Chapter 4 Populations
4.1 Notation
In this chapter we will use summation notation. If you are not familiar with summation notation, we present a brief overview here.
Consider a scenario where we have IQ data for three participants We use the symbol N to represent the number of participants. Because we have three participants N = 3. Here \(N\) refers to the total number of elements in the set under consideration — whether that’s a small teaching example or a true population. The data for these participants is illustrated in Figure 4.1.
Notice how each person in the data set can be represented by the variable X: the first person by \(X_1\), the second by \(X_2\), and the third by \(X_3\). Often we refer to individuals in a data set by using the variable X accompanied by a subscript (e.g., 1, 2, 3, etc.).
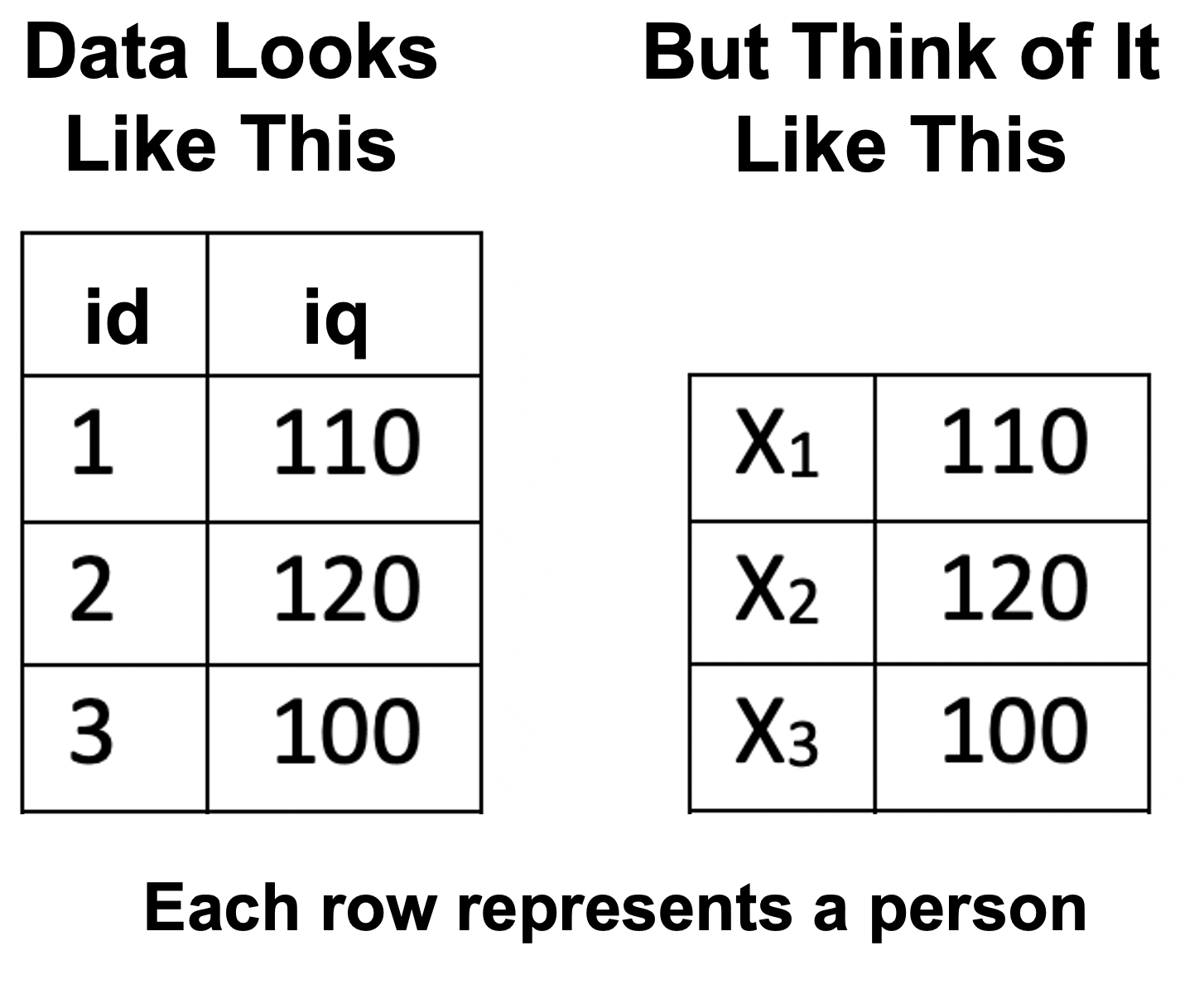
FIGURE 4.1: Data for understanding summation notation
Referring to participants using the variable X and subscript is valuable because it can be used in conjunction with the sigma (i.e., \(\Sigma\)) symbol for summation. Consider the example below in which we use the summation notation to indicate that we want to add all the X values (representing IQ) for the participants. We use a lower case \(i\) to represent all possible subscript values. The notation, \(i\) = 1, below the \(\Sigma\) symbol indicates that we should start with participant 1. The notation, N, above the \(\Sigma\) symbol indicates that we should iterate \(i\) up to the value indicated by N; in this case 3, because there are three participants.
\[ \begin{aligned} \sum_{i=1}^{N} X_i &= X_1 + X_2 + X_3\\ &= 110 + 120 + 100 \\ &= 330 \end{aligned} \]
Sometimes, to simplify the notation, the numbers above and below the \(\Sigma\) symbol are omitted. Likewise, the \(i\) subscript is omitted. There is a general understanding that when these components of the notation are omitted the version of the notation above is implied.
\[ \begin{aligned} \sum{X} &= X_1 + X_2 + X_3\\ &= 110 + 120 + 100\\ &= 330 \end{aligned} \]
Calculating a mean. The full version of the notation can be used to indicate how an average/mean is calculated.
\[ \begin{aligned} \bar{X} &= \frac{\sum_{i=1}^{N} X_i}{N} \\ &= \frac{X_1 + X_2 + X_3}{3}\\ &= \frac{110 + 120 + 100}{3}\\ &= \frac{330}{3}\\ &= 110\\ \end{aligned} \]
Likewise, the concise version of the notation can be used to indicate how an average/mean is calculated.
\[ \begin{aligned} \bar{X} &= \frac{\sum{X}}{N} \\ &= \frac{X_1 + X_2 + X_3}{3}\\ &= \frac{110 + 120 + 100}{3}\\ &= \frac{330}{3}\\ &= 110\\ \end{aligned} \]
Calculating squared differences. A common task in statistics is to calculate 1) the squared difference between each person and the mean, and 2) add up those squared differences. This calculation is easily expressed with the full version of the notation.
\[ \begin{aligned} \sum_{i=1}^{N}{(X_i - \bar{X})^2} &= (X_1-\bar{X})^2 + (X_2-\bar{X})^2 + (X_3-\bar{X})^2\\ &= (110-110)^2 + (120-110)^2 + (100-110)^2\\ &= (0)^2 + (10)^2 + (-10)^2 \\ &= 0 + 100 + 100 \\ &= 200 \end{aligned} \]
Likewise, the sum of the squared differences from the mean can be expressed using the concise version of the notation.
\[ \begin{aligned} \sum{(X - \bar{X})^2} &= (X_1-\bar{X})^2 + (X_2-\bar{X})^2 + (X_3-\bar{X})^2\\ &= (110-110)^2 + (120-110)^2 + (100-110)^2\\ &= (0)^2 + (10)^2 + (-10)^2 \\ &= 0 + 100 + 100 \\ &= 200 \end{aligned} \]
Why do we use squared differences instead of just differences? Well, there are many reasons and it’s too early to discuss them in detail. However, one easy to understand reason for using squared differences is that the if we were to just use differences (not squared) we would end up with a value of zero, as illustrated below. Which might be interpreted (incorrectly) as suggesting there is no variability in the numbers - when clearly there is variability. However, the full reasons for using squared differences are more complex than this simple example illustrates.
\[ \begin{aligned} \sum{(X - \bar{X})} &= (X_1-\bar{X}) + (X_2-\bar{X}) + (X_3-\bar{X})\\ &= (110-110) + (120-110) + (100-110)\\ &= (0) + (10) + (-10) \\ &= 0 \\ \end{aligned} \]
4.2 Population vs samples
As we move closer to conducting our own research it is critical to make a distinction between populations and samples. A population is the complete set of people/animals about which we want to make conclusions. A sample is a randomly selected subset of the population.
