to R
- Export the raw data from Qualtrics with maximal information in the data file
- Load the raw data into R
- Convert the raw data to analytic data. This conversion includes: assigning values to response options (e.g., “Strongly Disagree” to a numeric value), flipping response for reverse-worded (i.e., reverse-keyed) items, and creating scale scores.
The overall steps are quite simple and I walk you through each step in detail below.
8.2 Required
The files below are used in this chapter. Right click to save each file.
| Relevant files |
|---|
| survey_codebook.csv |
| items_qualtrics_format.txt |
| data_qualtrics.csv |
| script_qualtrics.R |
The following CRAN packages must be installed:
| Required CRAN Packages |
|---|
| tidyverse |
| janitor |
| remotes |
The following GitHub packages must be installed:
| Required GitHub Packages |
|---|
| dstanley4/qualtricsMaker |
A GitHub package can be installed using the code below:
8.3 Items to Qualtrics
There are two approaches to entering survey items into Qualtrics.
Enter the items one at a time using the Qualtrics web interface.
Create a text file in the Qualtrics Advanced Text Format and import the items. Be warned though a bit of tweaking is often still needed using the web interface.
Here we focus only on the second approach to entering items into Qualtrics.
8.3.1 Create survey codebook
The easy way to create items in the Advanced Text Format is to use the qualtricsMaker package. With this package you create a spreadsheet with the items and then convert that spreadsheet to the Advanced Text Format.
Consider a scenario where we want to create a survey that contains 2 demographics items, 18 commitment items, and 4 job satisfaction items. The three-component model of commitment items are from (Meyer et al. 1993) and the job satisfaction items are from (Thompson and Phua 2012).
We begin by creating a survey codebook spreadsheet in Excel (or similar program). The spreadsheet should have the columns with the names: block, item_name, item_text, type, response_options. The completed file ( survey_codebook.csv) is illustrated below. I provide a detailed description of what should be placed in each column after the figure. Remember to work from the guiding principle that one row is used for one item/question.
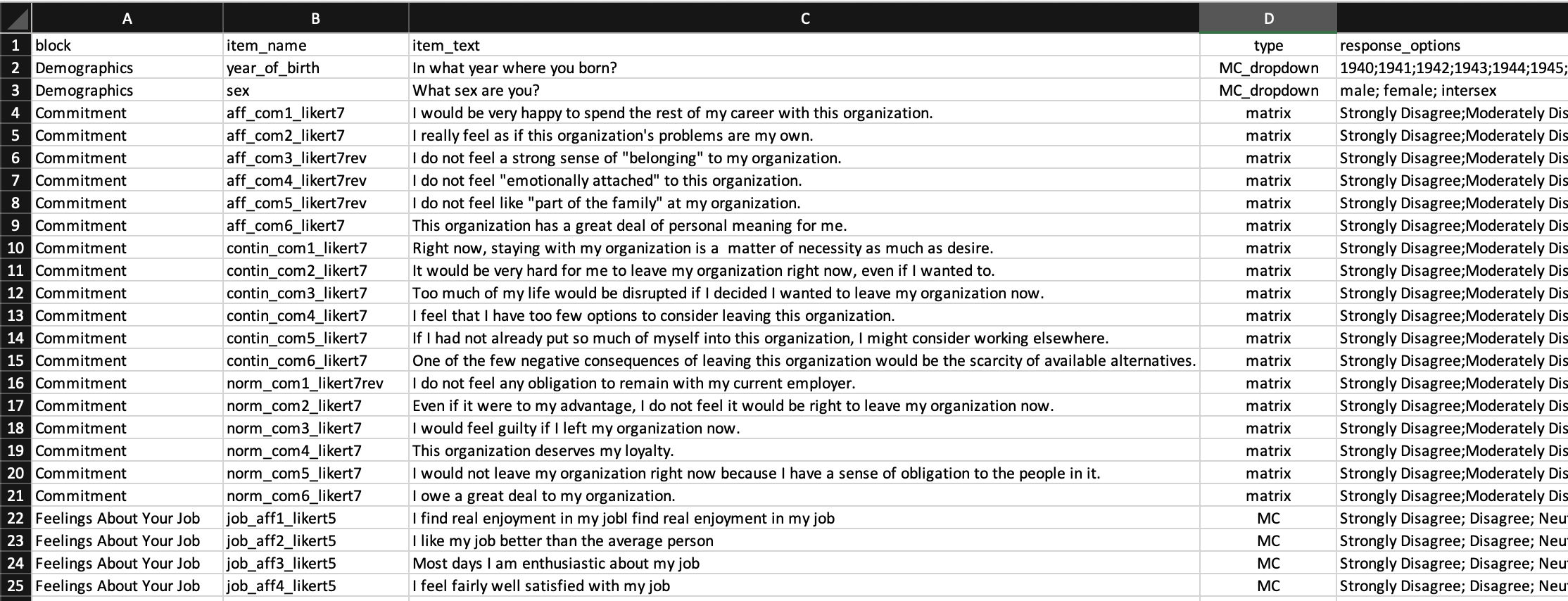
8.3.1.2 item_name column
To make your life easier down the road, it is critical you set up your spreadsheet or online survey such that it uses a naming convention prior to data collection. Recall the naming convention from the previous chapter.
8.3.1.3 item_text column
The item_text column contains the text for each item. Note that if you use commas in your item text do not save this file as a .csv file - it will not work. Rather save it as .tsv file (tab separated values). Then use read_tsv command instead of the read_csv command in the code that follows later.
8.3.1.4 type column
| Code for type column | Qualtrics Item Type | Additional Information |
|---|---|---|
| matrix | matrix | If the first item in a block has type matrix all items in the block will be used to construct the matrix question. Unfortunately, importing item_names for matrix questions is not supported by Qualtrics. You will need to manually restore your item_names following the directions below for matrix items. |
| MC | multiple choice vertical format | |
| MC_horizontal | multiple choice horizontal format | |
| MC_multi_horizontal | multiple choice horizontal format multiple answers | |
| MC_select | select box | |
| MC_multi_select | select multiple boxes | |
| MC_dropdown | dropdown |
8.3.1.5 response_options column
The Likert items for the different blocks use different response options. The commitment items use a 7-point response option whereas the job satisfaction items use a 5-point response option.
8.3.1.5.1 Year of birth
We used a number of response options to indicate Year of Birth. We entered them as per below. Each response option is separated by a semi-colon. Each of the years below will be in the dropdown button.
Entered in the response_option column as below. Each option separated by a semicolon.
1940;1941;1942;1943;1944;1945;1946;1947;1948;1949;1950;1951;1952;1953;1954;1955;1956;1957;1958;1959;1960;1961;1962;1963;1964;1965;1966;1967;1968;1969;1970;1971;1972;1973;1974;1975;1976;1977;1978;1979;1980;1981;1982;1983;1984;1985;1986;1987;1988;1989;1990;1991;1992;1993;1994;1995;1996;1997;1998;1999;2000;2001;2002;2003;2004;2005;2006;2007;2008;2009;2010
8.3.1.5.2 Sex 3 points
Please note that in psychology we distinguish between sex and gender. We use the term “sex” to refer to underlying biology. In contrast, we use the term “gender” to refer a psychological construct (i.e., gender identity). A person’s sex and gender may be quite different. Depending on the theory used in a study, you might be interested in sex or gender or both. In this example, we are using sex but not gender. If you were asking about gender - you would have a much longer (and quite different) list of options.
Entered in the response_option column as below. Each option separated by a semicolon.
male; female; intersex
8.3.2 Convert to Qualtrics format
8.3.2.1 Create TXT file
Once you have the survey codebook above, you need to convert it to an Advanced Text Format .txt file. We can do so by following the steps below. The instructions differ slightly for RStudio Cloud and RStudio - both are presented.
8.3.2.1.1 RStudio on your computer
Create a folder on your computer called “new_survey” with the survey_codebook.csv file in it.
Open RStudio. Then go to File > New Project… and select Existing Directory.
- Then find and select the “new_survey” folder on your hard drive and click the Create Project button.
- You should previously have installed the remotes and tidyverse packages from the CRAN and the qualtricsMaker package from GitHub. If you haven’t done this already type the commands below into the Console.
Installing Packages from the CRAN
Installing Package from GitHub
Then install the qualtricsMaker package from GitHub:
- Create a new script by going to File > New File > R Script. A new script will appear in RStudio. Immediately press Control-S to save the script. Call it “script_convert.R”.

- Place the code below into the script and press Control-S to save your work.
library(tidyverse)
library(qualtricsMaker)
survey_codebook <- read_csv("survey_codebook.csv",
show_col_types = FALSE)
make_survey(survey_codebook,
filename = "items_qualtrics_format.txt")- Run the script by pressing the Source button in the top right of the the Script window. Doing so will create the items_qualtrics_format.txt file that you will import into Qualtrics. You can see the file after it has been created in the Files tab below.
Congratulations - your items are ready to be imported into Qualtrics. Move on to the “Import the items” section.
