Chapter 5 Sampling Accuracy
The following CRAN packages must be installed:
| Required CRAN Packages |
|---|
| tidyverse |
| remotes |
The following GitHub packages must be installed:
| Required GitHub Packages |
|---|
| dstanley4/learnSampling |
A GitHub package can be installed using the code below:
| Required Data |
|---|
| data_cor_pop.csv |
5.1 Overview
Researchers are usually interested in describing the attributes of a population; numbers that describe the population are called parameters. Two parameters that are frequently of interest are the mean and variance of the population. Unfortunately, it’s rarely possible to obtain information from every member of a population to calculate a parameter. Consequently, researchers use subsets of the population called samples to estimate parameters. Numbers calculated from sample data are called statistics. Typically, sample statistics are used to estimate population parameters.
Sample statistics, however, often differ from population parameters. The difference between a sample statistic and the population parameter occurs because the sample data is a random subset of the population data — with correspondingly fewer observations. This difference is typically refered to as sampling error.
Sometimes a sample statistic will be higher than the population parameter; other times the sample statistic will be lower than the population parameter. Because random sampling is used to select the sample data the direction and magnitude of the difference between the sample statistic and the population parameter will vary randomly.
Sample accuracy refers to the extent to which sample statistics correctly estimate the population parameter. We typically used the terms biased and unbiased to describe the accuracy of sample statistics. Consider a scenario where we take many thousands of samples from the same population. For each sample, we calculate a statistic (e.g., the mean). If the average of the sample statistics (e.g., sample means) equals the population parameter (e.g., population mean) then we refer to the statistic as being unbiased. In contrast, if the average of the sample statistics (e.g., sample means) does not equal the population parameter (e.g., population mean) then we refer to the statistic as being biased.
Further complicating matters is the fact that the formula used for a sample statistic may, or may not, be the same as the formula used for the corresponding population parameter. This occurs because the purpose of the sample statistic is typically not to describe the sample. Rather the purpose of the sample statistic is to estimate the population parameter. Depending on the parameter, you may or may not be able to use the same formula with sample data as you would with population data.
Also keep in mind that, even if you conduct experiments, the distinction between samples and populations is relevant to you. Consider a scenario where you run an experiment to test the effectiveness of a particular drug. Half the rats are assigned to a placebo condition (e.g., saline injection) whereas the other half of the rats are assigned to the drug condition (e.g., drug injection). Recognize that the placebo-condition rats are considered a sample from a much larger population of all rats who could have received the placebo. Likewise, the drug-condition rats are considered a sample of a much large population of all rats who could have received the drug. Indeed, when you conduct your analyses on this experiment the results do not tell you about the rats in your study - rather they tell you about rats in general (i.e., the larger populations of rats). Therefore, when we discuss the importance of estimating a population parameter from a sample realize that it applies to both experimental and survey research.
5.2 Data for the chapter
In this chapter we will use a population of heights to learn about random sampling. To engage in the learning activities you need to activate the required packages:
Next, we create a large population with 100,000 people using the get_height_population() command:
The print() command can be used to confirm that the population contains 100,000 people. We see that each row in pop_data represents a single person. There is a column called height that contains the heights for everyone in the population.
## # A tibble: 100,000 × 3
## id sex height
## <int> <chr> <dbl>
## 1 1 male 177
## 2 2 female 151
## 3 3 female 171
## 4 4 male 157
## 5 5 male 169
## 6 6 male 187
## 7 7 female 163
## 8 8 male 173
## 9 9 female 172
## 10 10 male 193
## # ℹ 99,990 more rows5.3 Notation
In the formulas below, when we refer to the population, we use uppercase letters to indicate members (\(X\)) or the size (\(N\)). The population mean is indicated by the symbol \(\mu\). In contrast, when we refer to the sample, we use lowercase letters to indicate members (\(x\)) or the size (\(n\)). The sample mean is indicated by the symbol \(\bar{x}\). A single bar above a letter indicates a mean. If we calculate the average of several sample means we indicate this with the symbol \(\bar{\bar{x}}\). A double bar above a letter indicates a mean of means. Make sure you notice the similarities between subsequent population and sample formulas even though the notation often differs.
5.4 Estimating \(\mu\)
We are interested in the sample mean (\(\bar{x}\)) to the extent that it provides an accurate estimate of the population mean (\(\mu\)). The population mean is calculated using Formula (5.1). In this formula, the letter \(N\) corresponds to the number of people in the population.
\[\begin{equation} \mu = \frac{\sum{X}}{N} \tag{5.1} \end{equation}\]
We can calculate the population mean for the height column of pop_data using the summarise() and mean() commands. The mean() command uses Formula (5.1). We see in the output that the population mean is 172.50 (\(\mu = 172.50\)).
## # A tibble: 1 × 1
## pop_mean
## <dbl>
## 1 172.500As noted previously, we rarely have access to data from an entire population. Consequently, we use the sample mean as an estimate of the population mean. The sample mean, \(\bar{x}\), is a statistic calculated using the using Formula (5.2) below. The bar above the \(x\), indicates that it is a mean. Notice that Formula (5.1) and Formula (5.2) are the same - even though they use different notation. In this formula, the letter \(n\) corresponds to the number of people in the sample.
\[\begin{equation} \bar{x} = \frac{\sum{x}}{n} \tag{5.2} \end{equation}\]
Because a sample mean (a statistic) is calculated using a random subset of the population it is likely to differ from the population mean (a parameter). If you, inaccurately, believe that you can learn something meaningful from a single study, this fact may be disconcerting. Statisticians know, however, that rarely can you learn anything from a single study, or even a small set of studies. Consequently, they are more interested in the extent to which sample means are right, on average. That is, they are interested in the extent to which the mean of many sample means (\(\bar{\bar{x}}\)) corresponds to the population mean (\(\mu\)). The mean of many sample means can be calculated using Formula (5.3) below. In this formula, the letter \(k\) corresponds to the number of sample means.
\[\begin{equation} \bar{\bar{x}} = \frac{\sum{\bar{x}}}{k} \tag{5.3} \end{equation}\]
If the mean of the sample means, \(\bar{\bar{x}}\), equals the population mean, \(\mu\), then the sample mean is an unbiased (or accurate) estimate of the population mean. Figure 5.1 illustrates the concept of accuracy/bias with a distribution of sample means (i.e., \(\bar{x}\)). Accuracy/bias is an index of the extent to which the mean of many sample means, \(\bar{\bar{x}}\), deviates from the population mean, \(\mu\).