In most scenarios it is impractical to work with an entire population. When you want to obtain data from an entire population, you need a census which is extraordinarily expensive. Even the Canadian government only does a census every 5 years due to the cost. Consequently, for practical reasons, researchers typically study a subset of the population called a sample. We use the sample to estimate what is true at the population level.
Researchers, and consumers of research, typically have little interest in making conclusions at the sample level. In general, we care about conclusions that generalize to the population but not conclusions that only apply to only the individuals in the sample. Consider the case of COVID-19. Imagine a research team creates a vaccine that they hope generates immunity to COVID-19. We care very little if the immunity only works for the specific individuals in the study. However, we care a great deal if the immunity works, or is likely to work, for all Canadians (a possible population) or all humans (a larger possible population). We study samples but typically wish to make conclusions that apply to a population. Thus, even if you are an experimental researcher it is critical that you think in terms of populations and not samples. Indeed, statistical tests (such as the t-test) are a means of helping researchers use sample data to make conclusions at the population level.
In this chapter, our focus is on describing populations. When we calculate a number that summarises an attribute of all of the people/animals in the population we refer to it as a parameter.
4.3 A small population
In this section we review how to calculate three commonly used population parameters (mean, variance, and standard deviation). Populations are typically quite large but for simplicity we focus on a population composed of the weights of just three chocolate chip cookies. We refer to the three cookies as \(X_1\), \(X_2\), and \(X_3\). The cookies have the weights of 8, 10, and 12 grams, respectively.
4.3.1 Mean (\(\mu\))
It can be helpful to create a model that describes our data. Of course, the model won’t describe every participant perfectly and each participant will differ to some extent from the model.
Model: To create a model we first need data, which in this example will be the weight of three different chocolate chip cookies. As mentioned previously, the weights of the three cookies are designated by \(X_1\), \(X_2\), and \(X_3\). A simple model for our cookie weight data is the mean. At the population level the mean is represented by the symbol \(\mu\) see Formula (4.1) below. At the sample level a different notation is used.
\[\begin{equation} \mu = \frac{\sum{X}}{N} \tag{4.1} \end{equation}\]Using that equation with values:
\[ \begin{aligned} \mu &= \frac{\sum{X}}{N} \\ &= \frac{X_1 + X_2 + X_3}{3}\\ &= \frac{8 + 10 + 12}{3}\\ &= \frac{30}{3}\\ &= 10\\ \end{aligned} \]
We can think of the “mean cookie” as our model for our cookie weight data, see Figure 4.2. The “mean cookie” is represented by \(\mu\) in equations.

FIGURE 4.2: Variance as a fit index for the mean
Error: As mentioned previously, each participant (i.e., cookie) differs to some extent from our model (“mean cookie”). In general this can be conceptualized as:
\[ \begin{aligned} X_i &= model + error_i \\ \end{aligned} \]
More specifically, the difference between the weight of any individual cookie (\(X_i\)) and the model (\(\mu\)) is indicated by \(error_i\) as shown below.
\[ \begin{aligned} X_i &= \mu + error_i \\ \end{aligned} \]
The model, above is just a concise way of describing the following:
\[ \begin{aligned} X_1 &= \mu + error_1 \\ X_2 &= \mu + error_2 \\ X_3 &= \mu + error_3 \\ \end{aligned} \]
That is the weights of the three cookies (\(X_1 = 8\), \(X_2 = 10\), and \(X_3 = 12\)) can be conceptualized as:
\[ \begin{aligned} X_1 &= 10 + (-2) \\ X_2 &= 10 + 0 \\ X_3 &= 10 + 2 \\ \end{aligned} \]
The mean/average of the population, \(\mu = 10\), is a parameter that serves as a model for the cookie weight data. However, it’s helpful to have an index, known as variance, that indicates the extent to which the data do not correspond to the model from the model.
4.3.2 Variance (\(\sigma^2\))
Variance is a simple way of calculating a single number to represent how data differ from a model. It is represented, at the population level, by the symbol \(\sigma^2\); a different notation is used at the sample level.
Previously, how we expressed the difference/deviation of cookie weights (data) from the model (i.e., mean) with an error term in the equation \(X_i = \mu +error_i\), see Figure 4.2. The model for all the cookies is \(\mu = 10\). If we consider a single cookie weight of 8 grams (a data point represented by \(X_1\)), the difference between the cookie from the model is -2 (i.e., error):
\[ \begin{aligned} X_1 &= 10 + (-2) \\ \end{aligned} \]
We want a number that indicates the quality of the cookie model. Specifically, we want a single number that indexes overall how the data (i.e., cookie weights) differ from the model (i.e., the mean cookie). We refer to that index as variance (\(\sigma^2\)).
Calculating Squared Differences/Errors. To calculate variance (\(\sigma^2\)), we use the errors for the cookies – how the cookies differ from the mean/model. The first step is to square the errors/differences Those squared numbers are referred to as the “squared differences” or “squared errors”. The calculation of the squared error for each cookie weight is shown below. The squared errors (or squared differences) are 4, 0, and 4.
| Cookie Weight | Model | Squared Difference/Error |
|---|---|---|
| \(X_1 = 8\) | \(\mu = 10\) | \((X_1 - \mu)^2 =(8 - 10)^2= 4\) |
| \(X_2 = 10\) | \(\mu = 10\) | \((X_2 - \mu)^2 =(10 - 10)^2= 0\) |
| \(X_3 = 12\) | \(\mu = 10\) | \((X_3 - \mu)^2 =(12 - 10)^2= 4\) |
Averaging Squared Errors. To obtain variance we calculate the average of the squared errors. At the population level the variance is represented by the symbol \(\sigma^2\) (Formula (4.2) below), where \(N\) refers to the number of elements in the population. Important: In sample data, the formula changes — we use \(n-1\) in the denominator instead of \(n\) (or \(N\)) to correct for bias in estimating the population variance.
\[\begin{equation} \sigma^2 = \frac{\sum{(X - \mu)^2}}{N} \tag{4.2} \end{equation}\]Using that equation with values:
\[ \begin{aligned} \sigma^2 &= \frac{\sum{(X - \mu)^2}}{N}\\ &= \frac{(X_1-\mu)^2 + (X_2-\mu)^2 + (X_3-\mu)^2}{N} \\ &= \frac{(8-10)^2 + (10-10)^2 + (12-10)^2}{3}\\ &= \frac{(-2)^2 + (0)^2 + (2)^2}{3} \\ &= \frac{4 + 0 + 4}{3} \\ &= \frac{8}{3} \\ &= 2.67 grams^2 \\ \end{aligned} \]
The resulting variance is 2.67 grams\(^2\). The cookie weights were measured in grams. The unit for variance, however, is grams\(^2\) because we squared the errors as part of the calculation. Recall the formula for calculating an average (shown below) and compare it to the variance calculation (above). Notice that variance is just an average – an average of squared errors. Correspondingly, in some areas of statistics they don’t use the term variance, they use a synonym - mean squared error.
\[ \begin{aligned} \bar{X} &= \frac{\sum{X}}{N} \\ \end{aligned} \]
It probably strikes you as an odd choice to square the difference between each data point and the model. Why not just use the difference (e.g., \((8 - 10) = -2\)) when calculating variance? Why not use the absolute difference (e.g., \(|8 - 10|= 2\)) when calculating variance? The answer is somewhat complex, but it relates to the more general situation in statistics of trying to find models that best fit the data (which occurs by minimizing errors). When we use squared errors it is easier to apply calculus, via derivatives, to calculate a model that minimizes the errors (i.e., obtains the best fit). Long story short, for complex mathematical reasons, we use squared errors, (rather than just errors) when calculating the fit (or lack of fit) of a model.