8.3.2.1.2 RStudio Cloud
Open a new project in RStudio Cloud
You should previously have installed the remote and tidyverse package from the CRAN and the qualtricsMaker package from GitHub. If you haven’t done this already type the commands below into the Console.However, if you are working from a class project I created these packages will have been installed already for you.
Then install the qualtricsMaker package from GitHub:
- Import the survey_codebook.csv file by using the Upload button in the Files tab in the lower right panel.
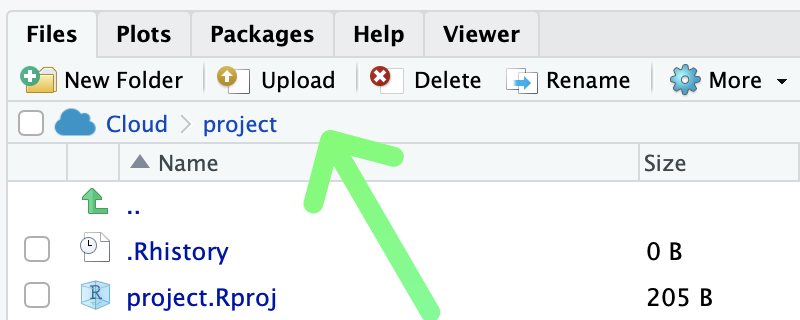
- Click the Choose File button and select the survey_codebook.csv file on your hard drive. Then click OK. The survey_codebook.csv file will then appear on the Files tab within RStudio Cloud.
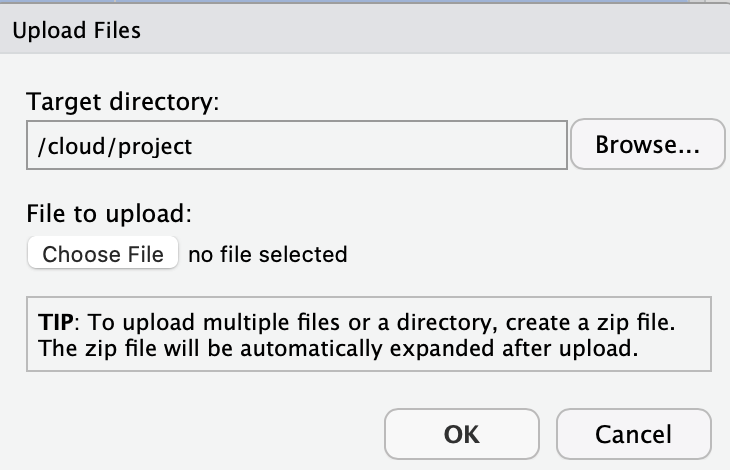
- Create a new script by going to File > New File > R Script. A new script will appear in RStudio. Immediately press Control-S to save the script. Call it “script_convert.R”.

- Place the code below into the script and press Control-S to save your work.
library(tidyverse)
library(qualtricsMaker)
survey_codebook <- read_csv("survey_codebook.csv",
show_col_types = FALSE)
make_survey(survey_codebook,
filename = "items_qualtrics_format.txt")- Run the script by pressing the Source button in the top right of the the Script window. Doing so will create the items_qualtrics_format.txt file that you will import into Qualtrics. You can see the file after it has been created in the Files tab below.
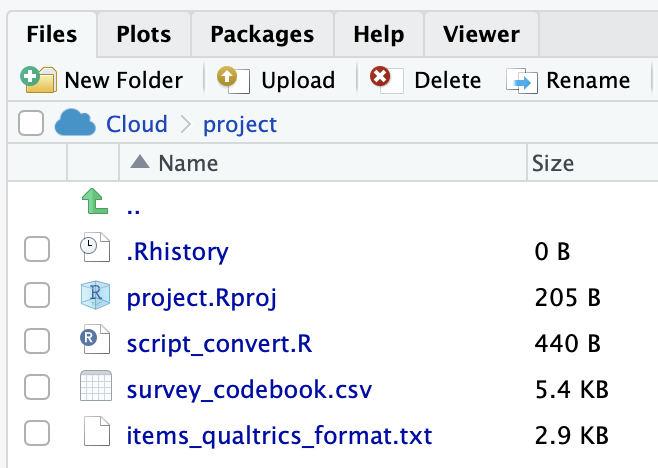
- Select the checkbox beside the file you just created: items_qualtrics_format.txt
- Select Export from the More menu.
- Leave the filename as it appears and click the Download button. The file will appear in the Downloads directory on your computer.
- Move the file (items_qualtrics_format.txt) from the Download folder to an easy to access place (e.g. the Desktop).
Congratulation - your items are ready to be imported into Qualtrics. Move on to the “Import the items” section.
8.3.3 Import the items
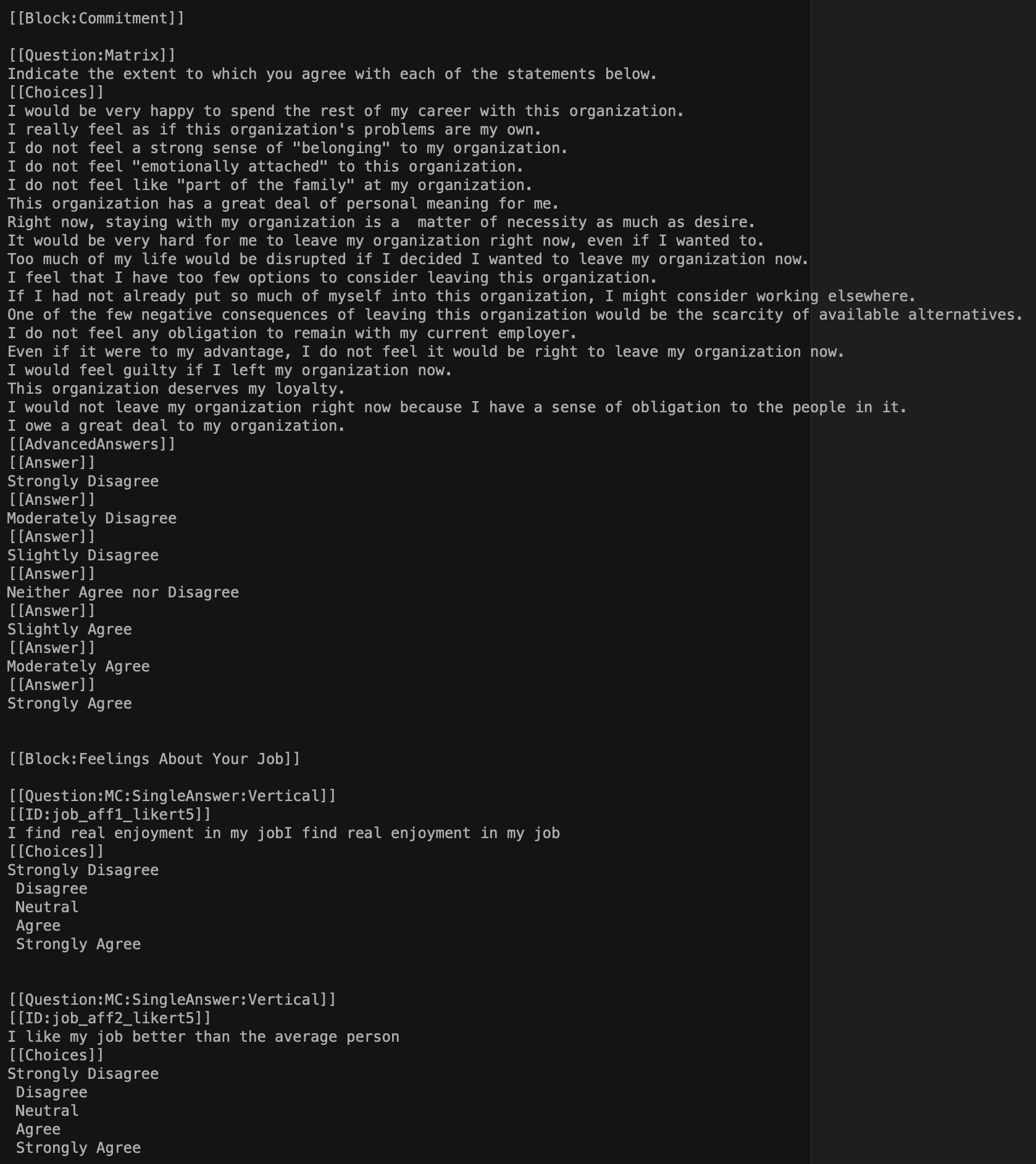
In the previous step you created items_qualtrics_format.txt. This file is illustrated below - well the middle of the file is illustrated below. You can think of the file created by the survey_maker command above as a starting point. You could open up this file in a text editor and make further modifications or additions based on learning the Advanced Text Format. For example, you might not want the matrix items to be in their own block. If so, you would simply remove the block text [[Block:Commitment]] from the text file prior to following the directions below. If you’re a Mac user you might find the text editor BBEdit helpful for this purpose – the free version is sufficient. After you download BBEdit you have access to all of its features. Once the free trial ends - the core features are still free. You only need to purchase it if you want the advanced features (and you won’t need the advanced features).