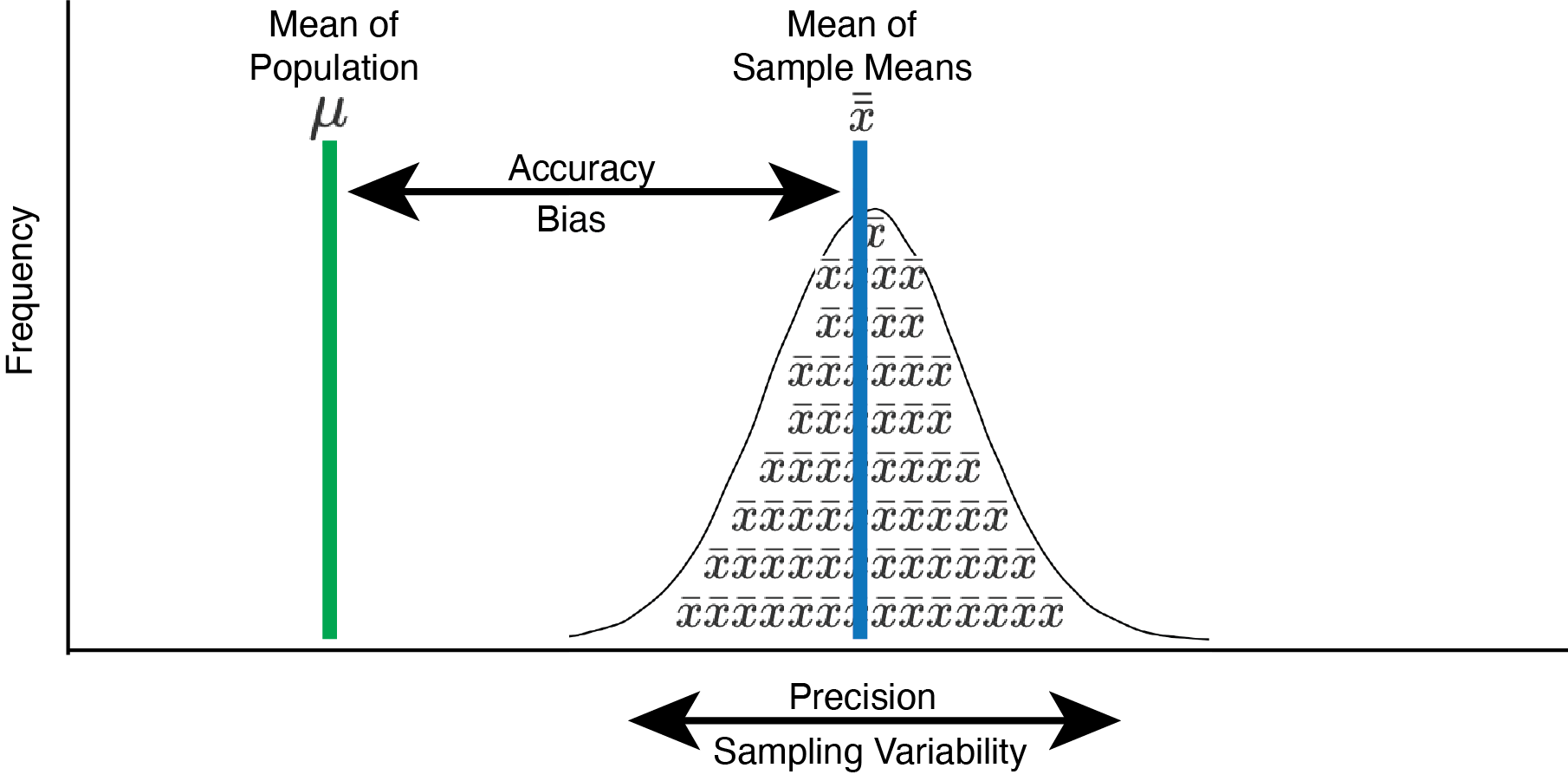
FIGURE 5.1: Sampling accuracy and precision
We can assess bias, as illustrated in the above figure by drawing a large number of samples from a population with the code below. Our goal is calculate a mean for each sample so that we have a sampling distribution of means. In theory, we should take an infinite number of samples, however, to be practical we will take 50000 samples to create an approximate sampling distribution of means. We use the code below to do so:
many_samples <- get_M_samples(pop.data = pop_data,
pop.column.name = height,
n = 10,
number.of.samples = 50000)We use the print() command to see the first few rows of the 50000 samples:
## # A tibble: 50,000 × 5
## study n sample_mean sample_var_n sample_var_n_1
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 10 174.3 27.81 30.9
## 2 2 10 161.8 83.358 92.62
## 3 3 10 173.2 139.158 154.62
## 4 4 10 180 321.804 357.56
## 5 5 10 172.8 160.956 178.84
## 6 6 10 172 159.597 177.33
## 7 7 10 166.5 86.454 96.06
## 8 8 10 173.5 139.446 154.94
## 9 9 10 177.7 167.013 185.57
## 10 10 10 168.5 262.647 291.83
## # ℹ 49,990 more rowsEach row of many_samples represents a sample of 10 people. Each column of many_samples indicates a sample statistic. You can see that for each sample/row we indicate “n” (the sample size) and “sample_mean” (the mean of the population), and a few other statistics. Even though all the samples came from the same population you can see how the values in the sample_mean column vary across samples/rows.
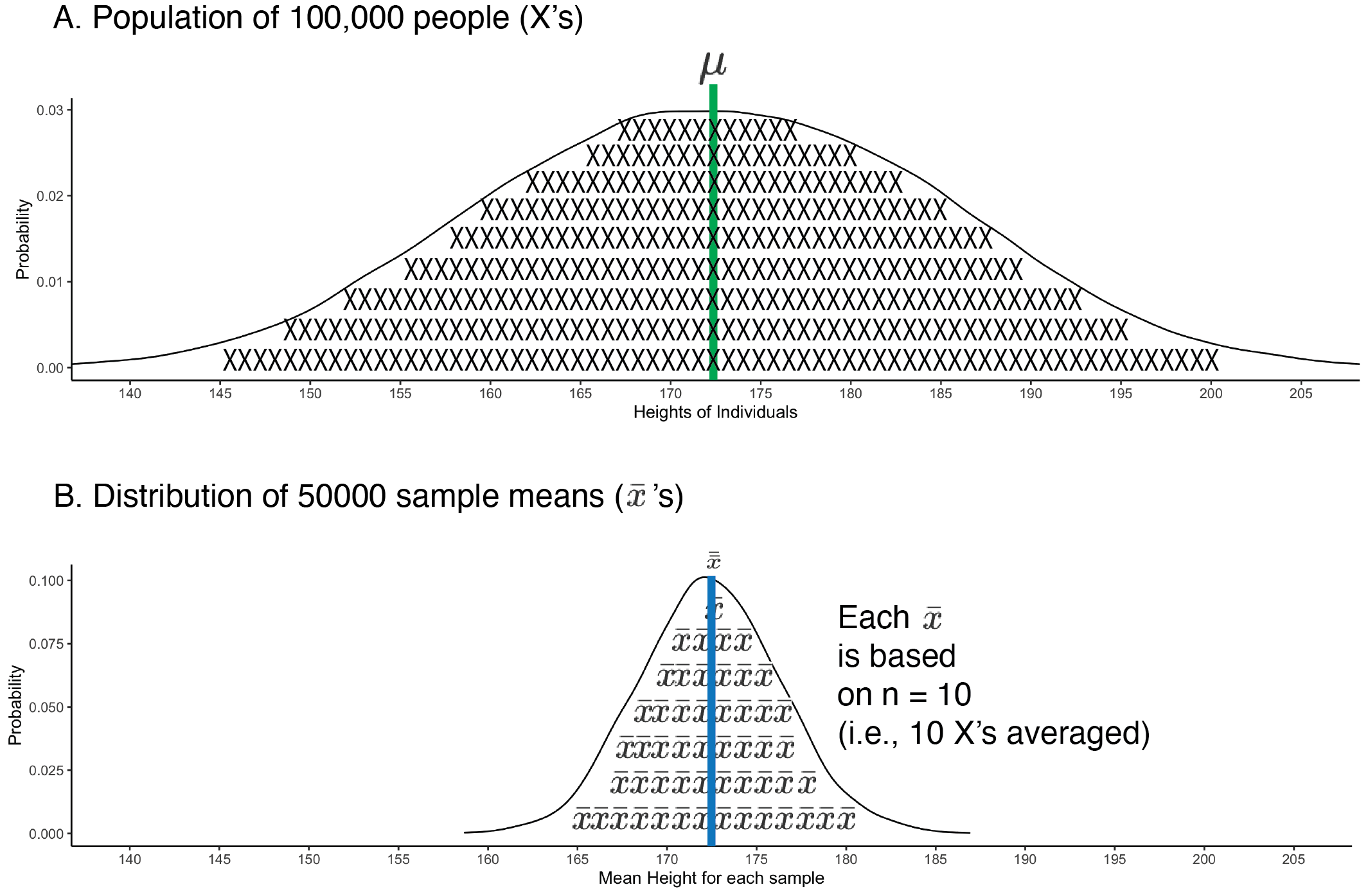
FIGURE 5.2: Sampling distribution of the mean. The population of individuals is presented at the top and filled with X’s to remind you they are individuals. There are more individuals than X’s. The sampling distribution of means is presented in the bottom part of the graph. The sampling distribution of means is filled with \(\bar{x}\)’s to remind you that it is sample means being graphed. There are more means than \(\bar{x}\)’s. The population mean (green line) and the mean of sample means (blue line) are in the same spot, indicating high accuracy (i.e., no bias).
