Chapter 17 Deep dive: Sampling and ANOVA
17.1 Equal population means
In this chapter, we build from a one-population scenario to a three-population scenario, where the three populations have identical population means (under the null hypothesis of no differences).
17.2 A tale of two formulas
In this chapter, we focus on describing the distribution of sample means. Our goal is to understand the logic behind two different formulas for estimating the variance of the sampling distribution of the sample mean (often denoted \(\sigma_{\bar{x}}^2\)), which quantifies how much sample means vary from sample to sample. A thorough understanding of both estimation approaches is critical because ANOVA compares these two estimates of variance—the observed variance among sample means and the expected variance due to random sampling error—to compute the F-statistic.
| Approach | Estimation Formula | Goal |
|---|---|---|
| Approach 1: Estimated Observed Variance | \(s_{\bar{x}}^2=\frac{\sum (\bar{x}-\bar{\bar{x}})^2}{a-1}\) where \(\bar{x}\) is the sample mean for each group, \(\bar{\bar{x}}\) is the grand mean across all groups, and \(a\) is the number of groups. | Estimate the variance of the sampling distribution of sample means across groups. This estimate includes variance due to both population mean differences and random sampling error. |
| Approach 2: Estimated Expected Variance | \(s_{\bar{x}}^2=\frac{s_{people}^2}{n}\) | Estimate the variance of the sampling distribution of sample means under the null hypothesis, attributable solely to random sampling error (i.e., assuming no true differences among population means). |
Understanding the logic behind both approaches for estimating the variance of the distribution of sample means is critical. In this chapter, where there is one population of people, the two approaches estimate the same thing - variability in sample means due to random sampling. However, in future chapters, where there are multiple populations of people with different means, the two approaches estimate different things. Consequently, to prepare you for those more complex future chapters, it’s important to understand the logic behind both approaches in the simple case - where there is a single population of people.
What we learn in this chapter (and the pattern of results we obtain) will serve as a frame-of-reference for interpreting more complex situations in future chapters.
17.3 A student population
Consider a scenario where there is a large university with 100,000 students and we have the heights of all 100,000 students. We think of this as a population of student heights. The mean height of all 100,000 students is 172.50 cm and the variance is 156.3236 cm\(^2\). The heights of all the university students are illustrated in Figure 17.1A. This figure is shaded with stick figures wearing trousers that remind us this distribution represents people.
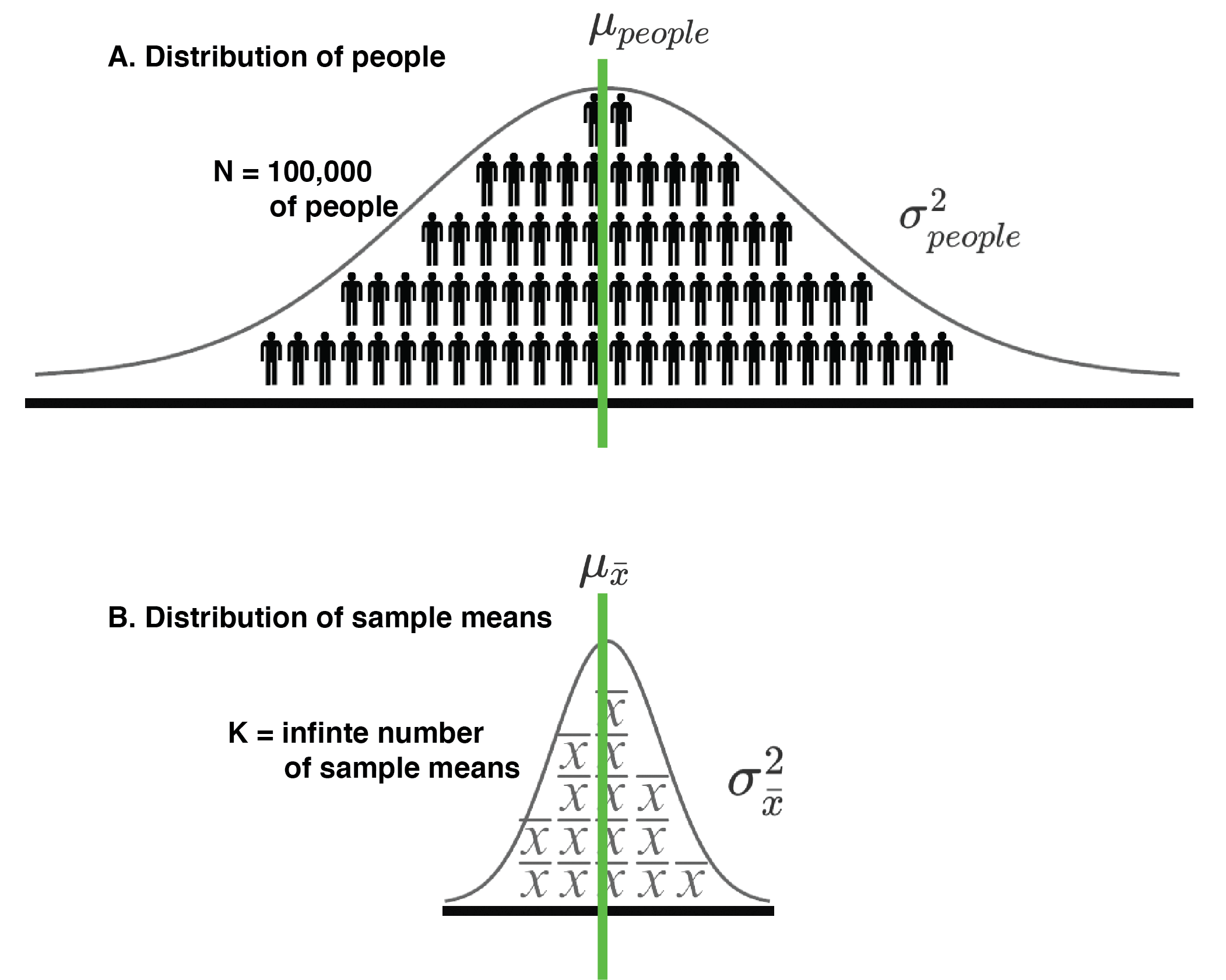
FIGURE 17.1: A distribution of people (A.) and a corresponding distribution of sample means (B.) can both be considered populations in some sense.
The mean of a population of 100,000 student heights is calculated using Equation (17.1) below.
\[\begin{equation} \mu_{people} = \frac{\sum_{i=1}^{N=100000}{X_i}}{N} \tag{17.1} \end{equation}\]The variance for a population of 100,000 student heights is calculated using Equation (17.2) below.
\[\begin{equation} \sigma_{people}^2 = \frac{\sum_{i=1}^{N=100000}{(X_i - \mu_{people})^2}}{N} \tag{17.2} \end{equation}\]For these 100,000 people the mean is \(\mu_{people}=172.50\) and the variance is \(\sigma_{people}^2=156.3236\).
17.4 Random sampling process
Now imagine that we are interested in studying the random sampling process. Specifically we are interested in examining the variability in sample means that occurs when taking random samples of students heights from the population of people (see Figure 17.1). Indeed, imagine that we obtained a sample of \(n\) = 5 students and measured their heights. Then we calculated a sample mean (\(\bar{x}\)) based on those heights. Then we repeated this sampling process an infinite number of times such that we have an infinite number of sample means each based on the heights of 5 students. This set of an infinite number of sample means is conceptually illustrated in Figure 17.1B and we refer to it as the sampling distribution of the mean. Moreover, because we sampled from a single population, whose variance is 156.3236 (i.e., \(\sigma_{people}^2 =156.3236\)), the variability in sample means, when each sample size is 5 (\(n=5\)), is due to the random sampling error only.
17.5 Population: What’s in a name
Typically, in psychology, when we use the word “population” we are referring to a population of people with respect to some dependent variable - such as the heights illustrated in Figure 17.1A. However, in statistics, a population is simply a set of elements (often people) about which we wish to draw conclusions. In this chapter, we shift our focus from thinking of the distribution of people in Figure 17.1A as a population to also thinking of the distribution of sample means in Figure 17.1B as a population. Doing so may seem counterintuitive but it is the logical foundation for Analysis of Variance (ANOVA).