8.3.3.0.1 Begin the import by logging into Qualtrics
Begin by logging into Qualtrics via the University of Guelph site for Data Collection & Surveys. After you log in, continue below.

8.3.4 Tweak survey in Qualtrics
Now you need to tweak the survey using the Qualtrics interface. Recall that when you import items into Qualtrics, matrix-style questions will loose their item names. You need to manually restore the item names for matrix questions now.
- Begin by scrolling down to a block of matrix-style questions. Select the block so it gets a blue rectangle around it.
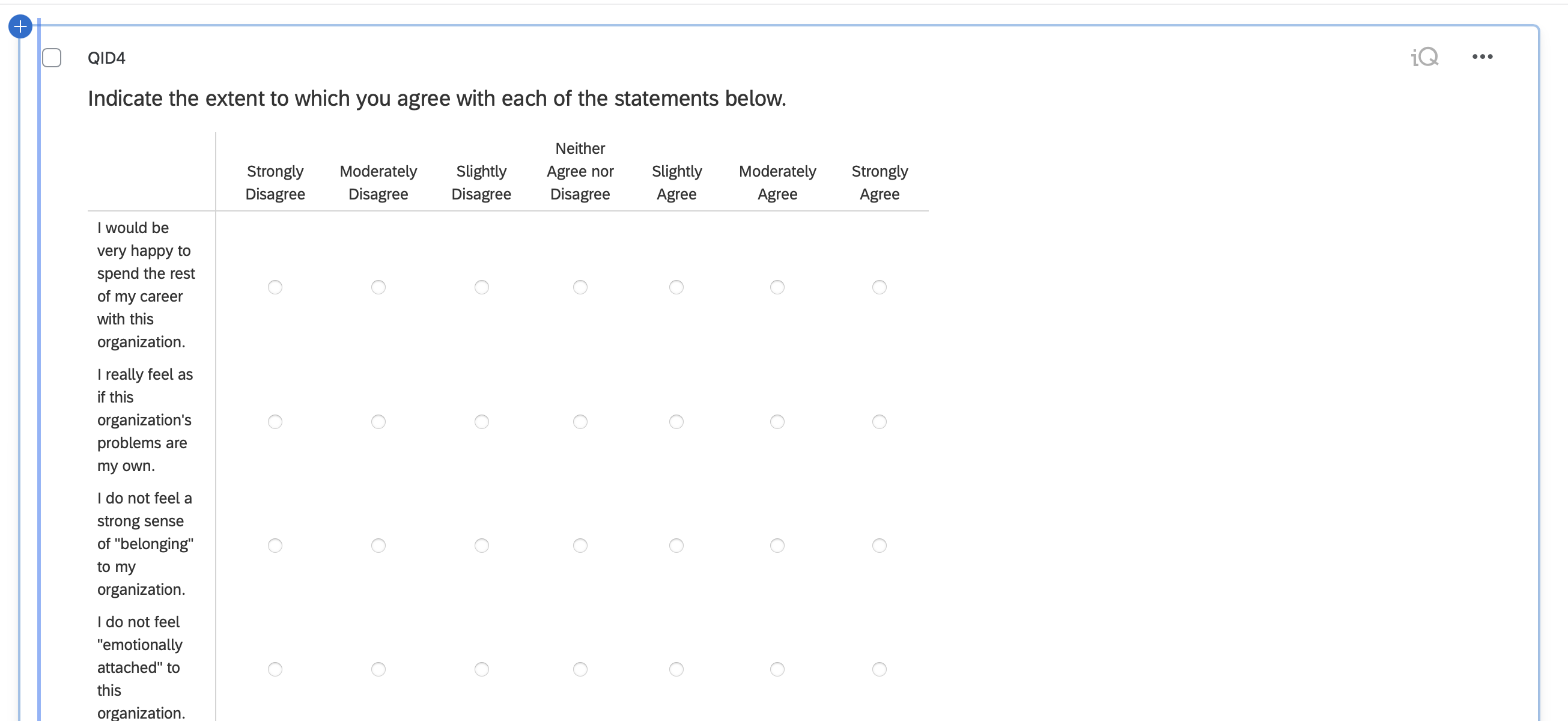
- On the left side menu go the “Question Behaviour” menu and select “Recode values”
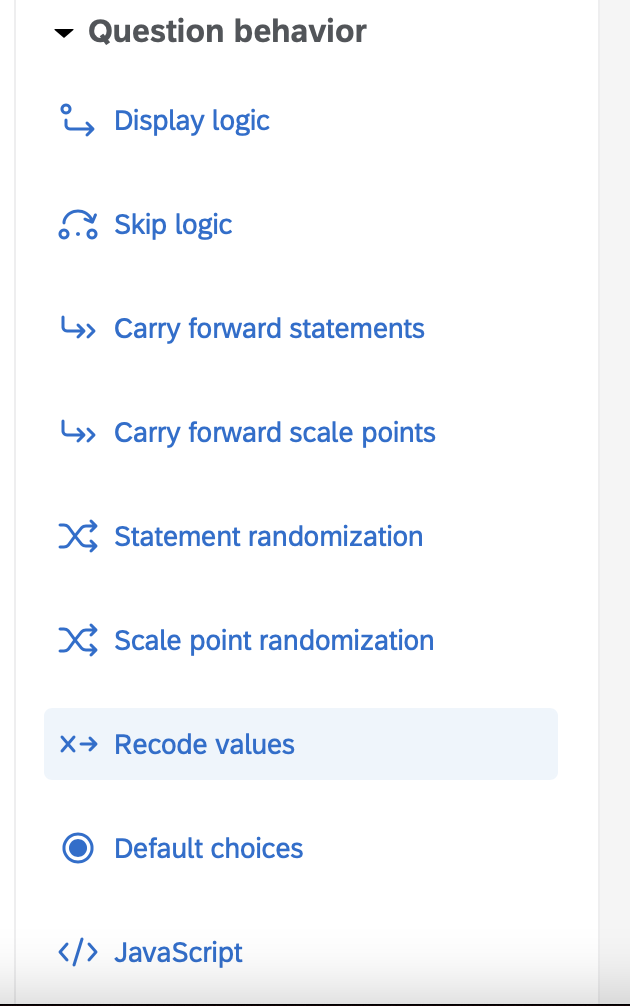
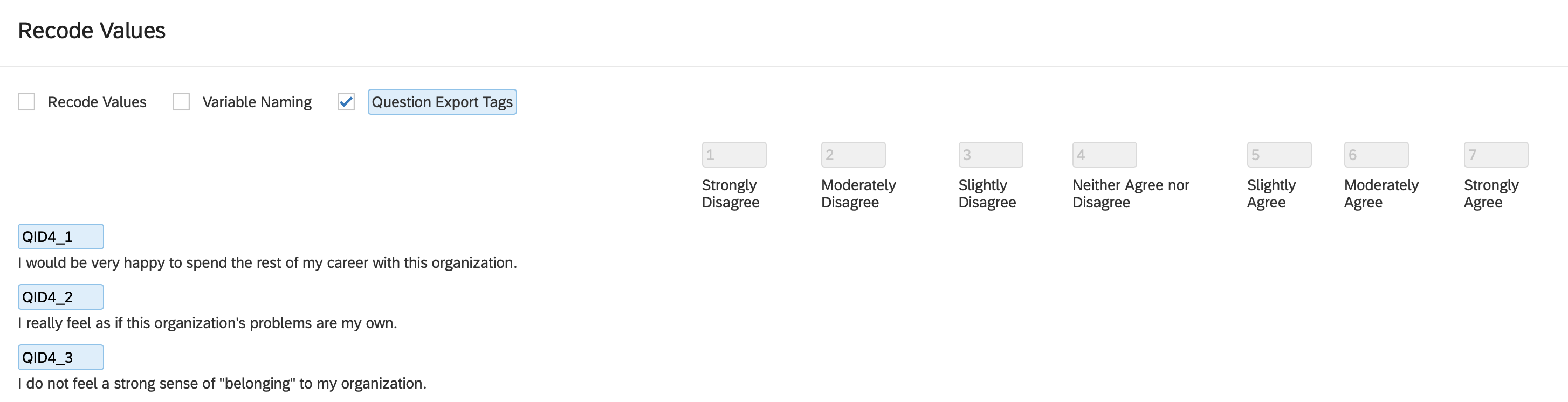
- Click the Export Question Tags check box. You will see the default names for the items (instead of the ones you indicated in the codebook). Click the Close button in the lower right when you’re done.