Above, in Figure 5.2, we present a graph comparing the distribution of peoples heights (i.e., the population) to the distribution of sample means based on those heights (i.e., the sampling distribution). The sample means plotted are the 50000 sample means, from the sample_mean column. Recall the population mean for heights is \(\mu = 172.48\) cm. Notice that most of the sample means cluster around this value. Also notice that there is considerable variability about this value. Any given sample mean (\(\bar{x}\)) may differ substantially from the population mean (\(\mu = 172.48\)). This variability illustrates the challenges with learning something from a single study - particularly a study with a small sample size. Many of the sample means fall quite far from the population mean.
5.4.1 Assessing bias
Statisticians, recognizing the limitations of a single study, are not particularly concerned if a single sample mean deviates from the population mean. That said, statisticians are very concerned as to whether or not the results of a large number of studies are correct – on average. That is, does the average of many sample means correspond to the population mean? If, on average, the sample mean does corresponds to the population mean, it is accurate and we refer to it as an unbiased estimator. Visually, this appears to be the case. But in the code below we confirm it numerically.
## # A tibble: 1 × 1
## mean_of_sample_mean
## <dbl>
## 1 172.472The value you obtain may be somewhat different than 172.47 due the fact your random samples were likely different.
We find that the average of the 50000 sample means is 172.47 which is very close to the population mean of 172.50. Note that when we did this, we used the same formula to calculate the sample mean (Formula (5.2)) as we did the population mean (Formula (5.1)), although the notations differed. The average of the sample means was not identical to the population mean but it was very close - it would have been exactly the same with many more samples (i.e., an infinite number of samples). Therefore, we conclude the sample mean provides an unbiased estimate of the population mean. In other words, it makes sense to use the sample mean as an estimate of the population mean. If we try to estimate the population mean with a sample mean we will, on average, be correct; although any given sample/study mean might be “wrong”.
5.5 Estimating \(\sigma^2\)
We are interested in the sample variance (\(s^2\)) to the extent that it provides an estimate of the population variance (\(\sigma^2\)). We begin by reviewing population variance. The population variance is calculated using Formula (5.4):
\[\begin{equation} \sigma^2 = \frac{\sum{(X - \mu)^2}}{N} \tag{5.4} \end{equation}\]
We can calculate the population variance for the height column of pop_data using the summarise() and var.pop() commands. The var.pop() command uses Formula (5.4). We see in the output that the population variance is 157.5 (\(\sigma^2 = 157.5\)).
## # A tibble: 1 × 1
## pop_var
## <dbl>
## 1 156.3225.5.1 Assessing bias
The formula for sample variance with an \(n\) in the denominator is, unfortunately, a biased estimator of population variance (formula below).
\[ \begin{aligned} s^2 = \frac{\sum{(x - \bar{x})^2}}{n} \end{aligned} \]
Estimates of the population variance are systematically too low when you use a sample variance formula with an \(n\) in the denominator. We can see that this is true by examining the many_samples data. In these data, the column sample_var_n contains the variance for the sample calculated with the above formula. Below we use code to obtain the average of the sample_var_n column over the 50000 samples. If this average equals the population variance of 157.5 then variance, using \(n\) in the denominator, is an unbiased estimator of the population variance.
## # A tibble: 1 × 1
## mean_of_var_n
## <dbl>
## 1 141.544You can see the average of sample_var_n column (141.54) is much smaller than the population variance (157.5). That is, the average of the sample variances, using \(n\) in the denominator, was smaller than the population variance. Consequently, sample variance (using \(n\) in the denominator) provides a biased estimate of the population variance. If we try to estimate the population variance with sample variance (using \(n\) in the denominator) we will, on average, be wrong.
Fortunately, there is a sample-level formula that estimates the population variance without bias (see Hayes). An unbiased estimate of the population variance can be obtained if we calculate the sample variance but divide by \(n - 1\) instead of \(n\). The unbiased estimate is calculated using Formula (5.5). The denominator of the formula below indicates the degrees of freedom associated with the variance estimate. More specifically, in this formula there are \(n-1\) degrees of freedom associated with the variance estimate.
\[\begin{equation} s^2 = \frac{\sum{(x - \bar{x})^2}}{n-1} \tag{5.5} \end{equation}\]
In the many_samples data, the column sample_var_n_1 was generated using Formula (5.5). We can evaluate the quality of Formula (5.5), using \(n-1\), by averaging the values in the sample_var_n_1 column.
## # A tibble: 1 × 1
## mean_of_var_n_1
## <dbl>
## 1 157.271We see that the average of the 50000 values using \(n-1\) in the denominator is 157.27 which is very close to the population variance of 157.46. These numbers would have been identical with an infinite number of samples. Consequently, when we use \(n-1\) in the denominator we have an unbiased estimate of the population variance. If we try to estimate the population variance with a sample variance, using \(n-1\) in the denominator, we will, on average, be right.
You may wonder at this point, when we use \(n-1\) in the denominator of the sample variance, can we still think of it as the average of the squared differences from the mean? The short answer is yes. When you use \(n-1\) in the denominator of the sample variance you are not calculating the variance for the group people in the sample. Rather, you are estimating the variance for the much larger group of people in the population. Consequently, it makes sense to think of sample variance, using \(n-1\), as an estimate of the average of the squared differences/errors in the population. That is, it makes sense to think of sample variance, using \(n-1\), as an estimate of the average of the squared differences between each person in the population and the population mean.
5.6 Estimating \(\sigma\)
The population standard deviation is calculated using Formula (5.6) below.
\[\begin{equation} \sigma = \sqrt{\frac{\sum{(X- \mu)^2}}{N}} \tag{5.6} \end{equation}\]
Due to the above findings for variance, we estimate the population standard deviation using Formula (5.7) below.
\[\begin{equation} s = \sqrt{\frac{\sum{(x - \bar{x})^2}}{n-1}} \tag{5.7} \end{equation}\]
5.7 Estimating \(\delta\)
We are interested in the sample standardized mean difference (\(d\)) to the extent that it provides an estimate of the population standardized mean difference (\(\delta\)). The population standardized mean difference is calculated using Formula (5.8) when we work for the assumption that the two population have the same variance / standard deviation:
\[\begin{equation} \delta = \frac{\mu_{1} - \mu_{2}}{\sigma} \tag{5.8} \end{equation}\]
We can calculate the population standardized mean difference for men and women once we have the respective population means and standard deviations. Recall the initial data mixed males and females. We begin by creating separate data sets for males and females:
male_population_heights <- pop_data %>%
filter(sex == "male")
female_population_heights <- pop_data %>%
filter(sex == "female") Next, we calculate the mean and standard deviation of each population:
## # A tibble: 1 × 2
## mean sd
## <dbl> <dbl>
## 1 180.000 10.0036## # A tibble: 1 × 2
## mean sd
## <dbl> <dbl>
## 1 165.000 10.0036This reveals the population parameters are:
\[ \begin{aligned} \mu_{female} &= 165 \\ \mu_{male} &= 180 \\ \sigma = \sigma_{female} = \sigma_{male} &= 10.1\\ \end{aligned} \]
Likewise, as calculated below, the population-level standardized mean difference (\(\delta\)) is 1.49. We can see this population-level difference illustrated in Figure 5.3.