Interpretation. A variance of zero indicates that the model fits the data perfectly. In the cookie case, if the variance was zero, that would indicate that all the cookies had the same weight as the model, exactly 10 grams. To the extent that the variance is larger than zero it implies the data points (i.e., cookie weights) differ from the model (i.e., the mean cookie). By implication, a larger variance indicates larger differences among the observations (e.g., cookie weights). That is, when the variance is small, cookie weights tend to be similar to the model – and each other. In contrast, when the variance is large, cookie weights tend to be different from the model – and each other.
4.3.3 Standard Deviation (\(\sigma\))
An alternative index for how data differ from the mean/model is the standard deviation. To understand standard deviation you have to understand variance. Variance is a single number that indexes how data differ from a model. The interpretation of variance is straightforward. It is the average of the squared differences/errors between the data and the model.
Standard deviation is represented by the symbol \(\sigma\) and can be calculated as the square root of variance as in Formula (4.3) below.
\[\begin{equation} \sigma = \sqrt{\frac{\sum{(X - \mu)^2}}{N}} \tag{4.3} \end{equation}\]Using that equation with values:
\[ \begin{aligned} \sigma &= \sqrt{\frac{\sum{(X - \mu)^2}}{N}}\\ &= \sqrt{\sigma^2} \\ &= \sqrt{2.67} \\ &= 1.63 grams\\ \end{aligned} \]
One reason that people like standard deviation is that it presents the difference between the data and the model in the original units (e.g., grams). This is in contrast to variance which presents the difference betweeen the data and the model in squared units (e.g., 2.67 grams\(^2\)).
Interpretation. Unfortunately, although variance has a straight forward interpretation, standard deviation does not. Sometimes standard deviation is, incorrectly, described as how much data points differ on average from the mean. A quick calculation of the average difference reveals a number (1.33) that does not correspond to the standard deviation (1.63):
\[ \begin{aligned} \overline{diff} &= \frac{\sum{|X - \mu|}}{N}\\ &= \frac{|8-10| + |10-10| + |12 - 10|}{3}\\ &= \frac{2 + 0 + 2}{3}\\ &= \frac{4}{3}\\ &= 1.33\\ \end{aligned} \]
As illustrated above, standard deviation is not equal to the average of the deviations from the mean (mean absolute deviation, or MAD). The two are related but will only match when variance is zero. MAD can be easier to explain to non-technical audiences, but SD is more useful mathematically because of its connection to variance and inferential statistics. Because standard deviation is not an average, it’s much harder to describe how to interpret it. In our view, the best way to think of standard deviation is simply as the square root of variance; because variance has a straight forward interpretation.
Therefore, we encourage you to think primarily in terms of variance rather than standard deviation due to the fact the interpretation of variance is more straightforward. Additionally, variance is foundational in the language used to describe regression and analysis of variance. That said, standard deviation is used in the calculation of some standardized effect sizes - so it is important to know and understand both indices.
Overall, the rules for interpreting standard deviation are similar to those for variance; but the standard deviation values are smaller than variance values. In the cookie case, if the standard deviation was zero, that would indicate that all the cookies had the same weight as the model, exactly 10 grams. To the extent that the standard deviation is larger than zero it implies the data points (i.e., cookie weights) differ from the model (i.e., the mean cookie). By implication, a larger standard deviation indicates larger differences among the observations (e.g., cookie weights). That is, when the standard deviation is small, cookie weights tend to be similar to the model – and each other. In contrast, when the standard deviation is large, cookie weights tend to be different from the model – and each other.
4.4 Visualizing populations
Populations are typically quite large in nature and it’s often imposssible to practically list all of the members of the population. Consequently, it helps to have ways to visualize the entire population. In Figure 4.3 we present three ways of visualizing a population. In all three graphs (A, B, C) in this figure the x-axis represents heights in centimeters and the y-axis is used to indicate which values on the x-axis are more common. In Figure 4.3A we use a large number of X’s to indicate the members of the population. Because X’s are also used in formulas to represent individual participants, a strength of this graph is that it reminds you that it is a graph reflecting a large number of individuals. In Figure 4.3B we present a standard histogram that illustrates the distribution of heights. In Figure 4.3C we present a density curve that illustrates the distribution of heights. All three approaches are useful for illustrating that most people have heights around 170 cm.
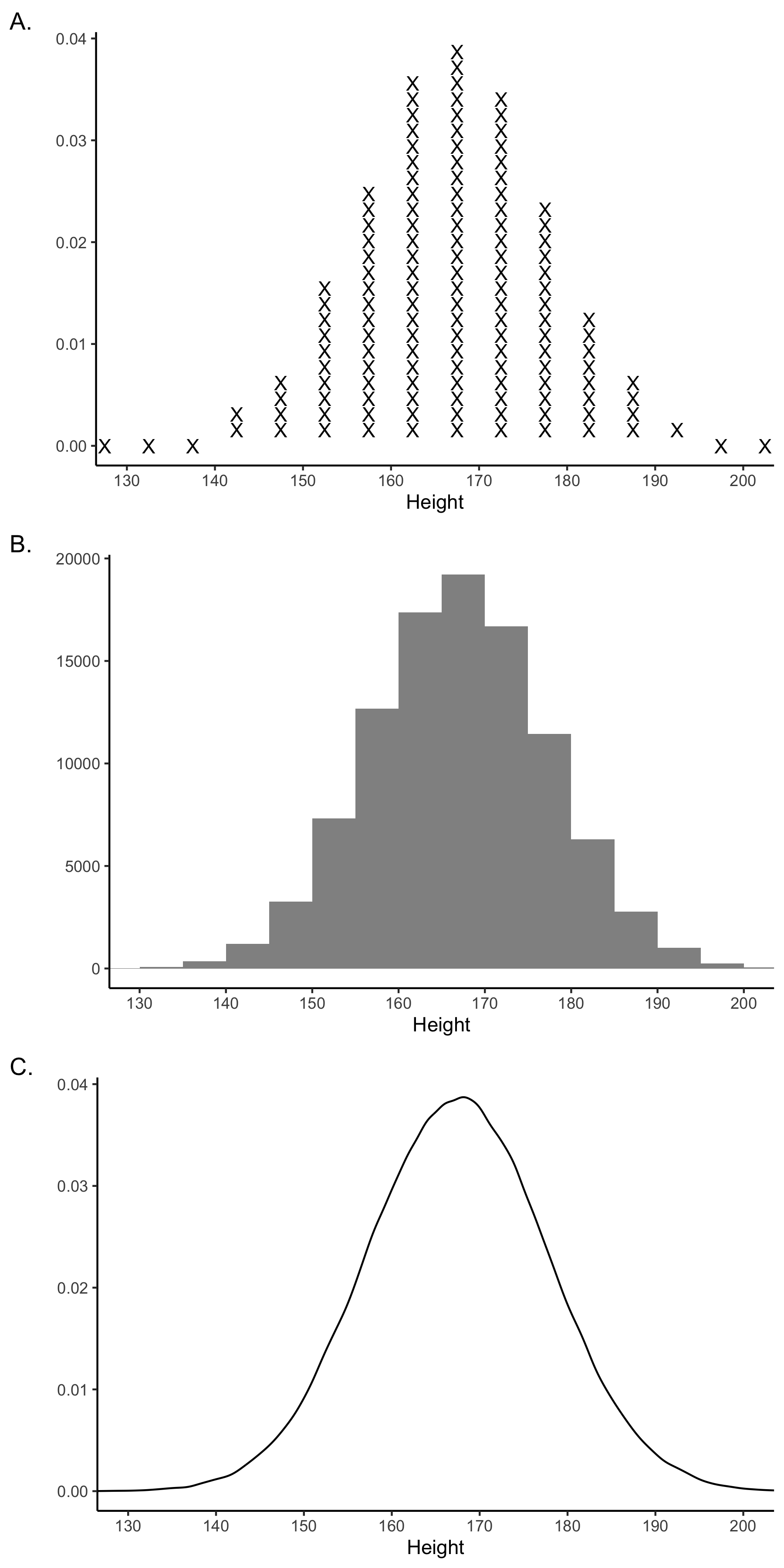
FIGURE 4.3: Three ways of visualizing a population distribution
4.5 Comparisons: Same \(\sigma\)
In this section we review a method of comparing two population means when the populations have the same standard deviation. To facilitate comparing two populations we use the heights of males and females, measured in centimeters, as an example. On average males are taller than females. There is, however, variability in the heights of both males and females. The variability in heights is the same for males and females even though the means differ. We illustrate these differences in a series of figures below. Each figure contains three scenarios (labeled A, B, C) in which we manipulate the mean height and variability of the populations. In each scenario the standard deviation of heights is the same for the male and female populations.