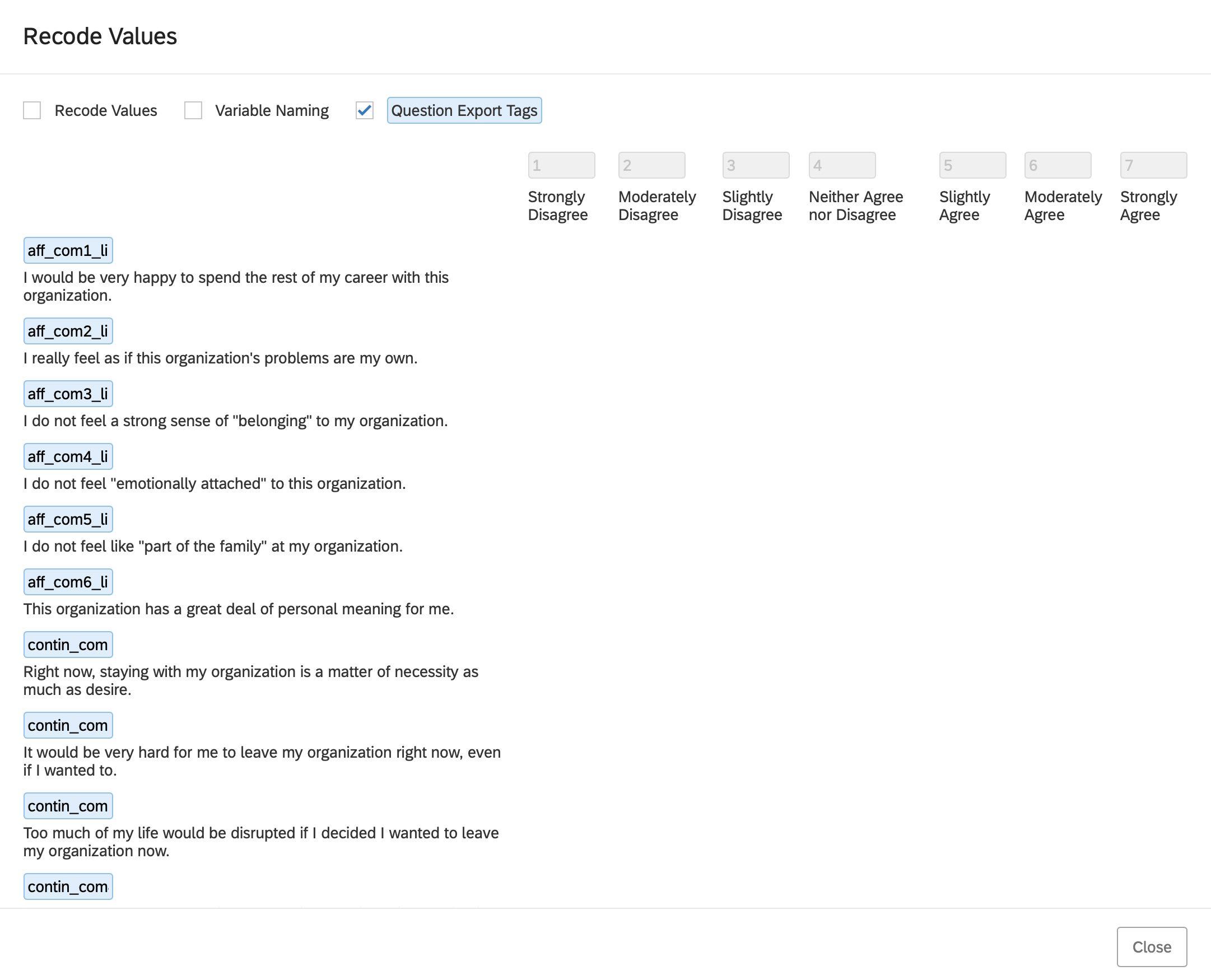
- Manually restore the item names from the survey codebook by clicking the blue name for each item and fixing it. Don’t forget to use proper item naming formats and include the reverse-key status of each item.
- Collect your data!
8.4 Qualtrics data to R
Following data collection, you can obtain your data from Qualtrics. As of 2021, Tri-Agency (NSERC, SSHRC, CIHR) policy is that data collected with Tri-Agency funded research must be available for reuse by others. The data should follow the FAIR (Findable, Accessible, Interoperable, and Reusable) principle. Consequently, when you export the data from Qualtrics (and eventually post it) we want to ensure it has as much information in it as possible. This principle guides the options we select below.
8.4.1 Export from Qualtrics

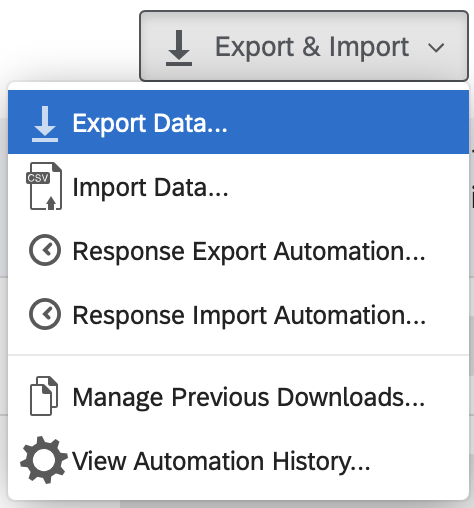
8.4.1.3 Click Use Choice Text
To ensure the data can be used by others, as per the FAIR policy described above, we SELECT the “Use Choice Text” option when exporting data. If you were to (non-optimally) select “Use numeric value” as an export option then the resulting data file would be missing information that make it difficult for others to use. Then click the Download button.
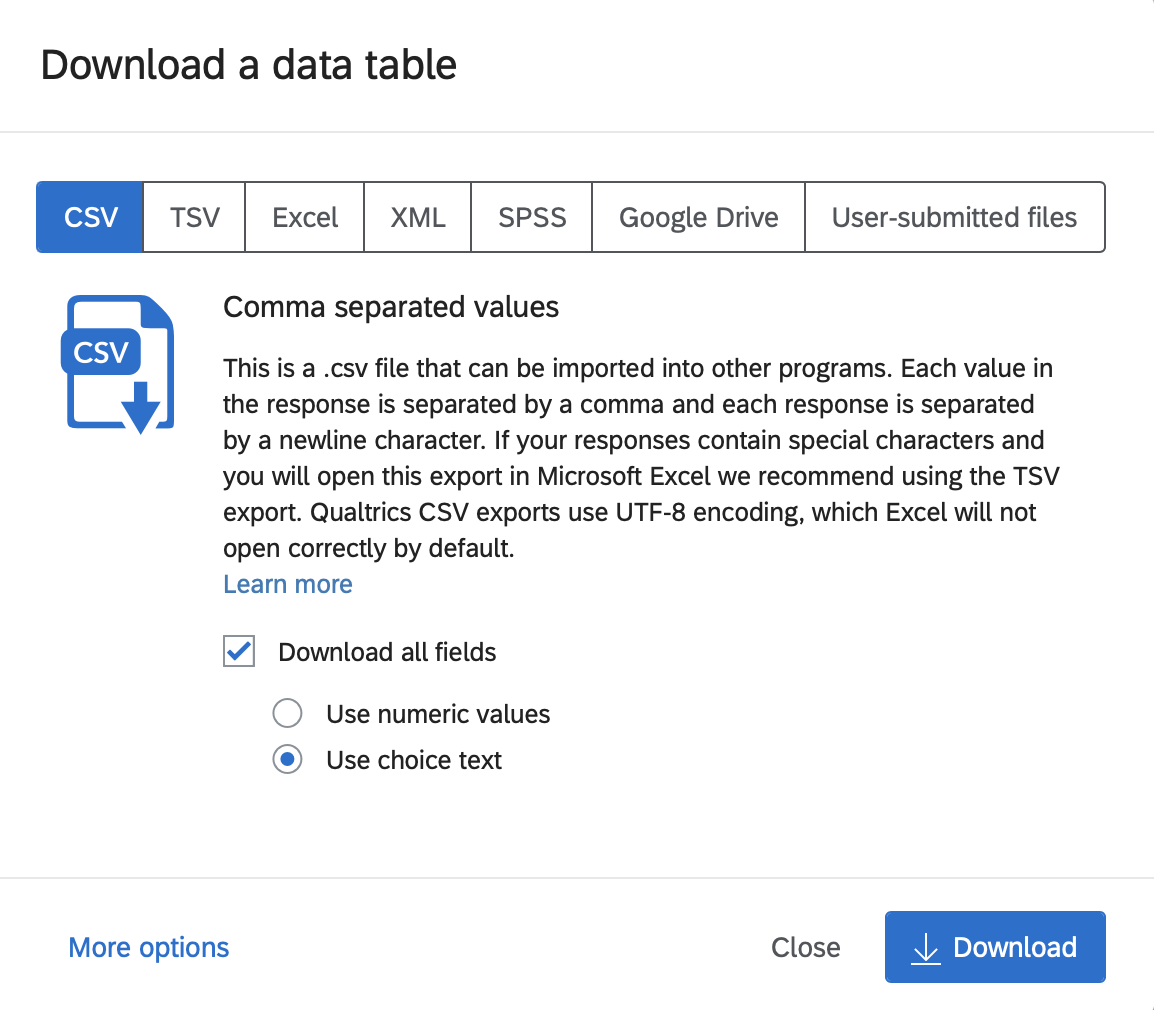
The file will appear in your downloads directory.