17.5.1 Sample means in context
Thinking of the distribution of sample means as a population can be a bit tricky - since there are two populations that we could be referring to when we use the word “population”. Notation helps to keep things straight. In this book, when we are talking about a distribution of people (see Figure 17.1A), we use \(N\) to indicate the number people in the population and \(n\) to refer to the number of people in a subset of the population (what we typically refer to as a sample). Likewise, when we are talking about a distribution of sample means (see Figure 17.1B), we use \(K\) to indicate the number of sample means in the population.
Consider a concrete example. When we obtain a sample of five people’s heights (\(n\) = 5) we can think of the people in the sample as a subset of the population of people (\(N\)=100,000), see Figure 17.1A.
But we can also think of that single sample mean as a subset of an infinitely large set of sample means, see Figure 17.1B. We use (\(K = \infty\)) to refer to the total number of sample means in the population of sample means.
When we have one sample mean from this population of sample means we say \(a = 1\). If we had three sample means from this population of sample means, 17.1B, we would say \(a = 3\).
17.5.2 Distribution of sample means as a population
Because we are thinking of the distribution of sample means as a population we can calculate the mean and variance for the distribution of sample means. The mean of the population of sample means is calculated as below in Equation (17.3). Notice that we used the symbol, \(\mu_{\bar{x}}\), to represent this value. Further notice, the little \(\bar{x}\) beside the \(\mu\) in \(\mu_{\bar{x}}\) which indicates it is sample means that are being averaged. As noted previously, we use \(K\) instead of \(N\) to represent the number of sample means (where \(K\) = infinity, because there are an infinite number of sample means in the distribution)1. Notice the similarity between the formula for the mean of a distribution of people, Equation (17.1) above, and the formula for the mean of a distribution of sample means, Equation (17.3).
\[\begin{equation} \mu_{\bar{x}} = E[\bar{X}] = \lim_{K \to \infty} \frac{\sum_{i=1}^{K}{\bar{x}_i}}{K} \tag{17.3} \end{equation}\]Using Equation (17.3) we find that the mean of the sample means is 172.50 cm (i.e., \(\mu_{\bar{x}} = 172.50\)).
A key point to remember is that the mean of the sample means, \(\mu_{\bar{x}}\), will always be the same as the mean of people’s heights, \(\mu_{people}\). Consequently, any conclusions we make the mean of sample means, \(\mu_{\bar{x}}\) see Figure 17.1B, will also apply to the mean of people, \(\mu_{people}\) see Figure 17.1A. This is a crucial point to keep in mind as we proceed through this chapter. Although we are ultimately interested in making conclusion about the mean of the people (i.e., \(\mu_{people}\)) - all our work in this chapter (and in ANOVA) is based on the mean of the distribution of sample means in Figure 17.1B (i.e., \(\mu_{\bar{x}}\)).
17.6 Sample mean distribution variance
When there is one population of people (see Figure 17.1A) there is a single distribution of sample means that corresponds to that population (see Figure 17.1B). In this scenario, the sample means differ only because of random sampling. There are two approaches for calculating the variance of this distribution of sample means.
Approach 1: Observed Variance – Compute variance directly from a set of sample means (captures all variability among them, whether from sampling error or population differences).
Approach 2: Expected Variance – Compute variance via the formula \(\sigma_{\bar{x}}^2 = \sigma_{\text{people}}^2 / n\) (captures only variability from random sampling).
17.6.1 Approach 1: Observed Variance (all sources of variability)
In this first method, we use an infinite number of sample means and simply calculate the variance, see Equation (17.4) below.
\[\begin{equation} \sigma_{\bar{x}}^2 = \lim_{K \to \infty}\frac{\sum_{i=1}^{K=\infty}{(\bar{x}_i - \mu_{\bar{x}})^2}}{K} \tag{17.4} \end{equation}\]Notice how Equation (17.4) for the variance of sample means in Figure 17.1B, is similar to the formula we use for the variance of people, Equation (17.2), in Figure 17.1A. The formula for the variance of sample means, Equation (17.4), differs because we are using sample means (\(\bar{x}\)) instead of attributes of people (\(X\)). As well, we use \(K\) to indicate the number of elements used (i.e., an infinite number of sample means) in the calculation rather than \(N\).
| Distribution | Attribute | Parameter Calculation | Estimate of Parameter |
|---|---|---|---|
| People | Variance | \(\sigma_{people}^2 = \frac{\sum_{i=1}^{N}{(X_i - \mu_{people})^2}}{N}\) | \(s_{people}^2 = VAR = \frac{\sum_{i=1}^{n}{(x_i - \bar{x}_{people})^2}}{n-1}\) |
| Sample Means | Approach 1: Observed Variance | \(\sigma_{\bar{x}}^2 = \lim_{K \to \infty} \frac{\sum_{i=1}^{K=\infty}{(\bar{x}_i - \mu_{\bar{x}})^2}}{K}\) | \(s_{\bar{x}}^2 = \frac{\sum_{i=1}^{a}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}\) |
Obviously, using Equation (17.4) to calculate the variance of an infinite set of sample means is an impractical solution because we could never obtain the infinite number of samples and then calculate the variance for this set. Conceptually, however, it’s good to keep this calculation method in mind - since it reminds us of principles we’ve already learned about the variance of populations 2
But imagine if we could obtain the full infinite set of sample means - then we could use the formula as below:
\[ \begin{aligned} \sigma_{\bar{x}}^2 &= \frac{\sum_{i=1}^{K=\infty}{(\bar{x}_i - \mu_{\bar{x}})^2}}{K}\\ &= 31.26472\\ \end{aligned} \]
Thus, the “population” variance of the distribution of sample means (\(\sigma_{\bar{x}}^2\), see Figure 17.1B) is calculated, based an infinite number of sample means (\(K = \infty\)) using Approach 1, to be \(\sigma_{\bar{x}}^2 = 31.26472\).
When there is only one population of people this formula will reflect variability in sample means due to random sampling. When there is more than one population of people - it becomes more complicated. We’ll discuss that situation in a future chapter.
17.6.2 Approach 2: Expected Variance (random sampling only)
Fortunately, when sampling error is the ONLY source of variability in sample means there is a shortcut. We don’t need to obtain an infinite number of sample means to determine the variance of the distribution of an infinite number of sample means, Figure 17.1B. There is a “shortcut formula” we called Expected Variance, see the formula below.
\[ \sigma_{\bar{x}}^2 = \frac{\sigma_{people}^2}{\text{sample size}} \]
But we more often see it represented completely symbolically as per Equation (17.5) below.
\[\begin{equation} \sigma_{\bar{x}}^2 = \frac{\sigma_{people}^2}{n}\\ \tag{17.5} \end{equation}\]An inspection of Equation (17.5) reveals the variance of the distribution of sample means DUE TO RANDOM SAMPLING ERROR ONLY(see Figure 17.1B) depends on both the number of people in each sample (\(n\)) and the variability in the people’s heights in the population (see Figure 17.1B, \(\sigma_{people}^2\)).
It’s helpful, moving forward, to think of this formula (\(\frac{\sigma_{people}^2}{n}\)) as representing the EXPECTED variability in means due to random sampling. The expected variability formula will always reflect the variability in sample means due ONLY to random sampling.
Previously, we learned that the variance of the distribution of people in Figure 17.1A is \(\sigma_{people}^2=156.3236\). Consequently, we can use Equation (17.5) to calculate the variance of the distribution of sample means in Figure 17.1B:
\[ \begin{aligned} \sigma_{\bar{x}}^2 &= \frac{\sigma_{people}^2}{n}\\ &= \frac{156.3236}{5}\\ &= 31.26472\\ \end{aligned} \]
Thus, the “population” variance of the distribution of sample means (\(\sigma_{\bar{x}}^2\), see Figure 17.1B) is calculated, using Approach 2 Expected Variance, to be \(\sigma_{\bar{x}}^2 = 31.26472\).
17.6.3 Ratio comparison of two approaches
To begin, we are looking at a distribution of sampling means where the means differed only due to random sampling error. In this situation, we have calculated the variance of the distribution of sample means using two different approaches.
Approach 1 Observed Variance: Total variance of sample means calculated using sample means and the variance formula
Approach 2 Expected Variance: Variance of sample means, due to random sampling error.