4.5.1 Standardized units
4.5.1.1 Individual scores
Often when we compare two means we use the original metric. In the case of the male and female heights that metric is centimeters. The original units are a useful way to convey information about the difference between two populations.
In addition to the original unit it is also possible, and sometimes desirable, to use the standardized mean difference. The word standardized is used to indicate that the comparison is relative to the standard deviation.
Imagine a population of male heights (\(\mu = 170\), \(\sigma = 10\)) from which we have obtained a single individual, Ian, whose height is 185 cm.
\[ X_{Ian} = 185cm \]
The original units are useful for describing Ian’s height but it doesn’t tell us about his height relative to the other people in the population. We have to know the mean and standard deviation of the population to know if Ian is shorter or taller than the average height - and by how much. We use a \(z\)-score calculation for this purpose:
\[ \begin{aligned} z_{Ian} &= \frac{X_{Ian} - \mu_{males}}{\sigma_{males}}\\ &= \frac{185 - 170}{10}\\ &= \frac{15}{10}\\ &= 1.50 \end{aligned} \]
The above calculation is a ratio. Ratios are used to compare two numbers. The numerator (number on the top) is compared to the denominator (number on bottom) through division. The resulting number tells you how much larger the numerator is than the denominator.
In this case, the numerator is the extent to which Ian is taller than the mean height for males (\(X_{Ian} - \mu_{males}\)). This numerator is compared to the denominator – which is the standard deviation for males (\(\sigma_{males}\)). The resulting number is 1.50 which indicates the numerator is 1.50 times larger than the denominator. In other words, Ian is 1.50 standard deviations taller than the average male. This is a standardized score for Ian’s height - it expresses the difference between his height and the mean height in standard deviation units.
4.5.1.2 Independent Group: Population Means
The same approach to generating standardized scores can be applied to population means. Consider a situation where we have population of male heights (\(\mu = 170\), \(\sigma = 10\)) and a population of female heights (\(\mu = 165\), \(\sigma = 10\)). Notice that both populations have the same standard deviation.
We can calculate a standardized value to compare these heights. This standardized value is called the standardized mean difference (SMD). Alternatively, it is also known as Cohen’s \(d\) which is represented at the population level with the symbol \(\delta\). Calculation of the standardized mean difference is based on the premise that both populations have the same standard deviation.
In this calculation the numerator represents the difference between the two population means. The denominator represents the population standard deviation - which is the same for both populations see Formula (4.4) below.
\[\begin{equation} \delta = \frac{\mu_{1} - \mu_{2}}{\sigma} \tag{4.4} \end{equation}\]Using that equation with values:
\[ \begin{aligned} \delta &= \frac{\mu_{males} - \mu_{females}}{\sigma}\\ &= \frac{170 - 165}{10}\\ &= \frac{5}{10}\\ &= 0.50 \end{aligned} \]
The resulting division of this ratio reveals that the numerator is 0.50 times as large (i.e., half as large) as the denominator. That is, the difference between the populations is half as large as the standard deviation. Therefore, the population mean for males is 0.50 standard deviations larger than the population mean for females; \(\delta = 0.50\):
4.5.2 Cohen’s \(d\) units
Because the unit for the standardized mean difference is the standard deviation it can be easy to interpret if you are unfamiliar with the original units. It is usually a good idea to report the difference between populations in both the original units (cm) and standardized units (\(\delta\)). Figure 4.4 illustrates three different population difference scenarios (A through C). The population standard deviation is held constant across the three scenarios. You can see that as the difference between the population means increases in raw units - it does the same in \(\delta\) (i.e., Cohen’s \(d\)) units. In raw units (i.e., cm), the difference between the population means for scenarios A through C are 5 cm, 10 cm, and 20 cm, respectively. In standardized units (i.e., standard deviations), the difference between the population means for scenarios A through C are 0.50 standard deviations, 1.0 standard deviations, and 2.0 standard deviations, respectively. In other words, the population-level Cohen’s \(d\)-values are 0.50, 1.0, and 2.0 for scenarios A through C.
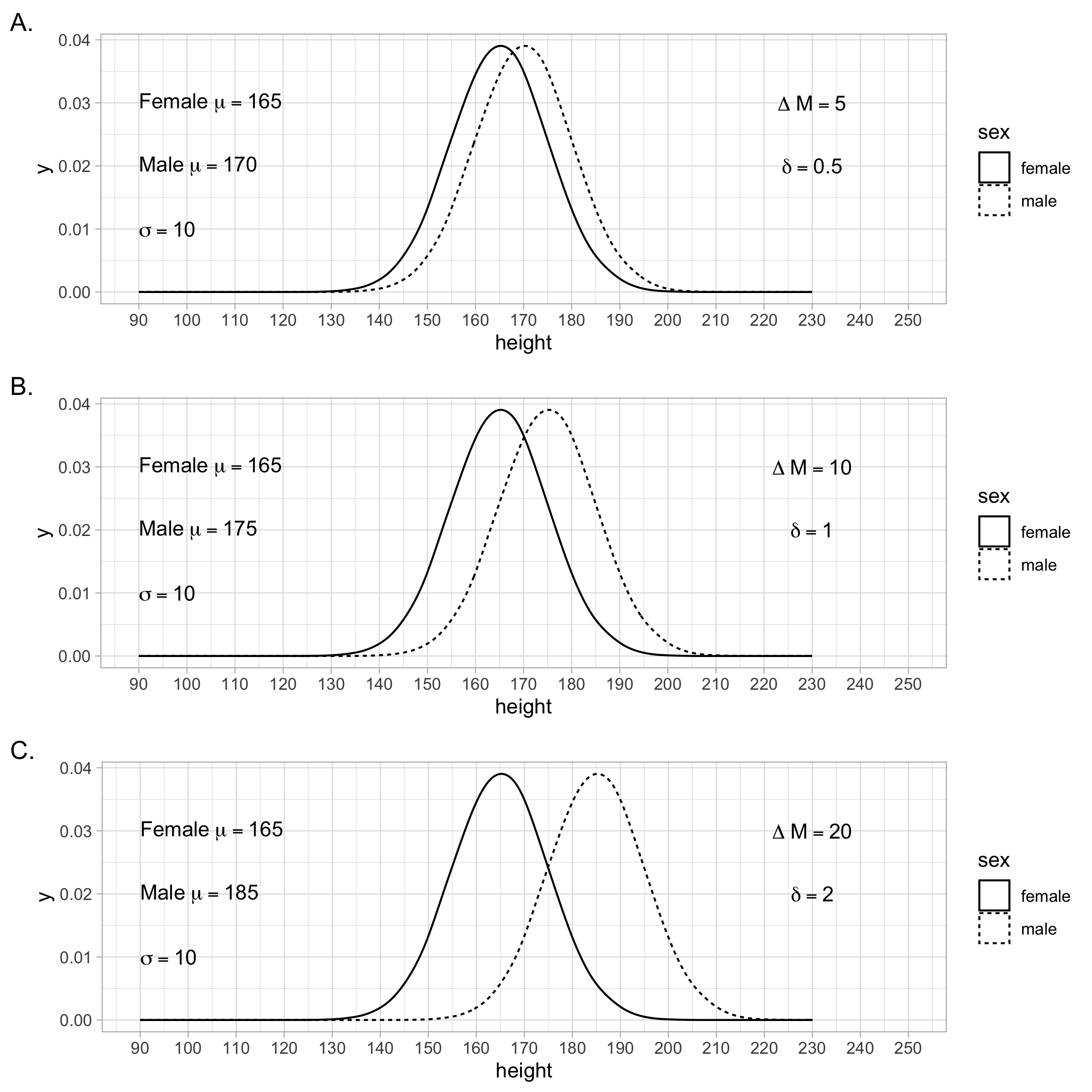
FIGURE 4.4: The difference between two population means can be expressed in the original units as indicated by \(\Delta M\). Alternatively, the difference can be expressed using a Standardized Mean Difference (SMD). The SMD index is also known as the population-level \(d\)-value and is represented by the symbol \(\delta\). The SMD is a way of expressing the difference between population means without using the original units.