It will likely be a zipped filed. Unzip the file before proceeding. On a Mac, you can just double click the file to do so.
Rename the file to data_qualtrics.csv
8.4.2 Load data in R
To load the data in R follow the steps below
Create a new folder called “survey_data”
Drag the data_qualtrics.csv file to the survey_data folder.
Use the steps described previously on this page, use RStudio to create project for this data.
You may be tempted to load the data using the usual read_csv() process. This will be problematic due to the way the data is formatted in the .csv file. (see image below.)

- You can see by inspecting the data screenshot above that a variety of columns have been included before our first data column (year_of_birth) which appears on the far right of screenshot. Also note that there are three header rows at the top of the file before the data which starts on row 4. So there are few problems that need to be addressed when we load data from Qualtrics.
Obtain the names from the first header row but read the data from row 4 on.
Remove some, or all, of the additional columns on the left side of data set added by Qualtrics
Ensure our variable names follow the tidyverse style guide
Ensure we DO NOT modify the data_qualtrics.csv file in Excel or other program. That would destroy the reproducibility of our work in the very first step.
8.4.3 Convert to analytic data
The issues described above are all solved with the script below.
Additionally, in the script we also:
Convert categorical variable to factors
Screen both numeric variables and factors for impossible values
Convert Likert items from labels (e.g., “Strongly Disagree”) to numbers (e.g., 1)
Flip reverse-key (i.e., reverse worded items) so they are scored in the right direction
Combine items (e.g., aff_com1_likert7) for the same measure into a single scale score (e.g., affective_commitment)
Remove item columns (e.g., aff_com1_likert7) after that have been combined into the scale score while retaining the scale score column column (e.g., affective_commitment)
Before we start writing code, it helps to see the whole journey at a glance. Figure 8.1 is a road map of the script you are about to build: it takes the raw Qualtrics file on the left and, one step at a time, turns it into the analytic data on the right. As the script gets long, you can use this picture to keep track of where you are — think of it as a “you are here” map. Each box is one job, and the arrows show how each step feeds the next. We will come back to this same picture in later chapters, where it grows a few more steps and is eventually drawn for you by the computer.
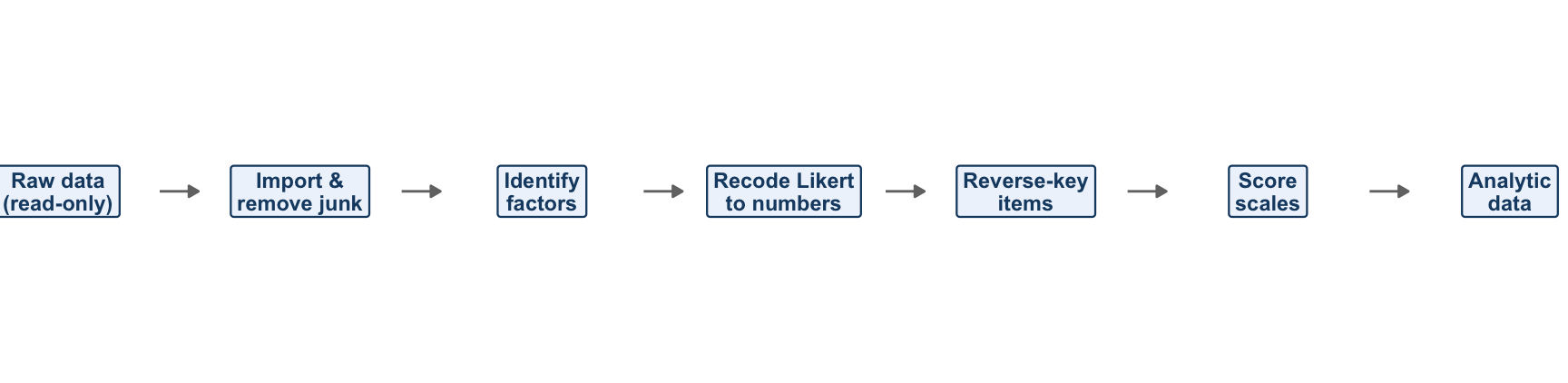
FIGURE 8.1: A road map of the Qualtrics pre-processing script: raw data in, analytic data out.
8.4.3.1 Load Data
# Date: YYYY-MM-DD
# Name: your name here
# Example: Single occasion survey
# Load data
library(tidyverse)
library(janitor)
library(skimr)
# read the file in the normal way and get just the names of the columns.
# put the names into the col_names
survey_file <- "data_qualtrics.csv"
col_names <- names(read_csv(survey_file,
n_max = 0,
show_col_types = FALSE))
# skip the first 3 rows than read in the data and use names from above
raw_data <- read_csv(survey_file,
col_names = col_names,
skip = 3,
show_col_types = FALSE)Remove the Qualtrics columns you probably don’t want:
# list of Qualtrics columns you probably don't want
cols_to_maybe_remove <- c("StartDate",
"EndDate",
"Status",
"IPAddress",
"Progress",
"Finished",
"RecordedDate",
"ResponseId",
"RecipientLastName",
"RecipientFirstName",
"RecipientEmail",
"ExternalReference",
"LocationLatitude",
"LocationLongitude",
"DistributionChannel",
"UserLanguage")
# check to see overlap with actual column names in data file
# put names to remove (that are present) into cols_to_remove
cols_to_remove_id <- col_names %in% cols_to_maybe_remove
cols_to_remove <- col_names[cols_to_remove_id]
# remove the unwanted Qualtrics columns
raw_data <- raw_data |>
select(!all_of(cols_to_remove))Note that we deliberately keep the Duration (in seconds) column (after cleaning it becomes duration_in_seconds). Although Qualtrics adds it automatically, it is useful later for screening — for example, you may want to exclude participants who completed the survey implausibly quickly. Drop a column only once you are sure no later step needs it.
We make a copy of the data called analytic_data_survey since the goals of the next several steps are to prepare the data for analysis.
In the command below, we ensure our column names follow the tidyverse style guide by using the clean_names() command from the janitor package. Additionally, we remove empty row and columns from the data using the remove_empty_cols() and remove_empty_rows(), respectively.
# Initial cleaning
## Convert column names to tidyverse style guide
## Remove empty rows and columns
analytic_data_survey <- analytic_data_survey |>
remove_empty("rows") |>
remove_empty("cols") |>
clean_names()You can confirm the column names following our naming convention with the glimpse command - and see the data type for each column.
## Rows: 150
## Columns: 25
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953,…
## $ sex <chr> "female", "female", "female",…
## $ aff_com1_likert7 <chr> "Slightly Agree", "Neither Ag…
## $ aff_com2_likert7 <chr> "Slightly Agree", "Slightly D…
## $ aff_com3_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com4_likert7rev <chr> "Moderately Disagree", "Stron…
## $ aff_com5_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com6_likert7 <chr> "Moderately Agree", "Strongly…
## $ contin_com1_likert7 <chr> "Strongly Agree", "Neither Ag…
## $ contin_com2_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com3_likert7 <chr> "Strongly Disagree", "Slightl…
## $ contin_com4_likert7 <chr> "Moderately Agree", "Neither …
## $ contin_com5_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com6_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com1_likert7rev <chr> "Neither Agree nor Disagree",…
## $ norm_com2_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com3_likert7 <chr> "Neither Agree nor Disagree",…
## $ norm_com4_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com5_likert7 <chr> "Strongly Disagree", "Strongl…
## $ norm_com6_likert7 <chr> "Strongly Agree", "Strongly D…
## $ job_aff1_likert5 <chr> "Strongly Agree", "Strongly A…
## $ job_aff2_likert5 <chr> "Strongly Disagree", "Strongl…
## $ job_aff3_likert5 <chr> "Neutral", "Strongly Disagree…
## $ job_aff4_likert5 <chr> "Disagree", "Strongly Agree",…8.4.3.2 Creating factors
Following initial cleaning, we identify categorical variables as factors.
## Rows: 150
## Columns: 25
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953,…
## $ sex <chr> "female", "female", "female",…
## $ aff_com1_likert7 <chr> "Slightly Agree", "Neither Ag…
## $ aff_com2_likert7 <chr> "Slightly Agree", "Slightly D…
## $ aff_com3_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com4_likert7rev <chr> "Moderately Disagree", "Stron…
## $ aff_com5_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com6_likert7 <chr> "Moderately Agree", "Strongly…
## $ contin_com1_likert7 <chr> "Strongly Agree", "Neither Ag…
## $ contin_com2_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com3_likert7 <chr> "Strongly Disagree", "Slightl…
## $ contin_com4_likert7 <chr> "Moderately Agree", "Neither …
## $ contin_com5_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com6_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com1_likert7rev <chr> "Neither Agree nor Disagree",…
## $ norm_com2_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com3_likert7 <chr> "Neither Agree nor Disagree",…
## $ norm_com4_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com5_likert7 <chr> "Strongly Disagree", "Strongl…
## $ norm_com6_likert7 <chr> "Strongly Agree", "Strongly D…
## $ job_aff1_likert5 <chr> "Strongly Agree", "Strongly A…
## $ job_aff2_likert5 <chr> "Strongly Disagree", "Strongl…
## $ job_aff3_likert5 <chr> "Neutral", "Strongly Disagree…
## $ job_aff4_likert5 <chr> "Disagree", "Strongly Agree",…8.4.3.2.1 Sex
There is only one variable that we will convert to a factor and that’s the sex variable. We convert it to a factor with the command below.