Although we can just look at the numbers resulting from these two approaches and compare them, that’s not how statisticians typically handle such comparisons. The approach used by statisticians to compare two numbers is to create a ratio. That is, take one number and divide it by the other number. If the two numbers are the same the ratio will be 1.00. If the ratio is larger than 1.00 it means the number on the top was bigger than the number on the bottom.
\[ \begin{aligned} \text{ratio comparing approaches} &= \frac{\text{Observed: total variance of sample means }}{\text{Expected: variance of sample means due to random sampling error}}\\ &=\frac{\frac{\sum_{i=1}^{A=\infty}{(\bar{x}_i - \mu_{\bar{x}})^2}}{A}}{\frac{\sigma_{people}^2}{n}}\\ &=\frac{31.26472}{31.26472}\\ &= 1.00\\ \end{aligned} \]
You can see the ratio comparing these two approaches below is 1.00 - so we conclude two approaches produced the same result. If the number on the top of the ratio was the larger of the two, then the value of the ratio would be greater than 1.00. In contrast, if the number on the top of the ratio was the smaller of the two, then the value of the ratio would be less than 1.00. Be sure you understand how to interpret the value of a ratio using these rules before continuing.
CRITICAL: Think about what this means. Both approaches produced the same number. The observed variance: total variance approach resulted in the same number as the expected variance: random sampling only approach. So we can conclude the only reason the sample means differed from each other was random sampling. Go back and re-read this paragraph a few times until you are sure you understand this crucial point.
CALCULATION VS ESTIMATION. In this section, we focused on actually calculating the variance of the distribution of sample means using two approaches. But to actually calculate this variance we needed an infinite number of sample means (Approach 1) or knowledge of the population of people variance (Approach 2). Consequently, it’s impractical to calculate either quantity.
In the next section, below, we recognize that we can likely never know or calculate the variance of the distribution of sample means. Instead, we focus on estimating the variance of the distribution of sample means. An estimated value is an approximation of the actual value that will differ due to the effects of random sampling.
17.7 Estimating sample mean distribution variance
In this section we focus on estimating the variance of the distribution of sample means using sample data. Imagine that we obtained three samples (i.e., \(a = 3\)) and each sample has 5 people (i.e., \(n = 5\)) from the population of people illustrated in Figure 17.1A. The statistics for those three samples are presented below.
| Sample Number | Sample size (\(n\)) | Mean (\(\bar{x} = \frac{\Sigma x_i}{n}\)) | Variance (\(s_{people}^2=\frac{\Sigma (x_i - \bar{x})^2}{n-1}\)) |
|---|---|---|---|
| 1 | 5 | 185 | 168 |
| 2 | 5 | 169.2 | 146.7 |
| 3 | 5 | 170 | 346 |
17.7.1 Approach 1: Estimated Observed Variance (all sources variability)
We can use the sample means presented in the table above to estimate the variance of the distribution of sample means as illustrated in the formula below. Recall, we use a lower case character, \(a\), to represent the number of sample means (in the case because we have 3 sample means \(a = 3\)). We think of these three sample means as a subset (\(a = 3\)) of the distribution of an infinite number of sample means (i.e., a population of sample means, \(K=\infty\)) illustrated in Figure 17.1B. Consequently, we use the standard approach of estimating the variance of a larger set of elements from a (i.e., a population of sample means) subset of those elements (i.e., a sample of sample means) by including “-1” in the denominator of the variance formula, see Equation (17.6) below.
\[\begin{equation} s_{\bar{x}}^2 = \frac{\sum_{i=1}^{a=3}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1} \tag{17.6} \end{equation}\]First, we calculate the mean of the three sample means (\(\bar{\bar{x}}\)) because we will need that in the variance formula.
\[ \begin{aligned} \bar{\bar{x}} &= \frac{\sum_{i=1}^{a=3}{\bar{x}_i}}{a}\\ &= \frac{\bar{x}_1+\bar{x}_2+\bar{x}_3}{a}\\ &= \frac{185 + 169.2 + 170 }{3}\\ &= 174.733 \end{aligned} \]
Second, we estimate the variance of the population of sample means (\(s_{\bar{x}}^2\), see Figure 17.1B) using the set of sample means. Again, notice the use of “-1” in the denominator - which we discussed previously in the sample accuracy chapter. The use of the “-1” in the denominator means we are not calculating the variance of these three sample means. Rather, when we use “-1” in the denominator we are estimating the variance of the population of sample means from which they were obtained (i.e., the distribution of sample means depicted in Figure 17.1B).
\[ \begin{aligned} s_{\bar{x}}^2 &= \frac{\sum_{i=1}^{a=3}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}\\ &= \frac{(\bar{x_1}- \bar{\bar{x}})^2+(\bar{x_2}- \bar{\bar{x}})^2+(\bar{x_3}- \bar{\bar{x}})^2}{a-1}\\ &= \frac{(185 - 174.733)^2+(169.2 - 174.733)^2+(170 - 174.733)^2}{3-1}\\ &= 79.213 \end{aligned} \]
Thus, the “population” variance of the distribution of sample means (\(\sigma_{\bar{x}}^2\), see Figure 17.1B) is estimated, based on three sample means (\(a = 3\)) using Approach 1, to be \(s_{\bar{x}}^2 = 79.213\). Remember though 79.213 is just an estimate of the population value (\(\sigma_{\bar{x}}^2\)) based on three sample means.
IMPORTANT: TThe denominator of this variance estimate is \(a - 1 = 3 - 1 = 2\), which are the numerator degrees of freedom in the corresponding \(F\)-test context. Therefore, we say there are 2 degrees of freedom associated with this estimate of the variance of the infinite number of sample means.
17.7.2 Approach 2: Estimated Expected Variance ( random sampling only)
We can use the information presented in the table above in another way to estimate the variance of the distribution of sample means. Indeed, recall that another approach to calculating the variance of the distribution of sample means is to use Expected Variance, Equation (17.5) above, repeated below for clarity.
\[ \begin{aligned} \sigma_{\bar{x}}^2 &= \frac{\sigma_{people}^2}{n}\\ \end{aligned} \]
17.7.2.1 Estimating \(\sigma_{people}^2\) with \(s_{people}^2\)
The problem with the formula above is that you need to know the variance of all the people in the population (\(\sigma_{people}^2\)) - and we don’t know the variance of all the people in the population. But, we do have three samples from that population of people. Because the three samples are from the same population of people - we know each sample provides an estimate of the same (single) variance of people in the population. Therefore, we can combine those variance estimates into a better (or average) estimate of the variance of the people (\(s_{people}^2\)) in the population using the formula below.
\[ \begin{aligned} s_{people}^2 &= MSE_{people}\\ &= \frac{\sum_{i=1}^{a=3}(n_i-1)s_i^2}{\sum_{i=1}^{a}(n_i-1)} \\ &= \frac{(n_1-1)s_1^2 + (n_2-1)s_2^2 + (n_3-1)s_3^2}{(n_1-1)+(n_2-1)+(n_3-1)} \\ &= \frac{(5-1)s_1^2 + (5-1)s_2^2 + (5-1)s_3^2}{(5-1)+(5-1)+(5-1)} \\ &= \frac{(5-1)168 + (5-1)146.7 +(5-1)346}{(5-1) + (5-1) + (5-1)} \\ &= \frac{672 + 586.8 + 1384}{15 -3} \\ &= \frac{2642.8}{12} \\ &= 220.2333 \\ \end{aligned} \]
IMPORTANT: The denominator of this variance calculation is \(12\) (i.e., \(a(n-1)=3(5-1)=3(4)=12\)). Therefore, we say there are 12 degrees of freedom associated with this estimate of the variance of the people in the population.
When the three sample sizes are the same the above formula just boils down to an average:
\[ \begin{aligned} s_{people}^2 &= MSE_{people}\\ &= \frac{s_1^2 + s_2^2 + s_3^2}{3} \\ &= \frac{168 + 146.7 + 346 }{3} \\ &= \frac{660.7}{3} \\ &= 220.2333 \\ \end{aligned} \]
The number we just calculated, \(s_{people}^2 =220.2333\), is an estimate of the variance of the population of people illustrated in Figure 17.1A. You could think of this number as an average variance estimate.