\[ \begin{aligned} \delta &= \frac{\mu_{male} - \mu_{female}}{\sigma} \\ &= \frac{180 - 165}{10.1} \\ &= \frac{15}{10.1} \\ &= 1.49 \\ \end{aligned} \]
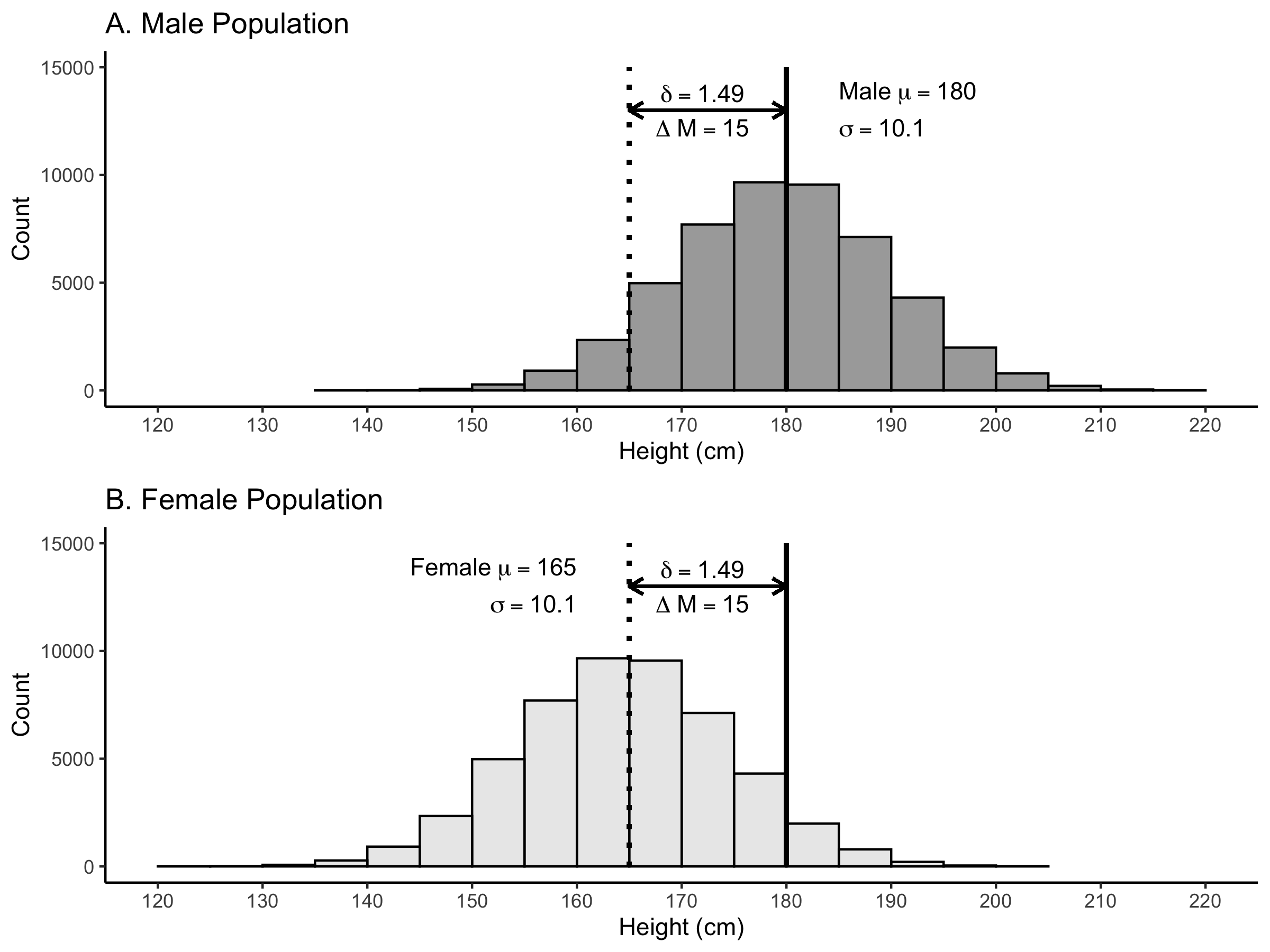
FIGURE 5.3: Illustration of the standardized mean difference of 1.49 for male and female heights. The solid black vertical line indicates the mean for males; whereas the dotted vertical line indicates the mean for females.
We typically need to estimate the population-level standardized mean difference from sample data because we rarely have access to data for an entire population. Many researchers estimate the population standardized mean difference from sample data using the Formula (5.9) below – when we assume the populations have equal variances. This value is known by many other names: \(d\), Cohen’s \(d\), and Hedges’ \(g\). Notice that the sample-level formula, Formula (5.9), below, is the same as the population-level formula, Formula (5.8), above, only the notation differs.
\[\begin{equation} d = \frac{\bar{x}_{1} - \bar{x}_{2}}{s_{pooled}} \tag{5.9} \end{equation}\]
Unfortunately, Formula (5.9) provides a biased estimate of the population standardized mean difference for small sample sizes. That is, on average, Formula (5.9), provides \(d\)-values that overestimate the size of the population standardize mean difference (\(\delta\)). Fortunately, we can obtain an unbiased estimate of the population-level standardized mean difference from sample data using Formula (5.10). This is one approach to calculating \(d_{unbiased}\) – there are others.
\[\begin{equation} d_{unbiased} = \frac{\bar{x}_{1} - \bar{x}_{2}}{s_{pooled}} \times [1 - \frac{3}{4(n_1 + n_2)-9}] \tag{5.10} \end{equation}\]
If we try to apply either \(d\)-value formula ((5.9) or (5.10)) to real data we quickly encounter a problem. We don’t have the pooled standard deviation, \(s_{pooled}\)
5.7.1 Pooled standard deviation
When we calculated the population-level standardized mean difference we knew the population variances were the same. Consequently, there was only one standard deviation (i.e., only one variance). More specifically, the male and female populations both had a standard deviation but it was the same for both populations. The population-level formula for the standardized mean difference, Formula (5.8), has only one standard deviation in it. This is because calculation of the standardized mean difference explicitly depends on the fact that both populations have the same standard deviation.
Let’s consider hypothetical sample data to make the situation clear. More specifically, we will examine the sample-level statistics below for males and females. Notice that we have two standard deviations – one for males and one for females. Moreover, these two sample-level standard deviations (using \(n\)-1) are not the same - they are different from each other. This initially seems problematic - calculation of standardized mean difference requires that population standard deviations are identical.
\[ \begin{aligned} \bar{x}_{males} &= 187.2 \\ s_{males}^2 &= 92.2 \\ s_{males} &= 9.6 \\ \end{aligned} \]
And females:
\[ \begin{aligned} \bar{x}_{females} &= 160.1 \\ s_{females}^2 &= 66.8 \\ s_{females} &= 8.2 \\ \end{aligned} \]
Fortunately, this is sample-level data and not population-level data. Sample-level standard deviations may differ even when the population-level standard deviations are the same. In fact, sample-level standard deviations are likely to differ from the population-level standard deviation due to sampling error. Consequently, we are likely to get two different sample-level standard deviations even if the population-level standard deviations are identical for males and females.
How do we resolve this situation of having two sample-level standard deviations? The first step is to switch to thinking in terms of variance rather than standard deviation. Due to the way the math works, life becomes very complicated, very quickly, if we continue to think in terms of standard deviations. Therefore, we reframe the problem into a variance problem. Variances are preferable to standard deviations because we can add and subtract variances - but not standard deviations.
We have a sample variance for males (92.2) and a sample variance for females (66.8). We view each of these sample variances as an estimate of the respective population variances (see Figure 5.4). That is, the male sample variance is an estimate of the male population variance. Likewise, the female sample variance is an estimate of the female population variance. However, we also assume that the population variances for males and females are the same. Consequently, the male sample variance and the female sample variance are both estimates of the same value (see Figure 5.5). Because the two sample variances are estimates of the same population variance, we can (when the sample sizes are equal) calculate a new variance by averaging them together. This new variance, the average of the sample variances, provides us with a better estimate of the single population variance. The logic behind this approach is similar to averaging two measurements of the same distance to reduce error. We call this new variance pooled variance; and represent it with the symbol \(s_{pooled}^2\).