8.4.3.2.2 Participant identification
In many analyses we will need a column with a unique identification number that is a factor. We don’t see one in this data set so we create it with the name participant_id.
## Participant identification to factor
## Participant identification column must be created first
## get the number of rows in the data set
N <- dim(analytic_data_survey)[1]
## create set of factor levels
participant_id_levels <- factor(seq(1, N))
## put the factor levels into a column called participant_id
analytic_data_survey <- analytic_data_survey |>
mutate(participant_id = participant_id_levels)This is not the only way to create an identification column. A common shortcut is mutate(participant_id = row_number()), which numbers the rows directly; you would then convert it to a factor if an analysis requires it. The two approaches are equivalent — pick one and use it consistently. Don’t be surprised if you see row_number() used in other scripts.
You can ensure all of these columns are now factors using the glimpse() command.
## Rows: 150
## Columns: 2
## $ sex <fct> female, female, female, male, inter…
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …8.4.3.3 Factor screening
Inspect the levels of each factor carefully. Make sure the factor levels of each variable are correct. Examine spelling and look for additional unwanted levels. For example, you wouldn’t want to have the following levels for sex: male, mmale, female. Obviously, mmale is an incorrectly typed version of male. Scan all the factors in your data for erroneous factor levels. The code below displays the factor levels for sex:
## sex
## female :43
## male :49
## intersex:58You can see in the above output there are three levels for sex in this data set: female, male and intersex. You can also see beside each of these labels the number of participants for each category.
Notice the order of the factor levels: female, male, and intersex. This will be the order they appear in graphs and tables. We might want another order. If we did want another order, we could use the code below to establish the custom order for graphs and tables: female, intersex, male. Of course, you can use any order you want that makes sense for the context and your research question.
8.4.3.4 Numeric screening
For numeric variables, it’s important to find and remove impossible values. We only have year_of_birth as a numeric column - so we can easily check for nonsense values with the code below:
## skim_variable n_missing mean sd p0 p50 p100
## 1 year_of_birth 0 1974 20.06 1940 1970 20108.4.3.5 Item values from labels
Recall that when we obtained our data from Qualtrics we selected “Use Choice Text”. That means that, as desired, we didn’t get values for our Likert items - we obtained labels. Now we need to switch the Likert responses to numeric values. The advantage of handling our data in this way is that anyone examining our data and code in an open access repository can see exactly what options survey participants were provided with for each question.
But prior to beginning check out the type for each Likert column below using the glimpse() command notice that are all of type “chr”.
## Rows: 150
## Columns: 26
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953,…
## $ sex <fct> female, female, female, male,…
## $ aff_com1_likert7 <chr> "Slightly Agree", "Neither Ag…
## $ aff_com2_likert7 <chr> "Slightly Agree", "Slightly D…
## $ aff_com3_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com4_likert7rev <chr> "Moderately Disagree", "Stron…
## $ aff_com5_likert7rev <chr> "Strongly Disagree", "Neither…
## $ aff_com6_likert7 <chr> "Moderately Agree", "Strongly…
## $ contin_com1_likert7 <chr> "Strongly Agree", "Neither Ag…
## $ contin_com2_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com3_likert7 <chr> "Strongly Disagree", "Slightl…
## $ contin_com4_likert7 <chr> "Moderately Agree", "Neither …
## $ contin_com5_likert7 <chr> "Slightly Agree", "Slightly A…
## $ contin_com6_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com1_likert7rev <chr> "Neither Agree nor Disagree",…
## $ norm_com2_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com3_likert7 <chr> "Neither Agree nor Disagree",…
## $ norm_com4_likert7 <chr> "Moderately Disagree", "Moder…
## $ norm_com5_likert7 <chr> "Strongly Disagree", "Strongl…
## $ norm_com6_likert7 <chr> "Strongly Agree", "Strongly D…
## $ job_aff1_likert5 <chr> "Strongly Agree", "Strongly A…
## $ job_aff2_likert5 <chr> "Strongly Disagree", "Strongl…
## $ job_aff3_likert5 <chr> "Neutral", "Strongly Disagree…
## $ job_aff4_likert5 <chr> "Disagree", "Strongly Agree",…
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10…When you have type chr for a column the computer sees the content of each column as text that is different for each participant. It doesn’t even realize that two people who both responded “Slightly Agree” responded the same way. It sees every response in the column as unique. Check that out for the aff_com1_likert7 item.
## aff_com1_likert7
## Length :150
## N.unique : 7
## N.blank : 0
## Min.nchar: 14
## Max.nchar: 268.4.3.5.1 Commitment Items
To convert a column from a character column to factor column we need know the exact labels used in that column. We can obtain those with the code below. In this code, we use just one item aff_com1_likert7. We determine the response options for that one item and will apply them to all the commitment items. We use the pull() command to obtain all the participant responses from the aff_com1_likert7. column. Then we use the unique() command to give use just one instance of each response.
# Convert Commitment items to numeric values
## Check levels for a likert7 item
analytic_data_survey |>
pull(aff_com1_likert7) |>
unique()## [1] "Slightly Agree"
## [2] "Neither Agree nor Disagree"
## [3] "Moderately Disagree"
## [4] "Strongly Agree"
## [5] "Strongly Disagree"
## [6] "Moderately Agree"
## [7] "Slightly Disagree"Now that we know the labels used in that column (and all the commitment columns that end in likert7) we create an ordered version of those labels with the code below. I copied and pasted the text (e.g., “Strongly Disagree”) from the above output to avoid typos.
## write code to create ordered factor labels/levels
likert7_factor <- c("Strongly Disagree",
"Moderately Disagree",
"Slightly Disagree",
"Neither Agree nor Disagree",
"Slightly Agree",
"Moderately Agree",
"Strongly Agree")Now we turn each column of text (i.e., type chr) into a factor column using the factor levels/labels we created:
## assign factor levels
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert7"),
.fns = ~ factor(.x, levels = likert7_factor)))In this code we use the mutate() command to modify columns. We use the across() command to have the single mutate command apply to several columns. Within the across() command we use contains(“likert7”) to apply the mutate() command only to columns with likert7 in the name. You can see why column naming conventions are so important! Next, within the across() command, we specify .fns. This indicate the function/command that will apply to the columns selected. The ~ before “factor” just warns the computer that what comes next is a function/command name. The factor() command is what will be applied to the columns. The .x within the factor command is a placeholder for each column name that will be obtained by the previous contains() command.
After this mutate() command is used you can see the columns with likert7 in the name are now factors.
## Rows: 150
## Columns: 26
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953,…
## $ sex <fct> female, female, female, male,…
## $ aff_com1_likert7 <fct> Slightly Agree, Neither Agree…
## $ aff_com2_likert7 <fct> Slightly Agree, Slightly Disa…
## $ aff_com3_likert7rev <fct> Strongly Disagree, Neither Ag…
## $ aff_com4_likert7rev <fct> Moderately Disagree, Strongly…
## $ aff_com5_likert7rev <fct> Strongly Disagree, Neither Ag…
## $ aff_com6_likert7 <fct> Moderately Agree, Strongly Ag…
## $ contin_com1_likert7 <fct> Strongly Agree, Neither Agree…
## $ contin_com2_likert7 <fct> Slightly Agree, Slightly Agre…
## $ contin_com3_likert7 <fct> Strongly Disagree, Slightly D…
## $ contin_com4_likert7 <fct> Moderately Agree, Neither Agr…
## $ contin_com5_likert7 <fct> Slightly Agree, Slightly Agre…
## $ contin_com6_likert7 <fct> Moderately Disagree, Moderate…
## $ norm_com1_likert7rev <fct> Neither Agree nor Disagree, S…
## $ norm_com2_likert7 <fct> Moderately Disagree, Moderate…
## $ norm_com3_likert7 <fct> Neither Agree nor Disagree, N…
## $ norm_com4_likert7 <fct> Moderately Disagree, Moderate…
## $ norm_com5_likert7 <fct> Strongly Disagree, Strongly D…
## $ norm_com6_likert7 <fct> Strongly Agree, Strongly Disa…
## $ job_aff1_likert5 <chr> "Strongly Agree", "Strongly A…
## $ job_aff2_likert5 <chr> "Strongly Disagree", "Strongl…
## $ job_aff3_likert5 <chr> "Neutral", "Strongly Disagree…
## $ job_aff4_likert5 <chr> "Disagree", "Strongly Agree",…
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10…Now examine aff_com1_likert7 again - you can see it has levels:
## aff_com1_likert7
## Strongly Disagree :21
## Moderately Disagree :21
## Slightly Disagree :21
## Neither Agree nor Disagree:18
## Slightly Agree :28
## Moderately Agree :21
## Strongly Agree :20The second step in our conversion process is converting each column from a factor to the numeric value associated with the factor level (i.e. Strongly Disagree becomes 1). We do so with the code below:
## covert factor levels to numeric values
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert7"),
.fns = as.numeric))You can see there are numeric values with the code below. Notice the column types for likert7 items is now dbl (short for double - a type of high precision number.)