We created the average variance estimate,\(s_{people}^2 =220.2333\), by combining three sample estimates of the variance of the population of people. Each sample estimate was based on 5 people (i.e., 4 degrees of freedom). But the average variance estimate we just calculated ( \(s_{people}^2 =220.2333\)) is based on 15 people - people from all three samples (i.e., 12 degrees of freedom). Because we combined people from all three samples the average variance estimate is a better estimate of the variance of the population of people than any single sample estimate. In technical terms, we say the variance estimate we just calculated is a better estimate because of the higher degrees of freedom (12) compared to an individual sample estimate (with only 4 degrees of freedom). The average variance estimate typically has lower sampling variability than an estimate from a single sample because it is based on more degrees of freedom. “Better” here means more precise on average, not necessarily closer to the true value in every instance.
We use different names to refer to the resulting average variance estimate - we could just call it a better estimate of the population variance (\(s_{people}^2\)). But, statisticians also use the term pooled variance (\(s_{pooled}^2\)) to refer to it. Other times, statisticians use the term Mean Square Error (\(MSE\)) to refer to it. You should realize that these are all just synonyms for variance of the population of people illustrated in Figure 17.1A: \(s_{people}^2 = s_{pooled}^2 = MSE_{people} = MSE\).
17.7.2.2 Estimating \(\sigma_{\bar{x}}^2\) with Expected Variance Approach
If we assume that random sampling error is the only source of variance in the distribution of sample means we can estimate \(\sigma_{\bar{x}}^2\) using the expected variance formula.
More specifically, armed with the estimate of the variance of the people in the population (\(s_{people}^2\)) we can use the Estimated Expected Variance formula to obtain an estimate of the variance of the distribution of sample means using Equation (17.7) below.
\[\begin{equation} s_{\bar{x}}^2 = \frac{s_{people}^2}{n} \tag{17.7} \end{equation}\]Putting in values:
\[ \begin{aligned} s_{\bar{x}}^2 &= \frac{s_{people}^2}{n}\\ &= \frac{220.2333 }{5}\\ &= 44.0467 \end{aligned} \]
Thus, using Approach 2: Estimated Expected Variance, our estimate of the variance of the distribution of sample means, due to random sampling error is \(s_{\bar{x}}^2 = 44.0467\).
IMPORTANT: This estimate of the variance of the distribution of sample means used estimate of the variance of the people in the population (i.e., \(s_{people}^2 =220.2333\)). There were 12 degrees of freedom associated with \(s_{people}^2\) which \(s_{\bar{X}}^2\) depends upon. So we say there are 12 degrees of freedom associated with \(s_{\bar{X}}^2\).
17.7.3 Ratio comparison of two approaches
The table below summarizes our work so far.
| Attribute | Unknown Parameter | Estimate of Parameter | \(s_{\bar{x}}^2\) degrees of freedom |
|---|---|---|---|
| Approach 1: Estimated Observed Variance | \(\sigma_{\bar{x}}^2 =31.26472\) | \(s_{\bar{x}}^2 = \frac{\sum_{i=1}^{a}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}= 79.213\) | \(a-1=3-1=2\) |
| Approach 2: Estimated Expected Variance | \(\sigma_{\bar{x}}^2 =31.26472\) | \(s_{\bar{x}}^2 = \frac{s_{people}^2}{n}=44.0467\) | \(a(n-1)=3(5-1)=12\) |
In the table above, Approach 1 Estimated Observed Variance, estimates the total variance (from all sources) in sample means. In contrast, Approach 2 Estimated Expected Variance, estimates the variance in sample means due only to random sampling error. In this particular scenario we know the only source of variability in sample means is random sampling error. So, do the two numbers differ?
Recall, that in Approach 1 Estimated Observed Variance, we didn’t have all of the sample means in the infinitely large distribution of sample means. We based our estimate on only three of those means. So our estimate using, Approach 1, will differ from the truth due to sampling error – because we only have 3 sample means - not the full infinite set of sample means.
Likewise, recall that in Approach 2 Estimated Expected Variance we didn’t know the variance of the population of people (\(\sigma_{people}^2\)). We had to rely on an estimate of that value (\(s_{people}^2\)), based on 15 people (three sets of 5). Consequently, Approach 2 will differ from the truth as well due to random sampling error.
Because both Approach 1 and 2 will differ from the truth due to random sampling error, when we construct a ratio, it too will differ from the truth due to random sampling error. That is, when we construct a ratio based on those variance estimate (\(s_{\bar{x}}^2 = \frac{\sum_{i=1}^{a}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}= 79.213\) and \(s_{\bar{x}}^2 = \frac{s_{people}^2}{n}=44.0467\)) the ratio will differ from “the truth” (1.00) due to sampling error.
\[ \begin{aligned} \text{ratio comparing approaches} &= \frac{\text{variance of sample means using ESTIMATED Observed Variance}}{\text{variance of sample means using using ESTIMATED Expected Variance}}\\ &=\frac{\frac{\sum_{i=1}^{a=3}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}}{\frac{s_{people}^2}{n}}\\ &=\frac{79.213}{44.0467}\\ &= 1.7984\\ \end{aligned} \]
17.8 Frame of reference: Random sampling only
In this section we focus on using simulations to establish a frame of reference for interpreting the variance ratio in a scenario where random sampling is the only reason sample means differ from each other. Because random sampling is the only reason the sample means differ both formulas are estimating the same thing. However, due to random sampling error, the numbers produced by the formulas may differ.
17.8.1 Simulation of 1 population
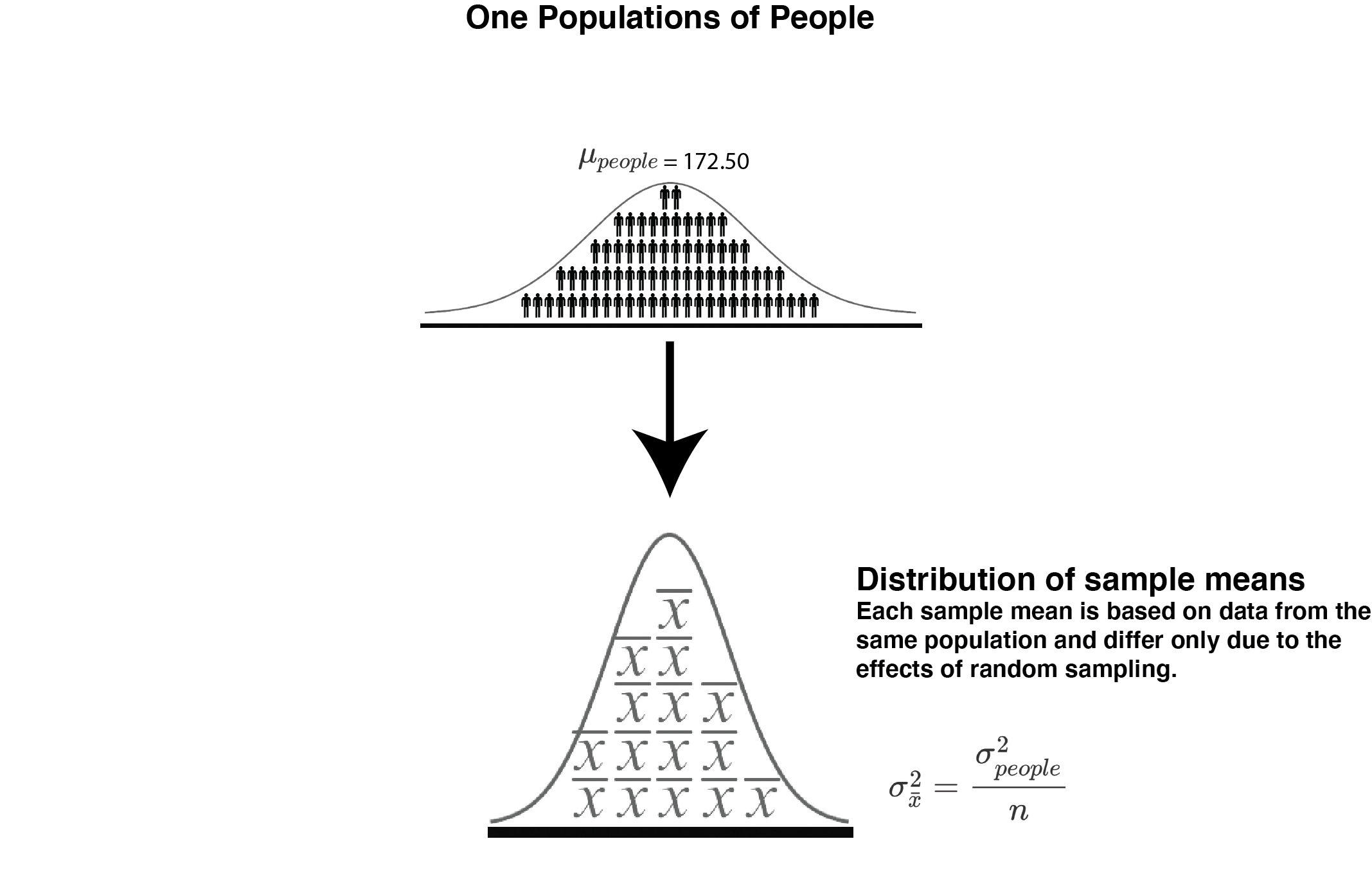
FIGURE 17.2: Sampling from one population
The simplest scenario to understand the estimation formulas we have discussed is the one illustrated in Figure 17.2 above. In this scenario, we obtain 3 samples from the population of people and then used that data to estimate the variance of the distribution of sample means using Approach 1 Estimated Observed Variance and Approach 2 Estimated Expected Variance. Then we create a ratio of those two values (Approach 1/Approach 2). Each additional row of the table shows a case where we did this same thing with three new samples.