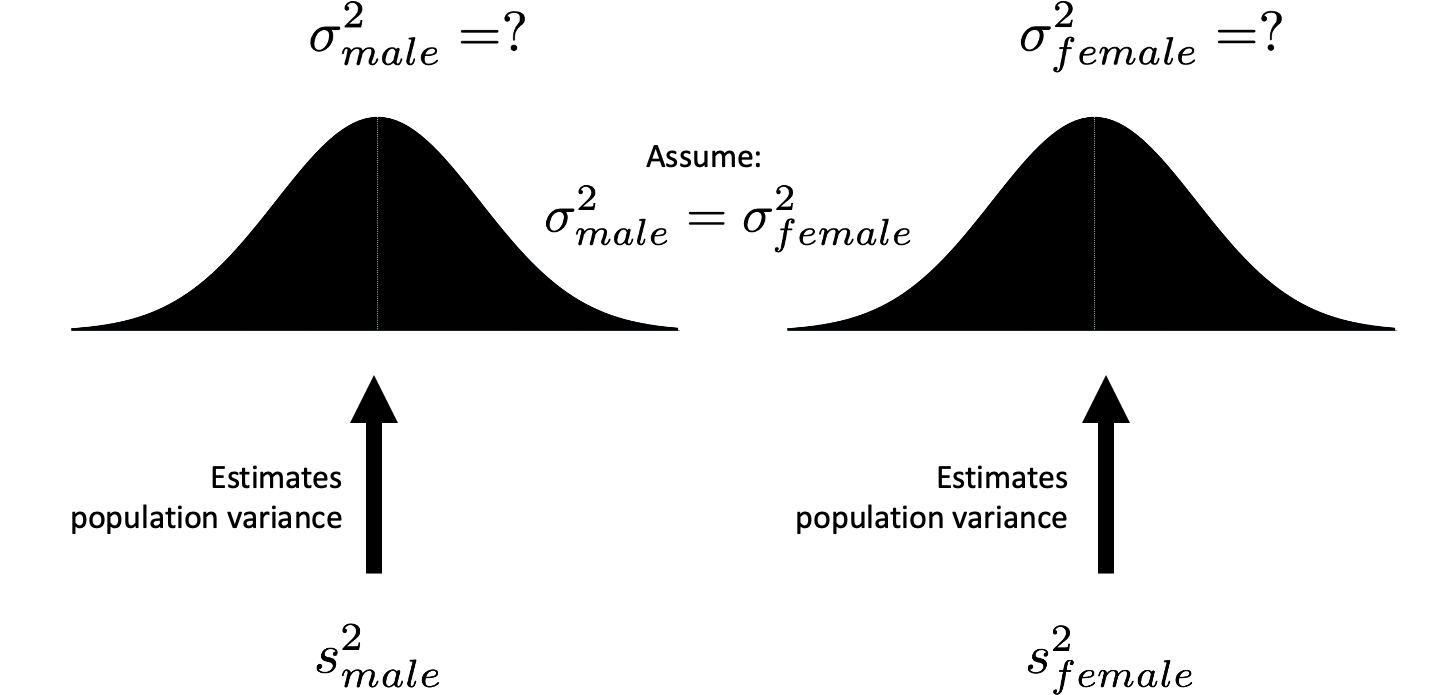
FIGURE 5.4: Estimating population variances with sample variances. The male sample variance (n-1) is an estimate of male population variance. Likewise, the female sample variance (n-1) is an estimate of the female population variance.
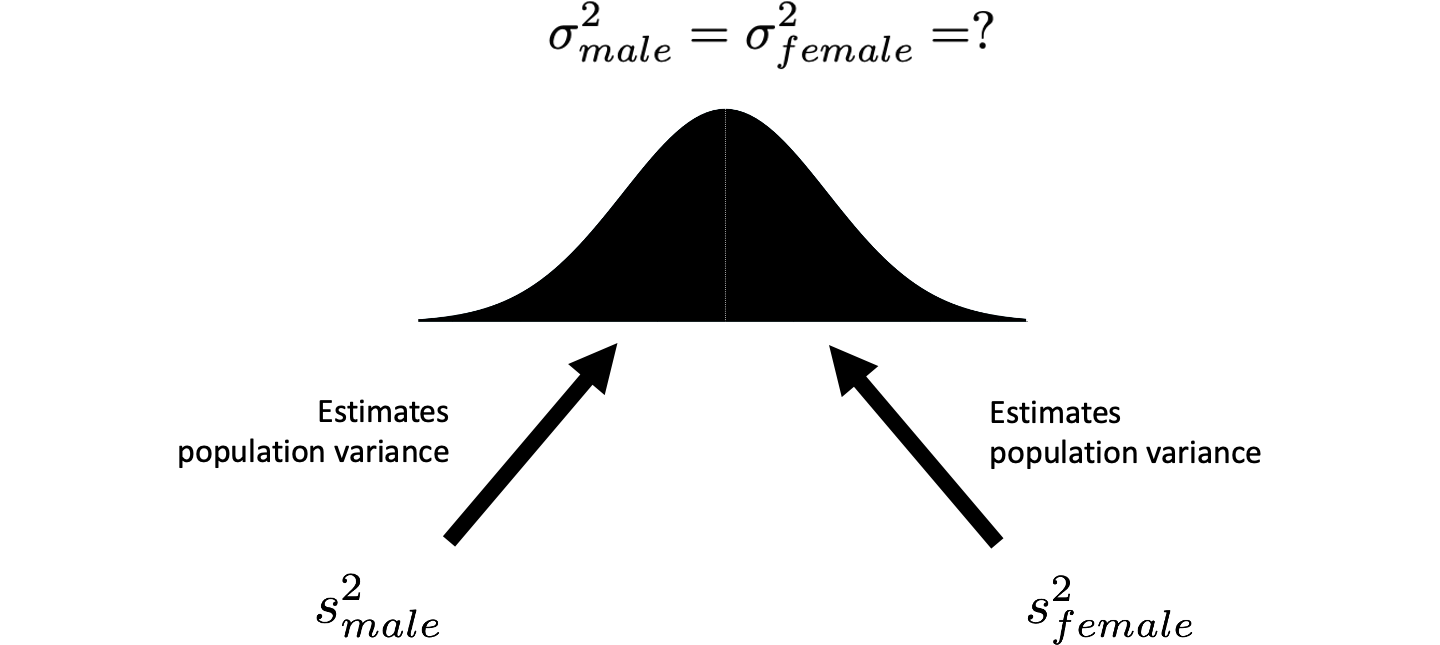
FIGURE 5.5: Two estimates of a single population variance. We assume the population variances are the same. Therefore, the male and female sample variances are both estimates of the same population variance.
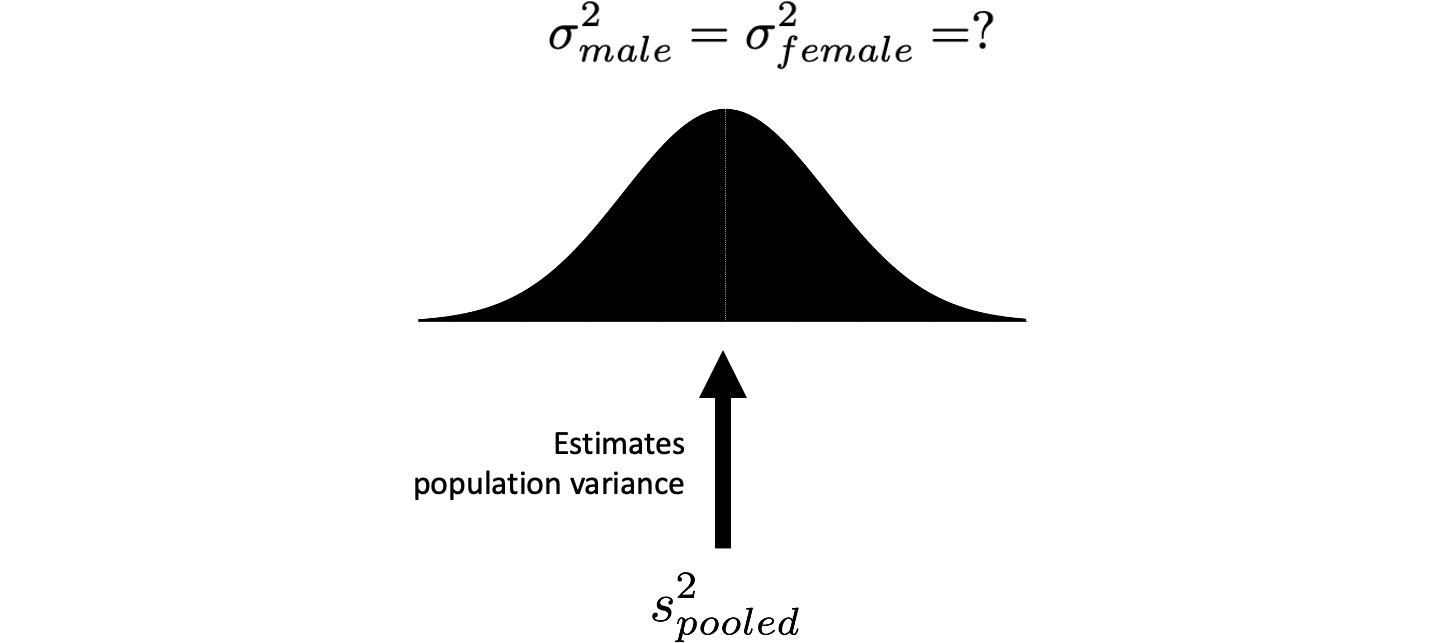
FIGURE 5.6: Pooled variance from the samples estimates population variance. The population variance is estimated by averaging two sample variances into a single estimate called pooled variance (\(s_{pooled}^2\)). When sample sizes are equal, the pooled variance is just the regular/simple average of the two sample variances (both using n-1 in the denominator). When the sample sizes are unequal (i.e., different numbers of males and females), however, we need to use a more sophisticated averaging formula to obtain the pooled variance.