4.5.3 Cohen’s \(d\) advantages
The standardized mean difference takes into account the variability of heights around each population mean. This means that the same difference between two population means can produce different standardized mean difference values if the population standard deviation varies. In the scenarios depicted in Figure 4.5 the population standard deviation becomes increasingly small - resulting in larger standardized mean difference values (i.e., \(\delta\)). This larger \(\delta\) value corresponds to progressively less overlap between the two populations. Thus, taking into account the standard deviation of the populations can be viewed as a strength of using the standardized mean difference.
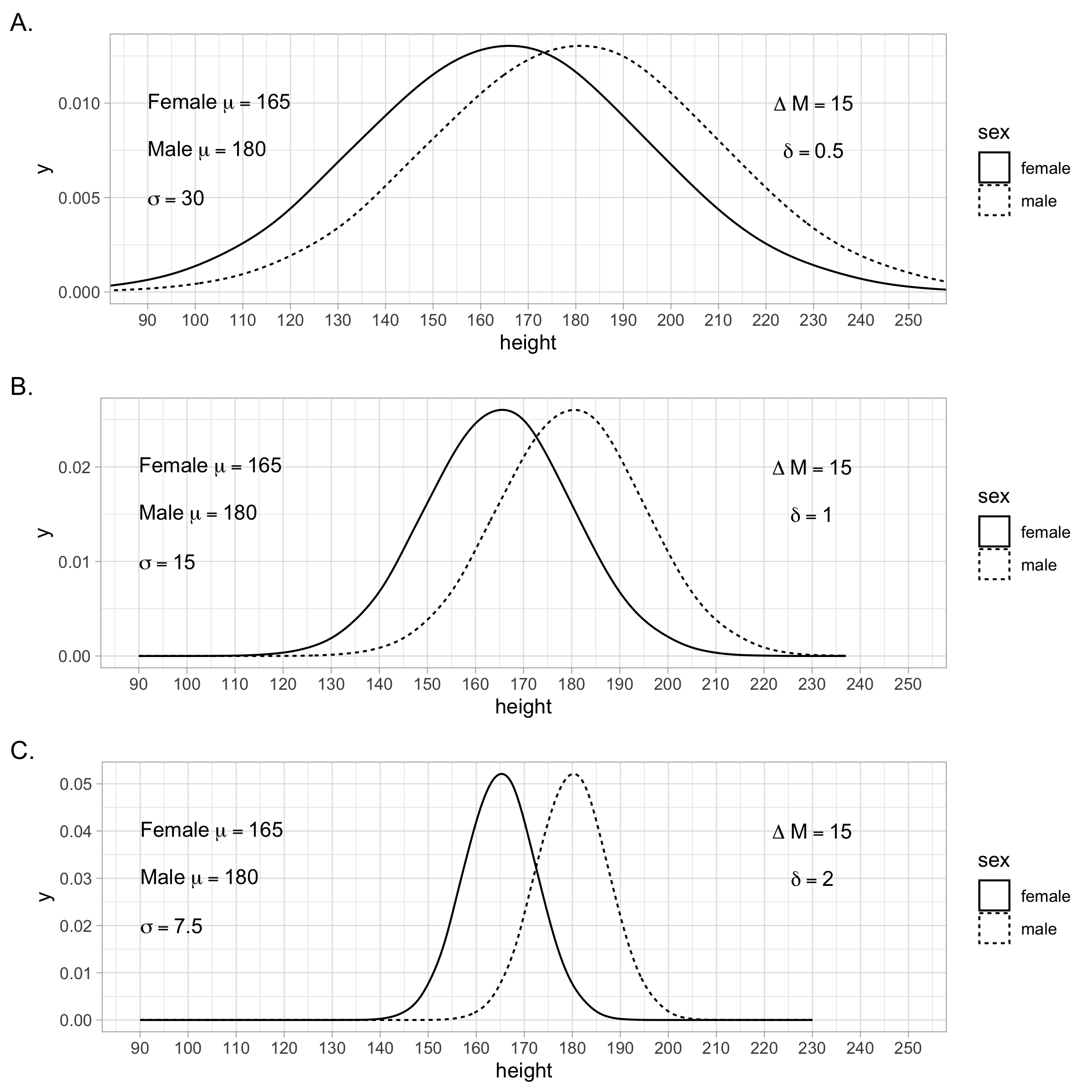
FIGURE 4.5: An advantage of using the Standardized Mean Difference (SMD) to index the difference between two population means (i.e., \(\delta\)) is that it takes the population standard deviation into account. In these three examples, the difference between the population means is the same using the original/raw units of centimeters. However, the standard deviation of the populations varies across scenarios A, B, and C. The SMD illustrates that these three scenarios are different. If you only examined the difference in the original units (i.e., \(\Delta M\)) you would conclude the effect is the same across the three scenarios. However, by using SMD, indexed by \(\delta\) - the population \(d\)-value, you see that the effect is progressively stronger from scenario A, to B, to C. This is illustrated by the fact that there is progressively less overlap between the distributions as you move from scenario A to C.
4.5.4 Cohen’s \(d\) caveats
It is important to also look at the original units when interpreting results - not just the standardized mean difference. Examine the scenarios in Figure 4.6. Notice how the \(\delta\) value stays constant across scenarios - as does the overlap of the two distributions. However, inspect the shape of the curves and the original units to see how the scenarios vary. Both the original units and the standardized mean difference (i.e., Cohen’s \(d\)) provide important interpretational information - don’t rely on just one of them.