We begin by creating the population in R:
Then we run a simulation where we estimate the variance using the distribution of sample means using the information in the three sample via Approach 1 and Approach 2. We repeat this estimation process 100,000 times to see if it is accurate in the long run.
The results of the 100,000 simulations are placed in the data set called data_ratios. We can see the first few rows of these data below.
## trial method_1_obs_var_est method_2_exp_var_est var_ratio
## 1 1 117.973 34.20 3.44951
## 2 2 45.853 44.61 1.02795
## 3 3 2.573 48.56 0.05299
## 4 4 8.920 22.07 0.40411
## 5 5 9.693 35.68 0.27167
## 6 6 84.853 21.42 3.96141When you inspect the table above, recognize that for the first row of the table we obtained 3 random samples from the population of people and then used that data to estimate the variance of the sampling distribution of means using Approach 1 and Approach 2 (method_1_obs_var_est and method_2_exp_var_est, respectively). Then we created a ratio of those two values (method_1_obs_var_est/method_2_exp_var_est) and placed that in the table (var_ratio). Each additional row of table shows a case where we did this same thing with three new samples. There are a total of 100,000 rows in this table.
We obtain the summary statistics with the skim command:

Recall that previously, we used Equation (17.5) to calculate \(\sigma_{\bar{x}}^2 = 31.26472\). Each row in the table above presents two estimates (i.e., \(s_{\bar{x}}^2\)) of \(\sigma_{\bar{x}}^2\). You can see that the Approach 1 approach for obtaining \(s_{\bar{x}}^2\) was on average correct because of the 31.3 value in the blue box. Likewise, you can see that the Approach 2 approach for obtaining \(s_{\bar{x}}^2\) was on average correct because of the 31.3 value in the blue box.
Graphing the ratios. Although each estimate was on average correct, the two estimates were not always the same. Recall we compared the two estimates by making a ratio. Due to random sampling error on some trials the numerator of the ratio was larger and on other trials the denominator of the ratio was larger. As a result, on some trials the ratio was larger than 1.0 and on other trials the ratio was smaller than 1.0.
Below I present a graph of these ratios, Figure 17.3. This histogram shows the distribution of the ratio:
\[
\frac{\text{Variance estimate from sample means (Approach 1)}}{\text{Conceptual variance estimate based on pooled within-sample variance divided by n (Approach 2)}}
\]
When the null hypothesis of equal population means holds (as it does for this section), this ratio follows a central \(F\)-distribution. You can see there is a wide range of ratios that occur. Note that this is shape of the distributions when we have:
- A single population - so sampling error is the only reason means differ
- Total variance estimate is based on 3 sample means (i.e., \(a-1\) degrees)
- Sampling error variance estimate created using a population of people variance estimate derived from 15 people (i.e., \(a(n-1)=3(5-1)=12\) degrees of freedom)
This type of graph is helpful, because it allows us to understand, when these conditions are true, the range of ratio values that can occur. FYI - as we’ll discuss more later, this is an F-ratio.
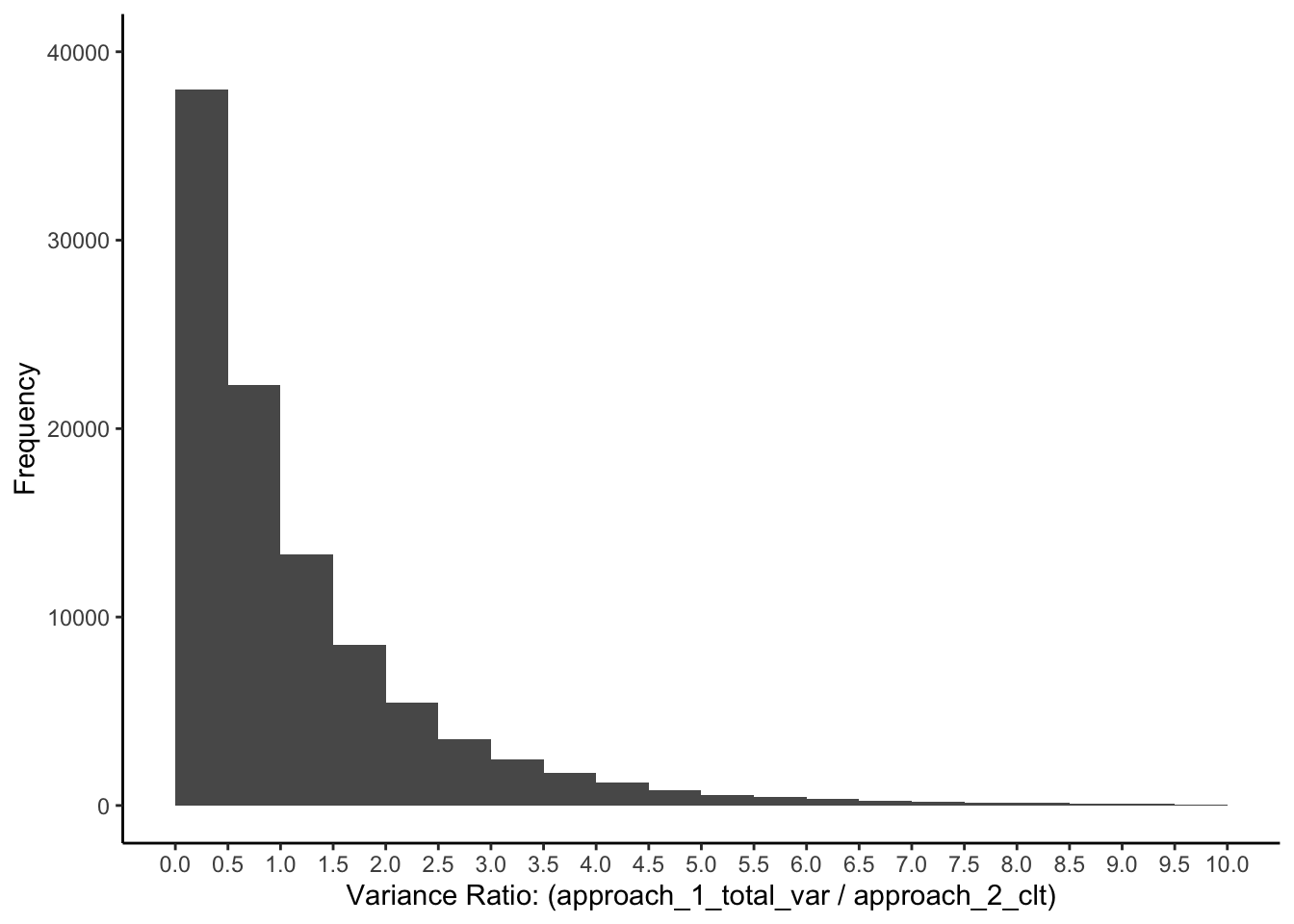
FIGURE 17.3: Variance ratio when there is one population of people
This graph illustrates the range of ratio values that can occur when there is a single population when we use 3 samples, \(a =3\), and a sample size of 5, \(n = 5\). More formally, there are 2, \((a -1)\), and 12, \(a(n-1)\), degrees of freedom.