## Rows: 150
## Columns: 26
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953,…
## $ sex <fct> female, female, female, male,…
## $ aff_com1_likert7 <dbl> 5, 4, 2, 7, 1, 6, 6, 2, 4, 2,…
## $ aff_com2_likert7 <dbl> 5, 3, 4, 2, 6, 7, 2, 3, 2, 7,…
## $ aff_com3_likert7rev <dbl> 1, 4, 2, 5, 7, 2, 6, 3, 5, 4,…
## $ aff_com4_likert7rev <dbl> 2, 7, 6, 6, 3, 5, 7, 6, 7, 2,…
## $ aff_com5_likert7rev <dbl> 1, 4, 6, 5, 3, 7, 5, 7, 5, 5,…
## $ aff_com6_likert7 <dbl> 6, 7, 1, 7, 5, 6, 5, 7, 4, 2,…
## $ contin_com1_likert7 <dbl> 7, 4, 1, 3, 2, 1, 1, 6, 7, 3,…
## $ contin_com2_likert7 <dbl> 5, 5, 3, 2, 7, 6, 1, 3, 5, 2,…
## $ contin_com3_likert7 <dbl> 1, 3, 7, 7, 5, 2, 7, 2, 7, 1,…
## $ contin_com4_likert7 <dbl> 6, 4, 3, 7, 7, 5, 4, 5, 3, 2,…
## $ contin_com5_likert7 <dbl> 5, 5, 1, 4, 4, 6, 5, 5, 5, 2,…
## $ contin_com6_likert7 <dbl> 2, 2, 1, 4, 7, 7, 6, 6, 4, 5,…
## $ norm_com1_likert7rev <dbl> 4, 3, 6, 3, 3, 6, 5, 7, 3, 7,…
## $ norm_com2_likert7 <dbl> 2, 6, 1, 5, 3, 2, 3, 1, 7, 1,…
## $ norm_com3_likert7 <dbl> 4, 4, 7, 3, 1, 1, 4, 3, 3, 5,…
## $ norm_com4_likert7 <dbl> 2, 2, 1, 6, 4, 6, 1, 1, 5, 5,…
## $ norm_com5_likert7 <dbl> 1, 1, 1, 5, 7, 4, 3, 6, 4, 4,…
## $ norm_com6_likert7 <dbl> 7, 1, 2, 4, 6, 6, 1, 4, 6, 2,…
## $ job_aff1_likert5 <chr> "Strongly Agree", "Strongly A…
## $ job_aff2_likert5 <chr> "Strongly Disagree", "Strongl…
## $ job_aff3_likert5 <chr> "Neutral", "Strongly Disagree…
## $ job_aff4_likert5 <chr> "Disagree", "Strongly Agree",…
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10…If you run the summary() command on the aff_com1_likert7 you see we have values now.
## aff_com1_likert7
## Min. :1.00
## 1st Qu.:2.00
## Median :4.00
## Mean :4.03
## 3rd Qu.:6.00
## Max. :7.00Side note: We did a lot of explaining as we went through the steps above. But it’s not as long as it seems. Some of the steps can even be combined. See the concise version of the code we used repeated below:
# Convert Commitment items to numeric values
## Check levels for a likert7 item
analytic_data_survey |>
pull(aff_com1_likert7) |>
unique()
## write code to create ordered factor labels/levels
likert7_factor <- c("Strongly Disagree",
"Moderately Disagree",
"Slightly Disagree",
"Neither Agree nor Disagree",
"Slightly Agree",
"Moderately Agree",
"Strongly Agree")
## assign factor levels and then covert to numeric
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert7"),
.fns = ~ factor(.x, levels = likert7_factor))) |>
mutate(across(.cols = contains("likert7"),
.fns = as.numeric))There is a more compact way to do the same conversion in a single step: a named lookup vector. Instead of converting to a factor and then to a number, you define the mapping directly and apply it:
likert7_recode <- c("Strongly Disagree" = 1,
"Moderately Disagree" = 2,
"Slightly Disagree" = 3,
"Neither Agree nor Disagree" = 4,
"Slightly Agree" = 5,
"Moderately Agree" = 6,
"Strongly Agree" = 7)
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert7"),
.fns = ~ likert7_recode[.x]))The two approaches give the same result, so don’t be surprised if you see the lookup-vector version in other scripts. We teach the factor-then-numeric version here because it is more transparent and because converting to a factor first lets you inspect and screen the response labels (with summary()) before they become numbers.
Notice that we just did essentially the same work twice — once for the 7-point commitment items and once for the 5-point job satisfaction items. Whenever you find yourself copying, pasting, and lightly editing a block of code, that is a signal that the block could become a reusable function — a named recipe you write once and call wherever you need it. We will not do that here, but keep the thought in mind: in Chapter 10 we will turn repeated steps like these into functions, which makes them easier to reuse, easier to test, and (as you will see) easier to get good help with from an AI assistant.
8.4.3.5.2 Job Satisfaction Conversion
We’ll skip all the explanation steps for Job Satisfaction and just show you the essentials. First, get the labels for the items:
# Convert Job Satisfaction items to numeric values
## Check levels for a likert5 item
analytic_data_survey |>
pull(job_aff1_likert5) |>
unique()## [1] "Strongly Agree" "Neutral"
## [3] "Strongly Disagree" "Agree"
## [5] "Disagree"Second, create the ordered factor labels:
## write code to create ordered factor labels/levels
likert5_factor <- c("Strongly Disagree",
"Disagree",
"Neutral",
"Agree",
"Strongly Agree")Third, convert the columns to a factor and then to numbers.
8.4.3.6 Scale scores
For each person, scale scores involve averaging scores from several items to create an overall score. The first step in the creation of scales is correcting the values of any reverse-keyed items.
8.4.3.6.1 Reverse-key items
A complete discussion of the logic for flipping reverse-key (i.e., reverse worded) items is provide the previous chapter in the Scale Scores section. We use that logic in the script below.
# Reverse key items
## Reverse key likert7 items
analytic_data_survey <- analytic_data_survey |>
mutate(8 - across(.cols = ends_with("_likert7rev")) ) |>
rename_with(.fn = str_replace,
.cols = ends_with("_likert7rev"),
pattern = "_likert7rev",
replacement = "_likert7")You can see that are all keyed in the right direction now.
## Rows: 150
## Columns: 26
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 1953, …
## $ sex <fct> female, female, female, male, …
## $ aff_com1_likert7 <dbl> 5, 4, 2, 7, 1, 6, 6, 2, 4, 2, …
## $ aff_com2_likert7 <dbl> 5, 3, 4, 2, 6, 7, 2, 3, 2, 7, …
## $ aff_com3_likert7 <dbl> 7, 4, 6, 3, 1, 6, 2, 5, 3, 4, …
## $ aff_com4_likert7 <dbl> 6, 1, 2, 2, 5, 3, 1, 2, 1, 6, …
## $ aff_com5_likert7 <dbl> 7, 4, 2, 3, 5, 1, 3, 1, 3, 3, …
## $ aff_com6_likert7 <dbl> 6, 7, 1, 7, 5, 6, 5, 7, 4, 2, …
## $ contin_com1_likert7 <dbl> 7, 4, 1, 3, 2, 1, 1, 6, 7, 3, …
## $ contin_com2_likert7 <dbl> 5, 5, 3, 2, 7, 6, 1, 3, 5, 2, …
## $ contin_com3_likert7 <dbl> 1, 3, 7, 7, 5, 2, 7, 2, 7, 1, …
## $ contin_com4_likert7 <dbl> 6, 4, 3, 7, 7, 5, 4, 5, 3, 2, …
## $ contin_com5_likert7 <dbl> 5, 5, 1, 4, 4, 6, 5, 5, 5, 2, …
## $ contin_com6_likert7 <dbl> 2, 2, 1, 4, 7, 7, 6, 6, 4, 5, …
## $ norm_com1_likert7 <dbl> 4, 5, 2, 5, 5, 2, 3, 1, 5, 1, …
## $ norm_com2_likert7 <dbl> 2, 6, 1, 5, 3, 2, 3, 1, 7, 1, …
## $ norm_com3_likert7 <dbl> 4, 4, 7, 3, 1, 1, 4, 3, 3, 5, …
## $ norm_com4_likert7 <dbl> 2, 2, 1, 6, 4, 6, 1, 1, 5, 5, …
## $ norm_com5_likert7 <dbl> 1, 1, 1, 5, 7, 4, 3, 6, 4, 4, …
## $ norm_com6_likert7 <dbl> 7, 1, 2, 4, 6, 6, 1, 4, 6, 2, …
## $ job_aff1_likert5 <dbl> 5, 5, 3, 1, 1, 3, 4, 4, 1, 4, …
## $ job_aff2_likert5 <dbl> 1, 5, 5, 2, 3, 1, 3, 3, 5, 5, …
## $ job_aff3_likert5 <dbl> 3, 1, 2, 5, 5, 3, 3, 1, 5, 2, …
## $ job_aff4_likert5 <dbl> 2, 5, 4, 1, 5, 3, 1, 3, 3, 5, …
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,…None of the job satisfaction items were reverse-keyed.