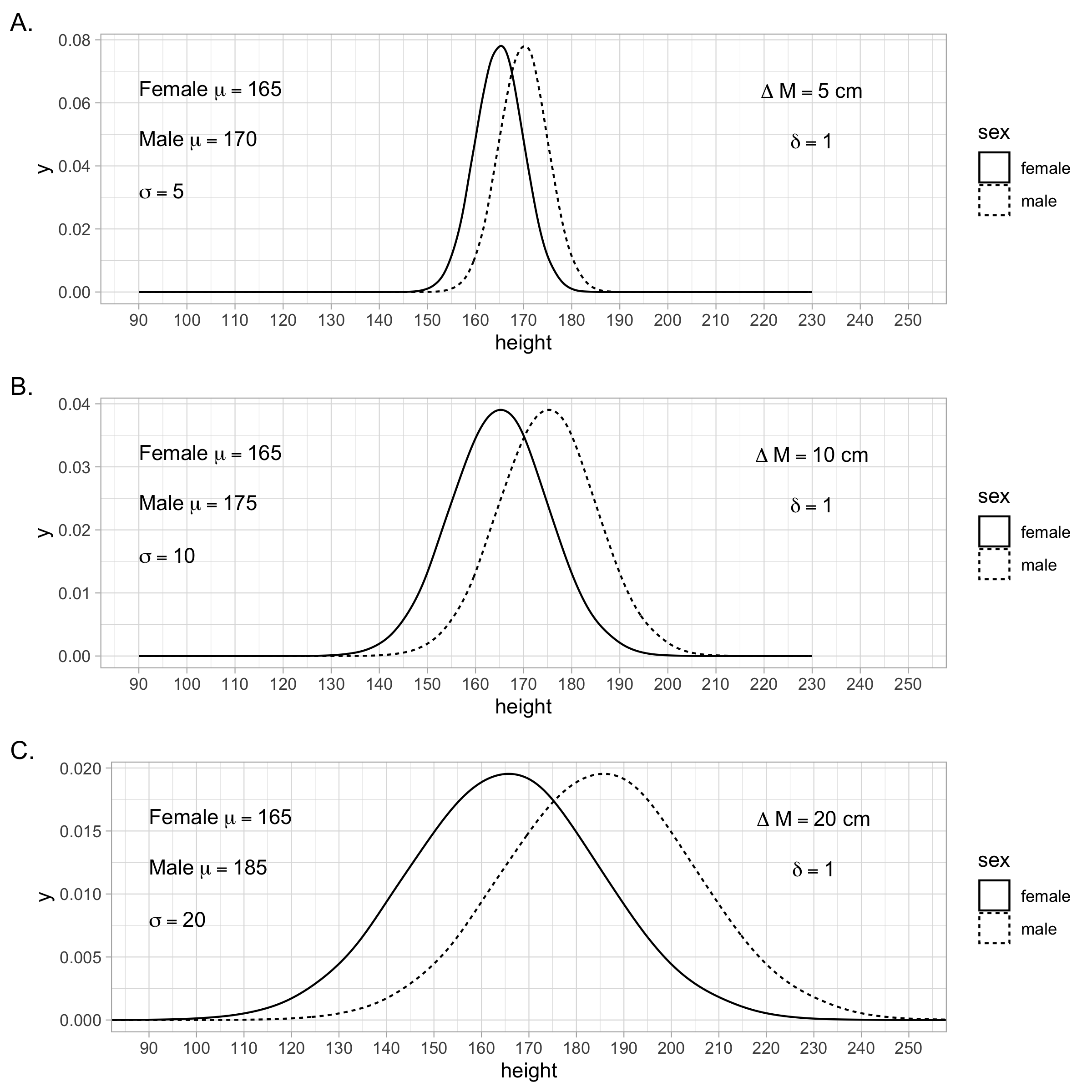
FIGURE 4.6: The three scenarios in this figure illustrate that a Standardized Mean Difference (i.e., population \(d\)-value or \(\delta\)) can remain constant across scenarios when there is a change in the raw difference (i.e., \(\Delta M\)) between the population means. This SMD is consistent across the three scenarios despite a change in the mean difference using original units; this occurs because the standard deviations also change across the three scenarios.
4.6 Comparisons: Different \(\sigma\)
The calculation of the standardized mean difference values (\(\delta\)-values) above assumed that the two populations had identical standard deviations. In some scenarios, you might reasonably expect the standard deviations to be different for two populations. When the populations being compared have different standard deviations, we can still calculate a standardized mean difference (i.e., \(\delta\)-value) but we need to pick one of the standard deviations to use in the formula. In many cases, it makes sense to think of one population as the frame of reference for the comparison; a “Control” population of sorts. In this case, you use the standard deviation of the control population as the reference/denominator when calculating the \(\delta\)-value, as illustrated in Formula (4.5) below. This version of the standardized mean difference is also known as Glass’s \(\Delta\), and is appropriate when one group’s variability (often the control group) is considered the baseline. Make sure you recognize we are talking about a scenario with different population standard deviations (not sample standard deviations) as the appropriate situation for this type of calculation.
\[\begin{equation} \delta = \frac{\mu_{1} - \mu_{2}}{\sigma_{control}} \tag{4.5} \end{equation}\]4.7 Comparisons: Repeated Measures
Sometimes we measures the members of a single population twice and are interested in the change across occasions. Consider a scenario where everyone in a large population (N = 1000000) attempts to lose weight over a given period of time. We weigh everyone in the population at time 1 before the weight loss attempt. Then we weigh everyone in the population at time 2 after the weight loss attempt.
Think of this scenario concretely with respect to how we would record this information. Imagine a large spreadsheet with 1000000 rows - each representing a person. There are two columns. The first column contains time 1 weights. The second column contains time 2 weights. We are interested in how weights changed across the times. So we create a third column, called diff, by subtracting time 1 weight from time 2 weights. That is, diff = time 2 weight - time 1 weight.
The new diff column indicates how the weights for each person have changed over the diet. We can think of this single column of differences as being a population. This column is used to calculate the repeated-measures \(\delta\)-value.
The new diff column indicates how the weights for each person have changed over the diet. We can think of this single column of differences as being a population.
This column is used to calculate the repeated-measures \(\delta\)-value, where \(\sigma_{\text{diff}}\) is the population standard deviation of the difference scores see Formula (4.6) below.
Note that For sample data, an analogous formula is used but will differ slightly. Specifically, the sample-level symbols for mean of the diff column (\(bar{x}_{diff}\)) and the standard deviation of the diff column (\(s_{diff}\)) are used in Formula (4.6) instead.
4.8 Comparison Benchmarks
Regardless of how the standardized mean difference (i.e., \(\delta\)-value) is calculated, Cohen suggested that the values of 0.20, 0.50, and 0.80 correspond to the effect size labels of small, medium, and large, respectively (Cohen 1988). These effect sizes are illustrated in Figure 4.7. As described in an interesting blog post, these benchmark values came from reviewing a single issue of the Journal of Abnormal and Social Psychology. Basing benchmarks on such a small number of studies is potentially problematic - as is the fact that at that time all the studies were prone to publication bias. A recent investigation (see Schäfer and Schwarz 2019) of effect sizes in pre-registered studies, with no publication bias, suggests substantially lower benchmark values.