When the sample sizes for males and females are the same (i.e., \(n_{males} =n_{females}\)) we can use the Formula (5.11) below to calculate the pooled variance.
\[\begin{equation} s_{pooled}^2 = \frac{s_{1}^2 + s_{2}^2}{2} \tag{5.11} \end{equation}\]
When the sample sizes for males and females are different (i.e., \(n_{males} \ne n_{females}\)) we can use the Formula (5.12) below to calculate the pooled variance. This formula can be used all of the time. We only show Formula (5.11), above, to make it clear that Formula (5.12) below is basically just averaging the variances in a way that takes sample size into account.
\[\begin{equation} s_{pooled}^2 = \frac{(n_1 -1)s_1^2 + (n_2 -1)s_2^2}{n_1 + n_2-2} \tag{5.12} \end{equation}\]
We get the single standard deviation, \(s_{pooled}\), by taking the square root of the variance, \(s_{pooled}^2\).
\[ \begin{aligned} s_{pooled} &= \sqrt{s_{pooled}^2} \\ \end{aligned} \]
We apply the pooled standard variance, Formula (5.12), to the sample data:
\[ \begin{aligned} s_{pooled}^2 &= \frac{(n_{male} -1)s_{male}^2 + (n_{female} -1)s_{female}^2}{n_{male} + n_{female}-2} \\ &= \frac{(10 -1)92.2 + (10 -1)66.8}{10 + 10 -2} \\ &= 79.5 \end{aligned} \]
Then we obtain the pooled standard deviation, below, for the standardized mean difference formula.
\[ \begin{aligned} s_{pooled} &= \sqrt{79.5} \\ &= 8.9\\ \end{aligned} \]
AN ASIDE ON POOLING. Variance pooling is an extraordinarily important part of statistics - we see it used in many topics. To prepare you for that future learning, examine the more general version of the variance pooling equation below. Go through each line of the math below to see how the pooling formula used above is only a specific case of the more general formula below. No really do it - don’t skip this task! Actually take a minute to understand the general version of the pooling formula below. You’ll thank me in future weeks. This is foundational knowledge.
In the math below we use a = 2 to indicate there are two sample variances being pooled. The denominator of the formula below indicates the degrees of freedom associated with the variance estimate. More specifically, in this formula there are \((n_1-1)+(n_2-1)\) (or \(a(n-1)\)) degrees of freedom associated with the variance estimate.
\[ \begin{aligned} s_{pooled}^2 &= \frac{\sum_{i=1}^{a}(n_i-1)(s_i^2)}{\sum_{i=1}^{a}(n_i-1)} \\ &= \frac{(n_1-1)s_1^2 + (n_2 -1)s_2^2}{(n_1-1)+(n_2-1)} \\ &= \frac{(n_1-1)s_1^2 + (n_2 -1)s_2^2}{(n_1+n_2-2)} \\ &= \frac{(n_{male} -1)s_{male}^2 + (n_{female} -1)s_{female}^2}{n_{male} + n_{female}-2} \\ \end{aligned}\\ \]
Also note the simplification of the general formula below when the sample sizes (\(n_i\)) are all the same. In particular notice how we express the denominator when the sample sizes are the same. This will become relevant when we get to ANOVA. Recall a = 2 to indicate there are two sample variances.
\[ \begin{aligned} s_{pooled}^2 &= \frac{\sum_{i=1}^{a}(n_i-1)(s_i^2)}{\sum_{i=1}^{a}(n_i-1)} \\ &= \frac{(n-1)s_1^2 + (n-1)s_2^2}{a(n-1)} \\ \end{aligned}\\ \]5.7.2 Calculating \(d\)
Recall that in the above we calculated the pooled standard deviation, \(s_{pooled} = 8.9\). Using this value we can calculate the standardized mean difference. We do so below using unbiased formula, Formula (5.10) below.
\[ \begin{aligned} d_{unbiased} &= d \times [1 - \frac{3}{4(n_{males} + n_{females})-9}] \\ &= \frac{\bar{x}_{males} - \bar{x}_{females}}{s_{pooled}} \times [1 - \frac{3}{4(n_{males} + n_{females})-9}] \\ &= \frac{187.2 - 160.1}{8.9} \times [1 - \frac{3}{4(10 + 10)-9}] \\ &= 3.0 \times 0.96\\ &= 2.9\\ \end{aligned} \]
5.7.3 Assessing bias
Sample-level \(d_{unbiased}\)-values, calculated above, often differ from the population-level standardized mean difference (i.e., \(\delta\)) due to sampling error. We can confirm that \(d_{unbiased}\)-values are actually unbiased with a simulation. That is, we can confirm that the average of many \(d_{unbiased}\)-values equals the population standardized mean difference (i.e., \(\delta\)) using a simulation.
First, we obtain the heights from the male and female populations and place them into male_heights and female_heights, respectively.
male_heights <- male_population_heights %>%
pull(height)
female_heights <- female_population_heights %>%
pull(height)Next, we obtain a large number of samples from each population and place them in many_samples.
many_samples<- get_d_samples_from_population_data(pop1 = male_heights,
pop2 = female_heights,
cell.n = 10,
number.of.samples = 50000)We can examine the contents of many_samples using the print() command. Each row of many_samples represents a single study. Each study has two samples: 10 males and 10 females. For both males and females we calculate the mean and variance. As well, we calculate the \(d\) and \(d_{unbiased}\) for each row. If you examine the first row carefully you see that the data in this row corresponds to the hand calculation example.
## # A tibble: 50,000 × 7
## n_per_cell mean1 var1_n_1 mean2 var2_n_1 d d_unbiased
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 10 187.2 92.18 160.1 66.77 3.04 2.91
## 2 10 183 107.33 166 77.78 1.77 1.69
## 3 10 181 39.78 168.8 144.18 1.27 1.22
## 4 10 175.4 80.27 162.5 89.39 1.4 1.34
## 5 10 184.1 90.99 163.6 28.93 2.65 2.54
## 6 10 181.8 96.4 165.6 106.27 1.61 1.54
## 7 10 176.6 97.16 167 161.56 0.84 0.81
## 8 10 188 211.56 160.8 204.62 1.89 1.81
## 9 10 185.3 54.68 165.8 91.51 2.28 2.18
## 10 10 179.3 69.34 161.9 55.43 2.2 2.11
## # ℹ 49,990 more rowsRecall the population-level standardized mean difference, \(\delta\), was 1.49. We can see the extent to which the average of the sample-level \(d\) and \(d_{unbiased}\) values compare to this population-level value.
## # A tibble: 1 × 2
## mean_d mean_d_unbiased
## <dbl> <dbl>
## 1 1.55696 1.49119You can see that the mean of the sample-level \(d\) values is 1.56 which is higher than the population-level standardized mean difference (\(\delta\) = 1.49). In contrast, you can see that the mean of the sample-level \(d_{unbiased}\) values is 1.49 which corresponds to the population-level standardized mean difference (\(\delta\) = 1.49).