17.8.2 Simulation of 3 identical populations
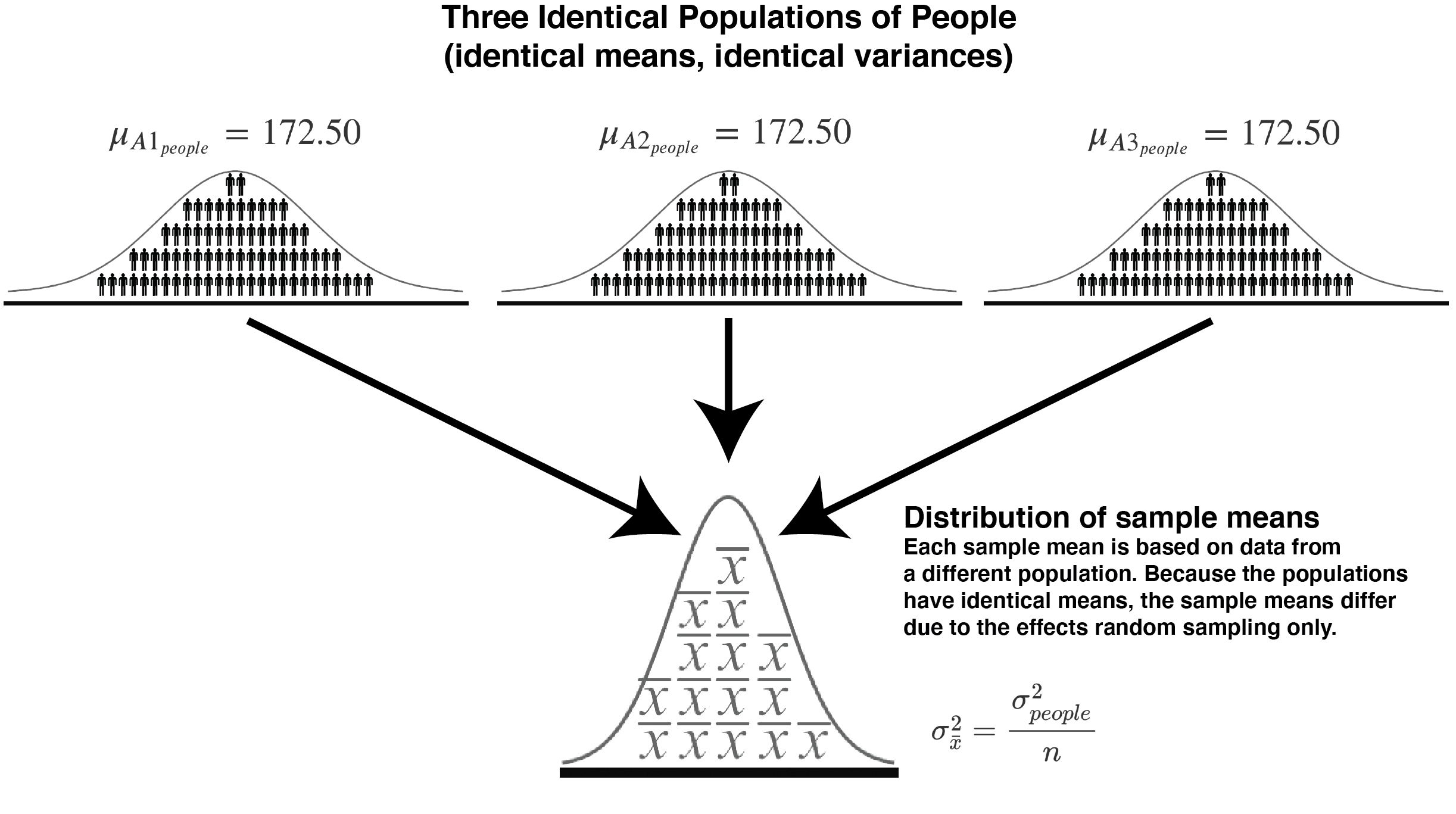
FIGURE 17.4: Sampling from three populations with the same mean (and variance)
| Population | Mean | Variance |
|---|---|---|
| 1 | \(\mu_{A1_{people}}= 172.50\) | \(\sigma_{A1_{people}}^2= 156.3236\) |
| 2 | \(\mu_{A2_{people}}= 172.50\) | \(\sigma_{A2_{people}}^2= 156.3236\) |
| 3 | \(\mu_{A3_{people}}= 172.50\) | \(\sigma_{A3_{people}}^2= 156.3236\) |
In this section, instead of using one population, we use three identical populations. That is, \(a = 3\). We use \(A1\), \(A2\), and \(A3\) to refer to these three identical populations.
You will see in this section that when you have three identical populations of people, see Figure 17.4, that the results are the same as when you have one population of people. That is, whether we think of this as “one population sampled three times” or “three distinct but statistically identical populations,” the variance decomposition is the same. This is because both situations satisfy the null hypothesis that all population means and variances are equal. We simulate the situation illustrated in the figure above. We start by creating three identical populations of people.
library(learnSampling)
pop1 <- make_population(mean = 172.50, variance = 156.3236)
pop2 <- pop1
pop3 <- pop1Then, we obtain a sample from each population of people and calculate a sample mean. When we use Approach 1: Observed variance we think of these three sample means as being a random sample (\(a = 3\)) of the infinite distribution of sample means (\(K = \infty\)). The variance of the three sample means is an estimate of the TOTAL variance of the distribution of sample means. When we use Approach 2: Expected Variance we use the people from the three sample to estimate the variance of the population of people. Then, we use our estimate of the variance of the population of people in the Approach 2: Expected Variance formula to estimate the variance of the distribution of sample means. Then we calculate the ratio of Approach 1: Estimated Observed Variance (total variance) divided by Approach 2: Expected Variance (random sampling)
Then we repeat this process 100,000 times to see how well this process works on average - via the R commands below.
The results of the 100,000 simulations are placed in the data set called data_ratios3. We can see the first few rows of these data below.
## trial method_1_obs_var_est method_2_exp_var_est var_ratio
## 1 1 117.973 34.20 3.44951
## 2 2 45.853 44.61 1.02795
## 3 3 2.573 48.56 0.05299
## 4 4 8.920 22.07 0.40411
## 5 5 9.693 35.68 0.27167
## 6 6 84.853 21.42 3.96141In the first row of the above table we obtained 3 samples (one from each population) and then used that data to estimate the variance of the sampling distribution of means using Approach 1 and Approach 2. Then we create a ratio of those two values (Approach 1/Approach 2). Each additional row of table shows a case where were did this same thing with three new samples. There are a total of 100,000 rows in this table.
We obtain the summary statistics with the skim command:

Recall that previously, we used Equation (17.5) to calculate \(\sigma_{\bar{x}}^2 = 31.26472\). Each row in table above presents two estimates (i.e., \(s_{\bar{x}}^2\)) of \(\sigma_{\bar{x}}^2\). You can see that the Approach 1 approach for obtaining \(s_{\bar{x}}^2\) was on average correct because of the 31.3 value in the green box. Likewise, you can see that the Approach 2 approach for obtaining \(s_{\bar{x}}^2\) was on average correct because of the 31.3 value in the green box.
Graphing the ratios. Although each estimate was on average correct, the two estimates were not always the same. Recall we compared the two estimates by making a ratio. Due to random sampling error on some trials the numerator of the ratio was larger and on other trials the denominator of the ratio was larger. As a result, on some trials the ratio was larger than 1.0 and on other trials the ratio was smaller than 1.0.