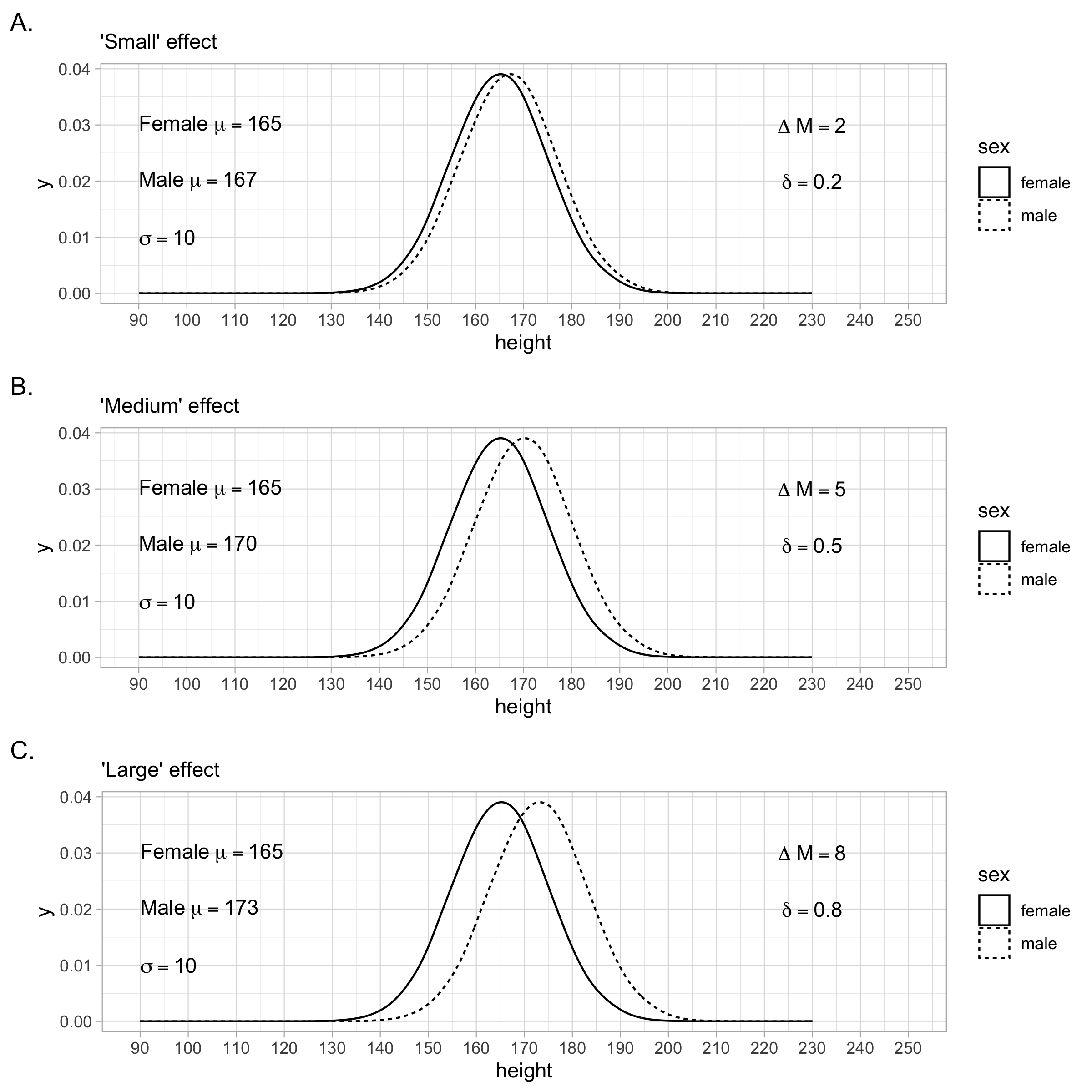
FIGURE 4.7: Cohen’s (1988) effect size benchmarks
You can visualize any \(\delta\) value (i.e., population \(d\)-value) using the rpsychologist website. This website also provides a number of interesting statistics such as the percentage of overlapping values in two populations for a given \(\delta\)/d value. Take a minute to use this website now.
Cohen’s benchmarks for standardized mean differences are displayed in the table below. These effect size labels should be interpreted with caution. The magnitude of an effect is best considered in the context of the field of research and the consequences of an effect on individuals in both the short and long run.
| Cohen (1988) Label | Value |
|---|---|
| Small | \(\delta\) = .20 |
| Medium | \(\delta\) = .50 |
| Large | \(\delta\) = .80 |
These refer to the magnitude of the correlation — the absolute value — regardless of whether it is positive or negative.
4.9 Population relations
Often researchers are interested in the extent to which one variable is related to another variable. For example, to what extent does variability in weight relate to variability in height? In other words, is there a relation between weight and height? One approach to this question is to calculate a regression equation relating weight to height - this provides an index of the relation in the original units of the variables. Here we focus on a second approach to describing the relation between variables, namely, the correlation. The correlation is standardized effect size for the linear relation between two variables.
A population correlation is represented by the symbol \(\rho\) (pronounced rho) and calculated using Formula (4.7) below. This is equivalent to \(\rho = \frac{\mathrm{Cov}(X,Y)}{\sigma_X \sigma_Y}\), which links correlation directly to the concept of covariance.
The correlation may range from -1.00 to 1.00. A strong negative correlation indicates that as one variable increases the other decreases. A positive correlation indicates that as one variable increases the other increases. There are at least thirteen ways to conceptualize a correlation (see Lee Rodgers and Nicewander 1988) but it’s easiest to think of it as an index of the extent to which the variables covary in a linear way.
\[\begin{equation} \rho = \frac{\Sigma (X - \mu_X)(Y - \mu_Y)}{\sqrt{\Sigma (X - \mu_X)^2\Sigma (Y - \mu_Y)^2}} \tag{4.7} \end{equation}\]Because a correlation only provides an index of a linear relation - it is important to plot the data. Weak correlations (close to zero) may indicate there is not a linear relation. But there may still be a relation between the variables - just not one that follows a straight line. Indeed, the same correlation may take many different forms. Consider the data sets from the datasauRus package presented in Figure 4.8. The graphs for each data set appear quite different. Yet, the following is true for all 12 data sets:
- The mean of X is 54.3 and the standard deviation is 16.8
- The mean of Y is 47.8 and the standard deviation is 26.9
- The correlation between X and Y is \(\rho\) = -.06
Therefore, make sure you ALWAYS graph your data. The numbers only tell part of the story.
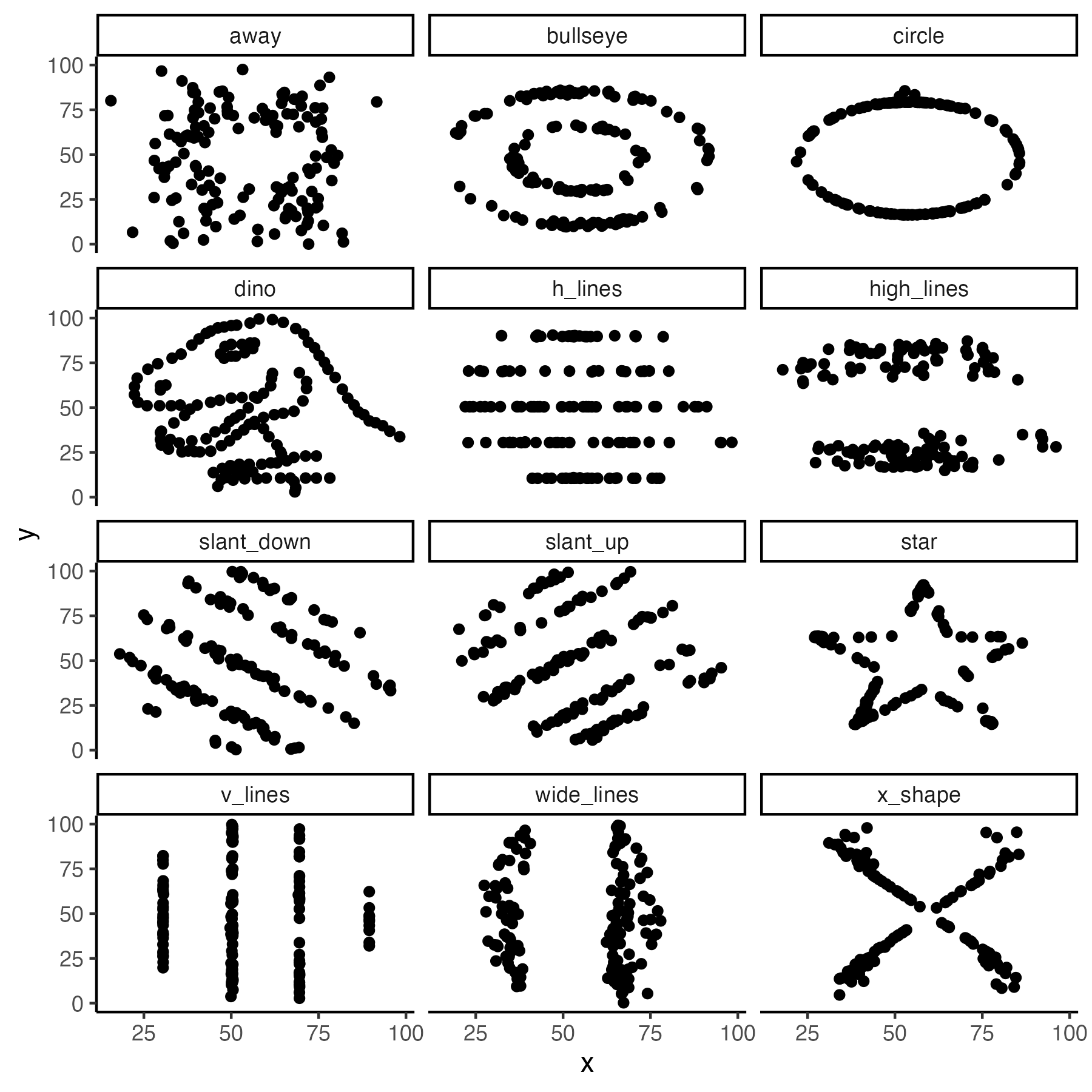
FIGURE 4.8: Various data sets with the same correlation, same means, and same standard deviations
4.10 Relation benchmarks
Plots of linear relations are presented in Figure 4.9. The three graphs in this figure correspond to Cohen’s benchmarks for correlations (i.e., \(\rho\)), displayed in the table below.