5.7.4 Illustrating variability
An inspection of the first few rows of the many_samples data, above, illustrates that many of the \(d_{unbiased}\) values differed from the population-level standardized mean difference of \(\delta = 1.49\). We can see the variability in sample-level \(d_{unbiased}\) values in the histogram below.
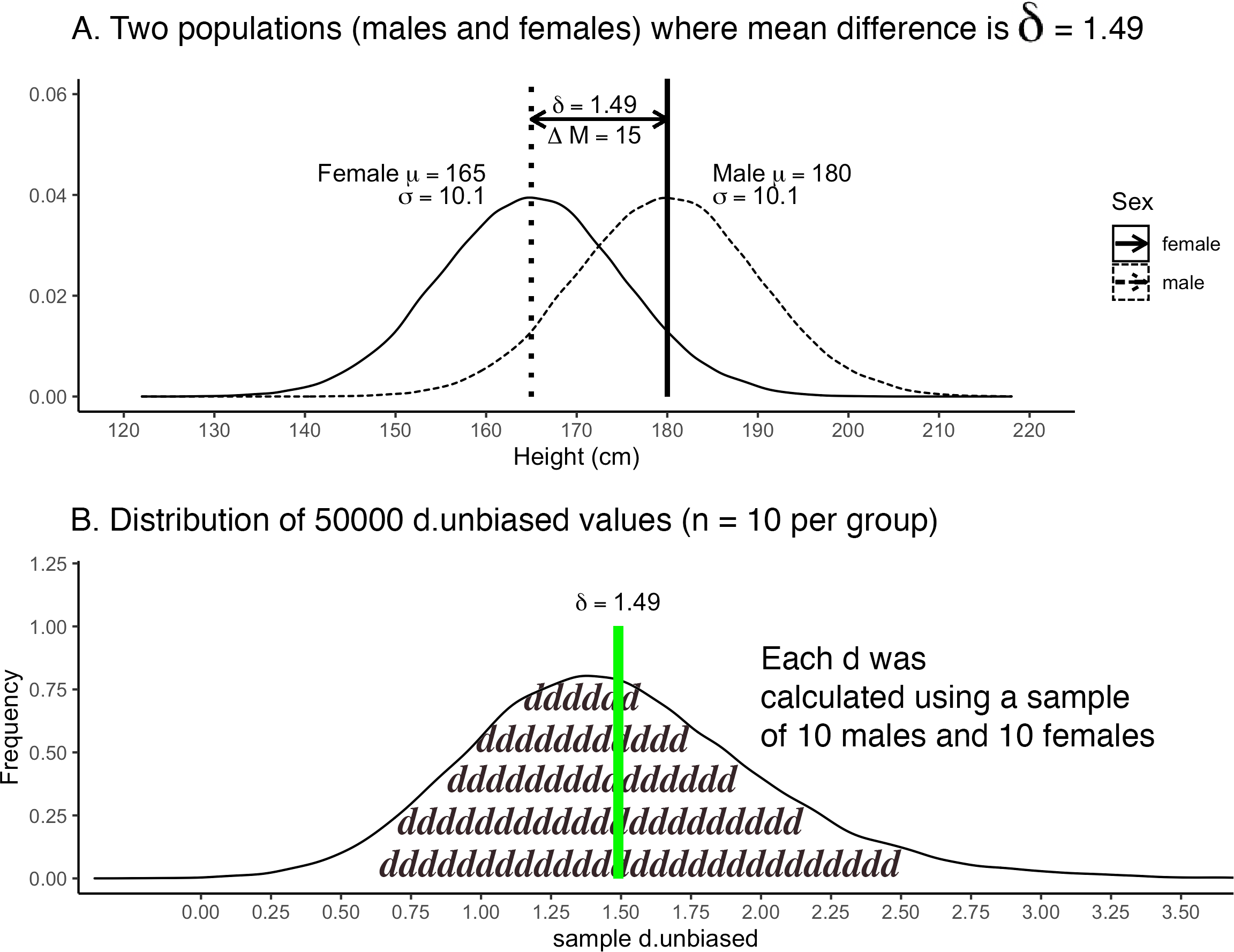
FIGURE 5.7: Histogram of \(d_{unbiased}\) when \(\delta = 1.49\)
We can calculate the full range of sample-level \(d_{unbiased}\) values with the commands below:
## # A tibble: 1 × 2
## d_min d_max
## <dbl> <dbl>
## 1 -0.38 5.15We see from the output that \(d_{unbiased}\) values were as small as -0.38 and as large as 5.15. All of these values are estimates of the population-level standardized mean difference of \(\delta = 1.49\). You can see that many of the sample-level estimates differed considerably from the population-level value. The negative \(d\)-value (i.e., the minimum) is a case where the study (i.e, sample-level result) would have found that women are taller than men - a reversal of what is actually true at the population-level. This range of results illustrates the extent to which the findings for a single sample/study may deviate from the underlying truth for the entire population. We see that when the sample size is small (n = 10 per group) that the study results are likely to differ extraordinarily from what is true at the population level. This suggests that the “old school” suggestion of 10 participants per group when conducting a study leads to findings with little informational value.
5.8 Estimating \(\rho\)
The population-level correlation, \(\rho\), is estimated by the sample-level correlation, \(r\). The value for \(r\) can be calculated using Formula (5.13) below.
\[\begin{equation} r = \frac{\Sigma (x - \bar{x})(y - \bar{y})}{\sqrt{\Sigma (x - \bar{x})^2\Sigma (y - \bar{y})^2}} \tag{5.13} \end{equation}\]
Sample-level correlations, \(r\), often differ from the population-level correlation (\(\rho\)) due to sampling error. We can confirm that sample correlations are not substantially biased with a simulation. That is, we can confirm that the average of many sample correlations (\(r\)) roughly equals the population correlation (\(\rho\)) using a simulation. We say “roughly equal” because \(r\) is technically a biased estimator of \(\rho\) but the bias is sufficiently small that it can be ignored (Schmidt and Hunter 2014).
We have the height and weight for 300000 people that comprise our population (fictious data). This data can be loaded with the command below. The data can be downloaded here: data_cor_pop.csv
## Rows: 300000 Columns: 2
## ── Column specification ──────────────────────────────────────────────────────
## Delimiter: ","
## dbl (2): weight, height
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.The print() command reveals there are 300000 rows and two columns (weight and height). Each row represents a different person in the population.
## # A tibble: 300,000 × 2
## weight height
## <dbl> <dbl>
## 1 143.2 163.1
## 2 155.8 171.4
## 3 143.8 160.4
## 4 152 189.9
## 5 154.8 173.4
## 6 147.1 160.1
## 7 145.1 176.9
## 8 152.9 178.9
## 9 150.8 177.2
## 10 146.5 166.7
## # ℹ 299,990 more rowsWe can obtain the population correlation, \(\rho\), by correlating the weight and height columns:
## weight height
## weight 1.0 0.5
## height 0.5 1.0We see from this matrix that the population correlation (N = 300000) between weight and height is \(\rho\) = .50 (with rounding), see Figure 5.8A.
To examine the extent to which this population correlation, \(\rho\) = .50, is estimated by the sample statistic, \(r\), we need to take a large number of samples. Therefore, we take 50000 samples (each n = 75) and calculate the correlation for each:
set.seed(1)
many_samples <- get_r_samples_from_population_data(data = pop_data,
n = 75,
number.of.samples = 50000)We can examine the first few rows of many_samples using the print() command. There are 50000 rows and each row represent a different sample of 75 people. The correlation between height and weight for each sample is presented in the \(r\) column.
## # A tibble: 50,000 × 3
## sample.number n r
## <int> <dbl> <dbl>
## 1 1 75 0.38
## 2 2 75 0.5
## 3 3 75 0.56
## 4 4 75 0.52
## 5 5 75 0.49
## 6 6 75 0.37
## 7 7 75 0.57
## 8 8 75 0.4
## 9 9 75 0.59
## 10 10 75 0.5
## # ℹ 49,990 more rowsIf you examine the first row carefully you see a sample correlation of \(r = .38\) based on \(n\) = 75. This sample correlation is illustrated in Figure 5.8B and it is just one of the 50000 sample correlations. The distribution of the 50000 sample correlations is illustrated in in Figure 5.8C.