8.4.3.6.2 Creating scores
Important: Take note of how we name the scale variables (e.g., affective_commitment) with a different prefix than the items (e..g, aff_com1_likert7). This allows us to delete the items (i.e., columns that start with aff_com) but not the final scale score (i.e., a column starts with affective_commitment). This example again illustrates how carefully you need to think about your column and scale naming conventions.
# Create scale scores
## mutate commands create scale scores
## select commands with "-" remove items after scale creation
analytic_data_survey <- analytic_data_survey |>
rowwise() |>
mutate(affective_commitment = mean(c_across(starts_with("aff_com")),
na.rm = TRUE)) |>
mutate(continuance_commitment = mean(c_across(starts_with("contin_com")),
na.rm = TRUE)) |>
mutate(normative_commitment = mean(c_across(starts_with("norm_com")),
na.rm = TRUE)) |>
mutate(job_satisfaction = mean(c_across(starts_with("job_aff")),
na.rm = TRUE)) |>
ungroup() |>
select(-starts_with("aff_com")) |>
select(-starts_with("contin_com")) |>
select(-starts_with("norm_com")) |>
select(-starts_with("job_aff")) We can see our data now has the columns: affective_commitment, continuance_commitment, normative_commitment, job satisfaction.
As well, all of the items used to create the scale scores have been removed.
## Rows: 150
## Columns: 8
## $ duration_in_seconds <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ year_of_birth <dbl> 1961, 2006, 2008, 1985, 195…
## $ sex <fct> female, female, female, mal…
## $ participant_id <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, …
## $ affective_commitment <dbl> 6.000, 3.833, 2.833, 4.000,…
## $ continuance_commitment <dbl> 4.333, 3.833, 2.667, 4.500,…
## $ normative_commitment <dbl> 3.333, 3.167, 2.333, 4.667,…
## $ job_satisfaction <dbl> 2.75, 4.00, 3.50, 2.25, 3.5…8.4.4 Complete script
The complete script script_qualtrics.R for the data file data_qualtrics.csv is presented below.
# Date: YYYY-MM-DD
# Name: your name here
# Example: Single occasion survey
# Load data
library(tidyverse)
library(janitor)
library(skimr)
# read the file in the normal way and get just the names of the columns.
# put the names into the col_names
survey_file <- "data_qualtrics.csv"
col_names <- names(read_csv(survey_file,
n_max = 0,
show_col_types = FALSE))
# skip the first 3 rows than read in the data and use names from above
raw_data <- read_csv(survey_file,
col_names = col_names,
skip = 3,
show_col_types = FALSE)
# list of Qualtrics columns you probably don't want
cols_to_maybe_remove <- c("StartDate",
"EndDate",
"Status",
"IPAddress",
"Progress",
"Finished",
"RecordedDate",
"ResponseId",
"RecipientLastName",
"RecipientFirstName",
"RecipientEmail",
"ExternalReference",
"LocationLatitude",
"LocationLongitude",
"DistributionChannel",
"UserLanguage")
# check to see overlap with actual column names in data file
# put names to remove (that are present) into cols_to_remove
cols_to_remove_id <- col_names %in% cols_to_maybe_remove
cols_to_remove <- col_names[cols_to_remove_id]
# remove the unwanted Qualtrics columns
raw_data <- raw_data |>
select(!all_of(cols_to_remove))
analytic_data_survey <- raw_data
# Initial cleaning
## Convert column names to tidyverse style guide
## Remove empty rows and columns
analytic_data_survey <- analytic_data_survey |>
remove_empty("rows") |>
remove_empty("cols") |>
clean_names()
glimpse(analytic_data_survey)
# Convert variables to factors as needed
## Convert sex to factor
analytic_data_survey <- analytic_data_survey |>
mutate(sex = as_factor(sex))
## Participant identification to factor
## Participant identification column must be created first
## get the number of rows in the data set
N <- dim(analytic_data_survey)[1]
## create set of factor levels
participant_id_levels <- factor(seq(1, N))
## put the factor levels into a column called participant_id
analytic_data_survey <- analytic_data_survey |>
mutate(participant_id = participant_id_levels)
# Screen factors
## screen
analytic_data_survey |>
select(sex) |>
summary()
## change to desired order
analytic_data_survey <- analytic_data_survey |>
mutate(sex = fct_relevel(sex,
"female",
"intersex",
"male"))
# Screen numeric variables
analytic_data_survey |>
select(year_of_birth) |>
skim()
# Convert Commitment items to numeric values
## Check levels for a likert7 item
analytic_data_survey |>
pull(aff_com1_likert7) |>
unique()
## write code to create ordered factor labels/levels
likert7_factor <- c("Strongly Disagree",
"Moderately Disagree",
"Slightly Disagree",
"Neither Agree nor Disagree",
"Slightly Agree",
"Moderately Agree",
"Strongly Agree")
## assign factor levels and then covert to numeric
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert7"),
.fns = ~ factor(.x, levels = likert7_factor))) |>
mutate(across(.cols = contains("likert7"),
.fns = as.numeric))
# Convert Job Satisfaction items to numeric values
## Check levels for a likert5 item
analytic_data_survey |>
pull(job_aff1_likert5) |>
unique()
## write code to create ordered factor labels/levels
likert5_factor <- c("Strongly Disagree",
"Disagree",
"Neutral",
"Agree",
"Strongly Agree")
## assign factor levels and then covert to numeric
analytic_data_survey <- analytic_data_survey |>
mutate(across(.cols = contains("likert5"),
.fns = ~ factor(.x, levels = likert5_factor))) |>
mutate(across(.cols = contains("likert5"),
.fns = as.numeric))
# Reverse key items
## Reverse key likert7 items
analytic_data_survey <- analytic_data_survey |>
mutate(8 - across(.cols = ends_with("_likert7rev")) ) |>
rename_with(.fn = str_replace,
.cols = ends_with("_likert7rev"),
pattern = "_likert7rev",
replacement = "_likert7")
## No likert5 items are reverse-keyed but if they were
## You would adapt the code above replacing 8 (one higher than 7) to 6 (one higher than 5)
# Create scale scores
## mutate commands create scale scores
## select commands with "-" remove items after scale creation
analytic_data_survey <- analytic_data_survey |>
rowwise() |>
mutate(affective_commitment = mean(c_across(starts_with("aff_com")),
na.rm = TRUE)) |>
mutate(continuance_commitment = mean(c_across(starts_with("contin_com")),
na.rm = TRUE)) |>
mutate(normative_commitment = mean(c_across(starts_with("norm_com")),
na.rm = TRUE)) |>
mutate(job_satisfaction = mean(c_across(starts_with("job_aff")),
na.rm = TRUE)) |>
ungroup() |>
select(-starts_with("aff_com")) |>
select(-starts_with("contin_com")) |>
select(-starts_with("norm_com")) |>
select(-starts_with("job_aff"))
glimpse(analytic_data_survey)8.5 Where this is going
Take a moment to appreciate what you have built. The script above is reproducible: anyone with your raw data file and this script can recreate your analytic data exactly, with no manual steps and nothing done by hand in Excel. That is a real accomplishment and the foundation everything else rests on.
But notice something else. Everything you just wrote lives in one long file. For a single survey that is perfectly fine. As your projects grow, though, a single long script becomes harder to navigate, harder to debug, and harder to trust: when something goes wrong, you have to hunt through the whole file to find it, and every time you make a small change you re-run the entire thing from the top. There is also no structure separating your sacred raw data from the processed data you create along the way.
The next three chapters fix exactly these problems. In Chapter 9 we take this very script and break it into a tidy, structured project — small numbered stages, each doing one job, organized into folders, run by a single master script. In Chapter 10 we go one step further and let a tool manage the whole pipeline for us, re-running only the parts that actually changed. And in Chapter 11 we learn how to start a brand-new project already organized this way, so you never have to clean up a mess after the fact. The road map in Figure 8.1 is your guide for the whole journey.
8.6 Extra Help
8.6.1 Qualtrics
University of Guelph Qualtrics Login page
University of Guelph Qualtrics FAQ page