Below I present a graph of these ratios, Figure 17.5. You can see there is a wide range of ratio that occur. Note that this is shape of the distributions when we have:
- Three identical population - so sampling error is the only reason means differ
- Total variance estimate is based on 3 sample means (i.e., \(a-1\) degrees)
- Sampling error variance estimate created using a population of people variance estimate derived from 15 people (i.e., \(a(n-1)=3(5-1)=12\) degrees of freedom)
This type of graph is helpful, because it allows us to understand, when these conditions are true, the range of ratio values that can occur. Again remember, these are called F-ratios.
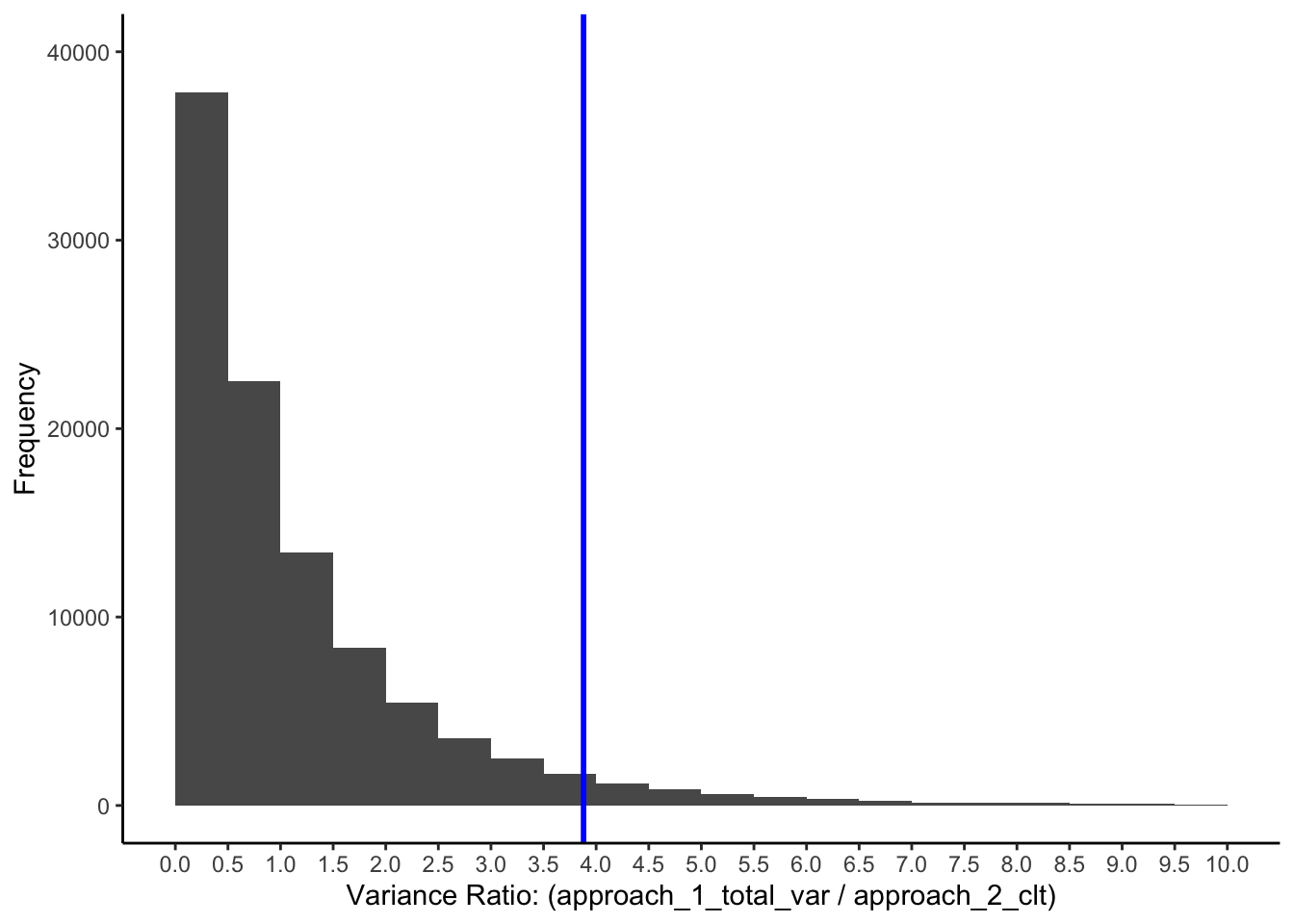
FIGURE 17.5: Variance ratio when there are three identical populations of people
17.8.2.1 Extreme ratio values
Keep in mind that this is the range of ratios that can occur when all three populations have the same mean. In the above graph we use a vertical blue line to distinguish between the lower 95% of ratio values and the upper 5% of ratios values.
How did we know where to place this line? We simply sorted the ratios from smallest to largest. Then when to the 95% percentile spot in that list. To obtain the 95% percentile in of the sorted list of 100,000 ratios we just multiple the total number of ratios (100,000) by .95. We 95000 (i.e., \(.95*100000=95000\)) which indicates that 95% of ratios are below the value in this spot. Likewise, 5% of ratios are above the value at this spot.
The ratio value in the spot 95,000 of the sorted list of 100,000 ratio values is 3.88. How do you interpret this value?
In the situation where:
- the variance estimate in the numerator has 2 degrees of freedom
- the variance estimate the denominator has 12 degrees of freedom
- the population variances are the same
- the population means are the same
When the above situation is the case, we will obtain an variance ratio above 3.88 only 5% of the time. We obtain this 3.88 value with the R-code below.
# sort the variance ratios smallest to largest
var_ratio3_sorted <- sort(data_ratios3$var_ratio)
# in order list, obtain the 95th percentile
# values beyond this point are in the upper 5% of variances ratios
# that occur when the population means are equal
extreme_cut_off3 <- var_ratio3_sorted[100000*.95]
# round the result and print it
extreme_cut_off3 <- round(extreme_cut_off3, 2)
print(extreme_cut_off3)## [1] 3.8817.8.2.2 It’s really an \(F\)-value
Most importantly, we don’t usually refer to the ratio we have been examining as a variance ratio. We refer to it as an \(F\)-ratio or \(F\)-value.
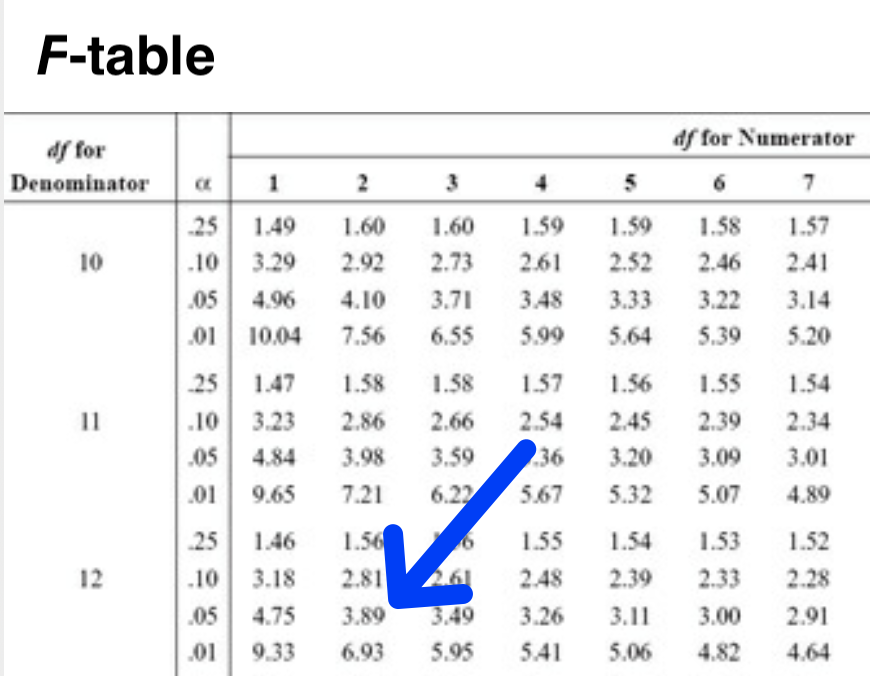
We used this simulation to see the range of \(F\)-ratios that occur when we KNOW all the population means are equal. From the graph, you can see that this range of \(F\)-ratio values is quite wide. But, we estimated that when all three populations means are equal (and n = 5) that only 5% of \(F\)-ratios will fall above a value we estimated to be 3.88. This value is what we refer to as \(F_{critical}\) when \(\alpha = .05\). Thus, \(F_{critical}\)(2, 12) = 3.88.