Even though the population correlation is \(\rho = .50\) there is considerable variability in the sample correlations, \(r\). Each sample correlation is based on a subset of the population data (i.e., 75 of the 300000 rows). Consequently, the sample correlations differ from the population correlation due to sampling error. The differences among the sample correlations can be quite large. Indeed, as the code below reveals, some sample correlation were as low as \(r = .06\) and as high as \(r = .77\) – even though the population correlation was \(\rho = .50\).
## # A tibble: 1 × 2
## min_r max_r
## <dbl> <dbl>
## 1 0.06 0.775.8.1 Assessing bias
Even though the sample correlations usually differed from the population correlation we are not concerned. We recognize that there is little to be learned from a single study. We are more concerned as to whether the average of a large number of sample correlations is correct. We assess this with the code below.
## # A tibble: 1 × 1
## mean_r
## <dbl>
## 1 0.497233You can see that the mean of the sample-level correlations is \(\bar{r} = .497\) which is very close to the population-level correlation \(\rho = .50\) (.4999951 without rounding). Consequently, for practical purposes, we don’t worry about the sample correlation being a biased estimator of the population correlation. On average, sample correlation are correct - even though any single sample correlation is likely incorrect due to sampling error (i.e., the fact it is based on a small subset of the population).
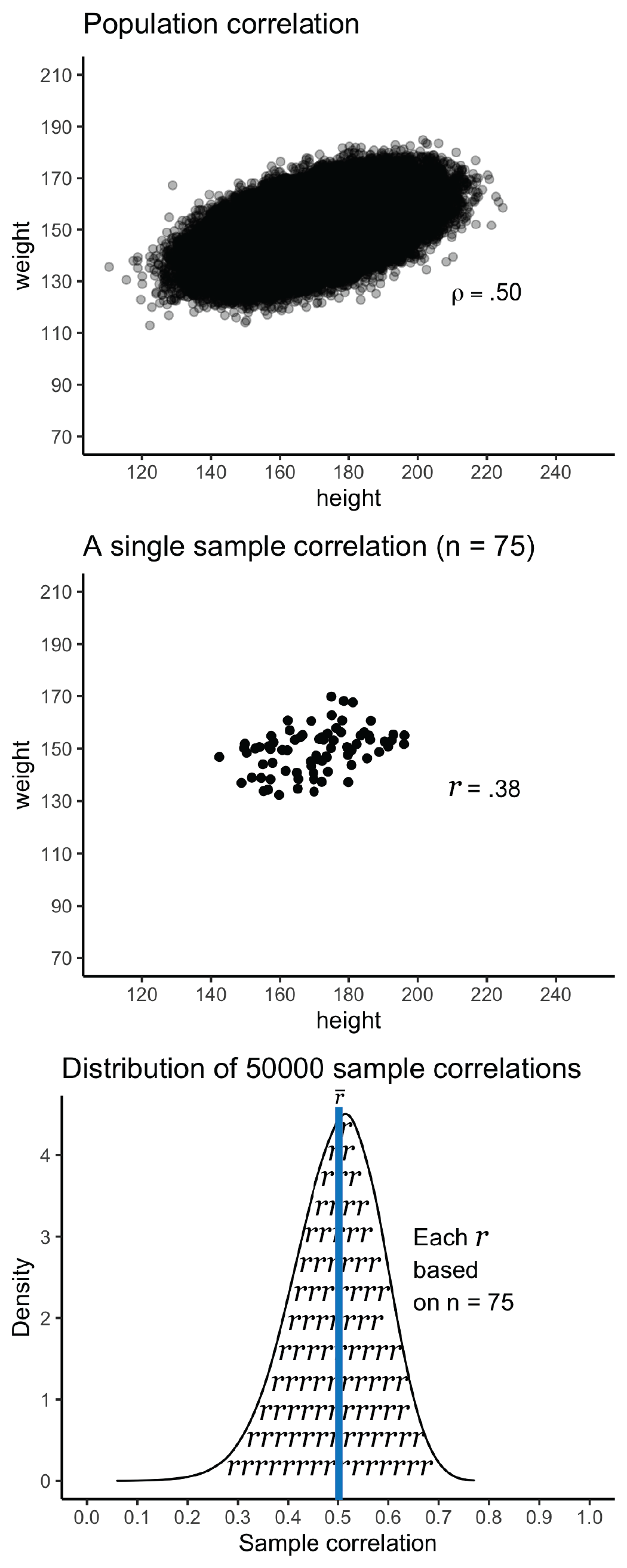
FIGURE 5.8: Correlation sampling distribution
5.9 Overview
In this chapter we have illustrated how population parameters can be estimated by sample statistics; these are summarized below:
| Parameter | Estimated by this statistic | |
|---|---|---|
| Mean | \(\mu = \frac{\sum{X}}{N}\) | \(\bar{x} = \frac{\sum{x}}{n}\) |
| Variance | \(\sigma^2 = \frac{\sum{(X - \mu)^2}}{N}\) | \(s^2 = \frac{\sum{(x - \bar{x})^2}}{n-1}\) |
| \(s_{pooled}^2 = \frac{(n_1 -1)s_1^2 + (n_2 -1)s_2^2}{n_1 + n_2-2}\) | ||
| Standard deviation | \(\sigma = \sqrt{\frac{\sum{(X - \mu)^2}}{N}}\) | \(s =\sqrt{\frac{\sum{(x - \bar{x})^2}}{n-1}}\) |
| \(s_{pooled} = \sqrt{\frac{(n_1 -1)s_1^2 + (n_2 -1)s_2^2}{n_1 + n_2-2}}\) | ||
| Cohen’s \(d\) or SMD | \(\delta= \frac{\mu_{1} - \mu_{2}}{\sigma}\) | \(d = \frac{\bar{x}_{1} - \bar{x}_{2}}{s_{pooled}}\) |
| \(d_{unbiased} = \frac{\bar{x}_{1} - \bar{x}_{2}}{s_{pooled}} \times [1 - \frac{3}{4(n_1 + n_2)-9}]\) | ||
| Correlation | \(\rho = \frac{\Sigma (X - \mu_X)(Y - \mu_Y)}{\sqrt{\Sigma (X - \mu_X)^2\Sigma (Y - \mu_Y)^2}}\) | \(r = \frac{\Sigma (x - \bar{x})(y - \bar{y})}{\sqrt{\Sigma (x - \bar{x})^2\Sigma (y - \bar{y})^2}}\) |
5.10 Meta-analysis
It may seem odd that we used so many simulations to investigate the properties of statistics. Surely, researchers don’t do that “in the real world”. In fact, researchers who are aware of the enormous impact of sampling error know that single studies have little informational value. They recognize that any single study has a high probability of being misleading. Consequently, these individuals survey the literature and find all the studies on a single topic (possibly thousands of studies). An average of the results of all of the thousands of studies can then be calculated and reported. This process is referred to as conducting a meta-analysis; and it perfectly corresponds to the process we used in the simulations. A meta-analysis finds “the truth” of what is happening at the population level by averaging all of the studies on that topic.
5.11 A joke
Now that you understand the logic for assessing bias, we present an old statistics joke.
“A physicist, a chemist, and a statistician go hunting. The physicist shoots at a deer and misses by 2 meters to the left. The chemist shoots and misses by 2 meters to the right. The statistician immediately yells”We got it!”
5.12 Key Points
Samples are of interest because they help us estimate attributes of a population.
Sample statistics estimate population parameters.
Due to the fact that sample statistics are based on a random subset of the population (i.e., a sample) they often differ substantially from the population parameter. This illustrates that informational value of a single study is typically quite low.
A statistic is unbiased if the average of the sample statistics, over many thousand of samples, equals the population parameter.
To avoid bias, sometimes the formula for a sample statistics differs from the formula for the population parameter.
Meta-analyses are used in the “real world” the way we used simulations in this chapter.