| Cohen (1988) Label | Value |
|---|---|
| Small | \(\rho\) = .10 |
| Medium | \(\rho\) = .30 |
| Large | \(\rho\) = .50 |
These effect size labels should be interpreted with caution. The magnitude of an effect is best considered in the context of the field of research and the consequences of an effect on individuals in both the short and long run.
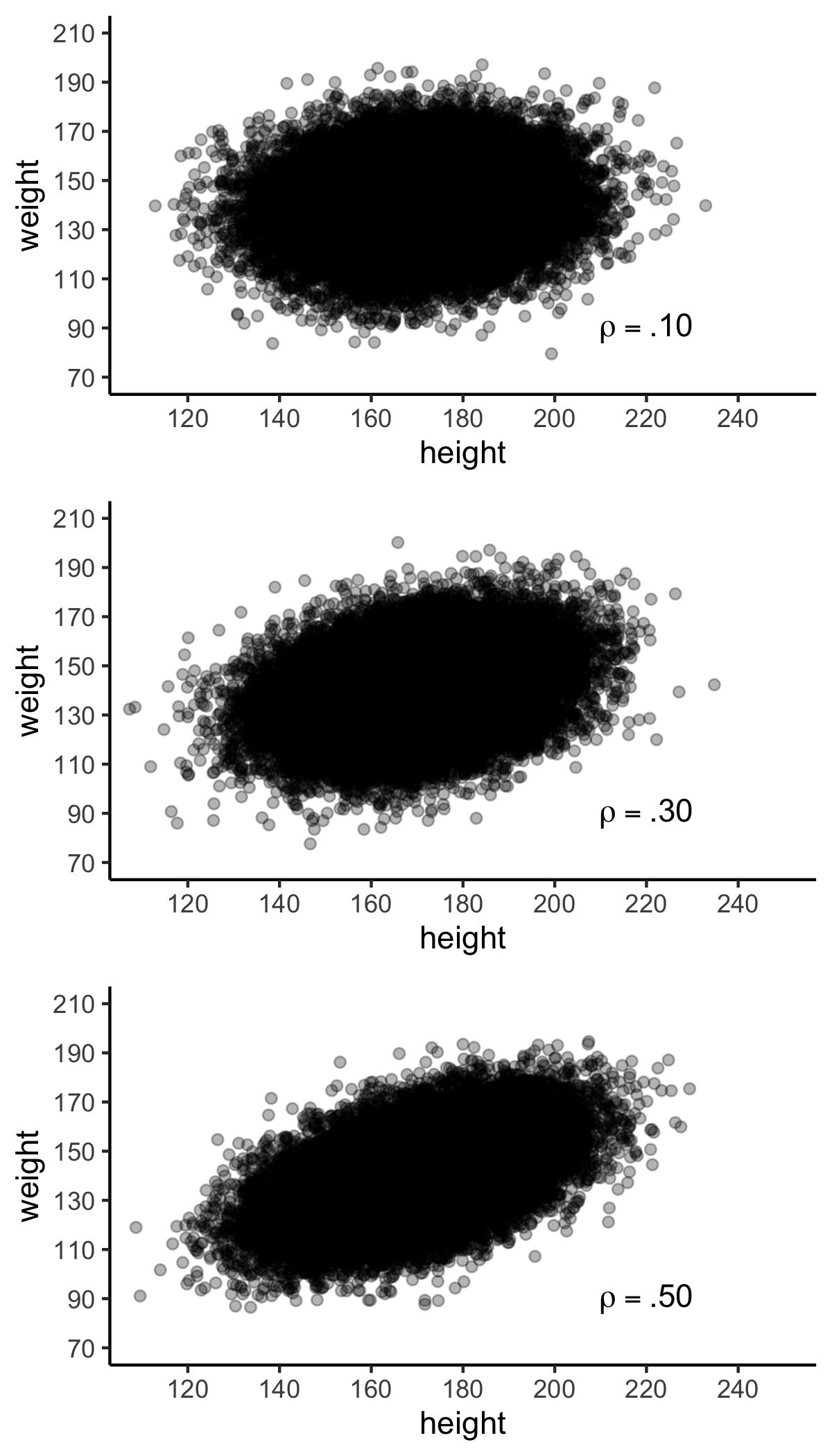
FIGURE 4.9: Populations of various strengths.
4.11 Key points
Populations are described using numbers called parameters.
Population-level parameters are often represented using Greek letters.
Commonly used parameters include mean (\(\mu\)), variance (\(\sigma^2\)), or standard deviation (\(\sigma\)).
Individual scores can be expressed in standardized units.
Population differences can be described in original raw units or standardized units called the standardized mean difference (SMD).
SMD is based on the premise that the two populations being compared have the same standard deviation.
SMD is a ratio that compares two numbers (the numerator and the denominator).
Make sure you understand what is represented by both the numerator and denominator in the SMD ratio.
SMD (i.e., Cohen’s d) represents the number of standard deviations between two population means. Recall both populations have the same standard deviation.
SMD is indicated at the population level using the Greek letter delta (\(\delta\)). At the sample level we tend to use the term “\(d\)-value” or “Cohen’s \(d\)”.
4.12 Minor Points
Standardized mean differences are reported with a leading zero: \(\delta\) = 0.50.
Correlations are reported without a leading zero: \(\rho\) = .30.
The difference in reporting is an APA-style issue. Values that are bounded between 0 and 1 (or between -1 and +1) are reported without a leading zero (e.g., \(\rho\) and \(r\)). Values that are not bounded are reported with the leading zero (e.g., \(\delta\) and \(d\)).
4.13 Self Assessment
What is the difference between parameters and statistics?
Are the formulas (excluding notation differences) always the same for parameters and statistics? If not, explain why not?
Grade 4 students in Ontario are taller than the Grade 3 students. Specifically, \(\delta\) = 0.30. How would you describe what this value means to an audience of experts at a conference? How would you describe what this value means to community members during a talk at the local public library?
We reviewed three different ways of calculating a standardized mean difference (\(\delta\)). What is the appropriate circumstance to use each formula? Describe a concrete scenario for each one.
There is a strong relation between two variables that follows an upside-down U-shape. Would you expect there to be a strong correlation between these two variables? Why or why not?