Compare the \(F\)-ratio we obtained (3.88) to the values in \(F\)-table at 2 and 12 degrees of freedom for \(\alpha=.05\). An \(F\)-table is a table of \(F_{critical}\) values. You can see that the value in the table is 3.89 - this is the correct value. Our estimate is 3.88 which is very close to the correct value of 3.89. Our value of 3.88 is off a bit from the 3.89 in the \(F\)-table because we only use 100,000 samples and not an infinite number of samples.
17.8.2.3 Making your own \(F\)-table
Congratulations you have just learned how to create the values in the \(F\)-table from scratch! To ensure you understand everything you have learned in this exercise think through how you would do the following:
Obtain \(F_{critical}\)(2, 12) for \(\alpha=.01\)
Obtain \(F_{critical}\)(3, 36) for \(\alpha=.05\). Look at the degrees of freedom and alpha. How many populations would you use (i.e., what would value would you use for \(a\))? How many people would you use in each sample (i.e., what value would you use for \(n\))? What position would you look at in the list of sorted variance ratios?
Obtain \(F_{critical}\)(3, 36) for \(\alpha=.01\) Look at the degrees of freedom and alpha. How many populations would you use (i.e., what would value would you use for \(a\))? How many people would you use in each sample (i.e., what value would you use for \(n\))? What position would you look at in the list of sorted variance ratios?
17.9 Central \(F\)-distributions
In this chapter we focused on creating an \(F\)-distribution when the population means were the same. When you create an \(F\)-distribution based on a scenario where the population means are all the same we refer to that as a Central \(F\)-distribution.
We created a Central \(F\)-distribution with 2 and 12 degrees of freedom (i.e., \(a=3\) and \(n=5\)). But we could have used a different number of populations (i.e., a different value for \(a\)) or a different sample size (i.e., a different value for \(n\)). For example, if we had used 5 populations (i.e., \(a = 5\)) and a sample size of 20 (i.e., \(n = 20\)) then we would have created a Central \(F\)-distribution with 4 and 95 degrees of freedom. Recall that \(df_{numerator}= a - 1 = 5 -1 = 4\) and that \(df_{denominator} = a(n-1) = 5 (20-1) = 5(19) = 95\). Thus, because there are many possible Central \(F\)-distributions, we say there is a Family of Central \(F\)-distributions. For this Family of Central \(F\)-distributions, the family resemblance is that they are all based on a scenario where the population means are equal.
You may, or may not, have realized that \(F\)-tables are just way of summarizing the Family of Central \(F\)-distributions. That is, when you look up a value at 2 and 12 degrees of freedom in an \(F\)-table are obtaining information about a specific Central \(F\)-distribution. Specifically, you are looking up a “cut” point for extreme values in that particular Central \(F\)-distribution.
Also note, that when we do significance testing we use the Null Hypothesis that the population means are all equal. This is the same assumption we use when creating a Central \(F\)-distribution. Consequently, some people refer to a Central \(F\)-distribution (or Central \(t\) distribution) as the Sampling Distribution for the Null Hypothesis.
| Scenario | Source(s) of variability in sample means | Do Approach 1 and Approach 2 estimate same quantity? |
|---|---|---|
| One population | Sampling error only | Yes |
| Multiple identical populations | Sampling error only | Yes |
| Multiple populations, different means | Sampling error + population differences | No |
17.10 Summary tables
Much of what we have learned is summarized in the table below.
| Distribution | Attribute | Parameter Calculation | Estimate of Parameter |
|---|---|---|---|
| People | Mean | \(\mu_{people} = \frac{\sum_{i=1}^{N}{X_i}}{N}\) | \(\bar{x}_{people} = M = \frac{\sum_{i=1}^{n}{x_i}}{n}\) |
| People | Variance | \(\sigma_{people}^2 = \frac{\sum_{i=1}^{N}{(X_i - \mu_{people})^2}}{N}\) | \(s_{people}^2 = VAR = \frac{\sum_{i=1}^{n}{(x_i - \bar{x}_{people})^2}}{n-1}\) |
| People | Standard Deviation | \(\sigma_{people} = \sqrt{\frac{\sum_{i=1}^{N}{(X_i - \mu_{people})^2}}{N}}\) | \(s_{people} = SD = \sqrt{\frac{\sum_{i=1}^{n}{(x_i - \bar{x}_{people})^2}}{n-1}}\) |
| Sample Means | Mean | \(\mu_{\bar{x}} = E[\bar{X}] = \lim_{K \to \infty} \frac{\sum_{i=1}^{K}{\bar{x}_i}}{K}\) | \(\bar{\bar{x}} = \frac{\sum_{i=1}^{a}{\bar{x}_i}}{a}\) |
| Sample Means | Approach 1 Observed Variance: TotalVariance | \(\sigma_{\bar{x}}^2 = \lim_{K \to \infty} \frac{\sum_{i=1}^{K=\infty}{(\bar{x}_i - \mu_{\bar{x}})^2}}{K}\) | \(s_{\bar{x}}^2 = \frac{\sum_{i=1}^{a}{(\bar{x}_i - \bar{\bar{x}})^2}}{a-1}\) |
| Sample Means | Approach 2 Expected Variance: Random sampling variance | \(\sigma_{\bar{x}}^2 = \frac{\sigma_{people}^2}{n}\) | \(s_{\bar{x}}^2 = \frac{s_{people}^2}{n}\) |
| Sample Means | Approach 2 Standard Error: Random sampling standard deviation | \(\sigma_{\bar{x}} = \sqrt{\frac{\sigma_{people}^2}{n}}=\frac{\sigma_{people}}{\sqrt{n}}\) | \(s_{\bar{x}} = SE=\sqrt{\frac{s_{people}^2}{n}}=\frac{s_{people}}{\sqrt{n}}\) |
17.11 Walk away points
Sometimes we need to shift our thinking and conceptualize the distribution of sample means as the population to which we are trying to generalize.
Think of \(s_{\bar{x}}^2 = \frac{s_{people}^2}{n}\) as estimating the variability in the distribution of sample means due to random sampling. It only estimates the variability due to random sampling and not variability due to other sources.
The findings that we illustrate here only hold when a) there is one population of people or b) multiple identical populations of people.
We are interested in the variance of the distribution of sample means (Figure 17.1B). If we were “all knowing” we would know that the variance of the distribution is 31.26472. But we are not “all knowing”, and so need to rely on sample data to estimate the variance of this distribution.
We used two different approaches to estimating the variance of the distribution of sample means. With our “all knowing cap” on we can see, in the table above, that both approaches produce values that differ from the actual variance of the distribution. That’s because the best we can do with sample data is obtain an estimate of the variance of the distribution of means - we can never know the actual variance of the distribution of sample means.
Each variance estimate (Approach 1 or Approach 2) will likely produce values that differ from the actual variance of sample means. The first estimate, Approach 1 Observed Variance, differs from 31.26472 due to sampling error. That is, we used 3 sample means (\(a=3\)) to estimate the variance of an infinite set of sample means (\(A = \infty\)). Because we used such a small subset of sample means (3 of \(\infty\)) our estimate will differ from 31.26472 due to sampling error.
Likewise, the second estimate, Approach 2 Expected Variance, used a formula that relies on knowledge of variance of the population of people (\(\sigma_{people}^2\)) to determine the variance of the distribution of sample means. We had to estimate \(\sigma_{people}^2\) using \(s_{people}^2\). Because we used such a small subset of people (\(n = 15\), 5 from each sample) from the distribution of people (\(N = 100000\)) for our estimate, \(s_{people}^2\), it will differ from \(\sigma_{people}^2\) due to sampling error. Consequently, our estimate of the variance of sample means, which relies on this value, differs from 31.26472 due to sampling error.
I realize that it doesn’t make sense to divide by infinity; however, in formal mathematics we would write this up in a different way describing the resulting value as an expected value. I use dividing by infinity simply as a way to show consistency with other formulas with the aim of increasing conceptual clarity at the expense of correct notation.↩︎
As noted previously, this notation is incorrect and I should really have expressed this as an expected value to be correct. But for conceptual clarity I divided by infinity to make the linkages to other equations clear.↩︎