Chapter 16 Sampling and N-way ANOVA
16.1 Previously: One-way ANOVA
In the last chapter, we considered a scenario where there was a single independent variable with multiple levels. For example, imagine that we are interested measuring the heights of students (a dependent variable). We might examine how those heights vary across three populations. That is, we could think of university as the independent variable and Waterloo, Western, and Guelph as the levels of that single independent variable, university. In this example, the independent variable (i.e., university) represents a SET of populations and the each level of the independent variable is a specific population (e.g., Waterloo).
16.2 Now: N-way ANOVA
In this chapter, we consider a scenario where there are multiple independent variables. We call it N-way because the N- refers to the number of independent variables. I must stress, however, that you should probably limit the number of independent variables in you study to at most three independent variables. Cognitive psychology research has demonstrated that human beings have a very hard time wrapping their minds around the complexity associated with four independent variables and interpreting five independent variables is practically impossible. My understanding is that, somewhat ironically, 4-way interactions are not uncommon in Cognitive psychology. Be sure to read the article below though so that you can avoid the problems associated with having too many independent variables.
N-way ANOVA differs from one-way ANOVA because you can look how the multiple independent variables combine to influence a dependent variable. When we look at these combined effects we are looking at an interaction (or moderation) effect.
Additionally, because there are multiple independent variables there are multiple sets of populations to consider. For simplicity, we will focus on only two independent variables for this chapter (i.e., a 2-way ANOVA). Specifically, consider a fictitious example where we examine how two independent variables combine to influence how calm students are before an exam. Calmness before the exam is the dependent variable.
The first independent variable is juggling (yes/no) during study breaks. This independent variable has two levels: yes and no. So we think of there being two populations of calmness scores obtained before the exam: 1) a population of calmness scores for students who learned to juggling during study breaks and 2) a population of calmness scores for students who did not learn to juggle during study breaks. We refer to this set of two populations (yes and no juggling) using the label juggling. Juggling is an independent variable or factor in our design. We are interested in how juggling level (yes/no) influences the mean of these two populations of calmness scores. We consider the participants in our study as samples from these two populations.
The second independent variable is preparation (low/medium/high) time before the exam. That is, how much students studied before the exam. This independent variable has three levels: low, medium, and high. So we think of there being three populations of calmness scores obtained before the exam: 1) a population of calmness scores where students prepared a low amount of time, 2) a population of calmness scores where students prepared a medium amount of time, and 3) a population of calmness scores where students prepared a high amount of time. We refer to this set of three populations (low, medium, and high preparation) using the label preparation. Preparation is an independent variable or factor in our design. We are interested in how preparation level (low/medium/high) influences the mean of these three populations of calmness scores. We consider the participants in our study as samples from these three populations.
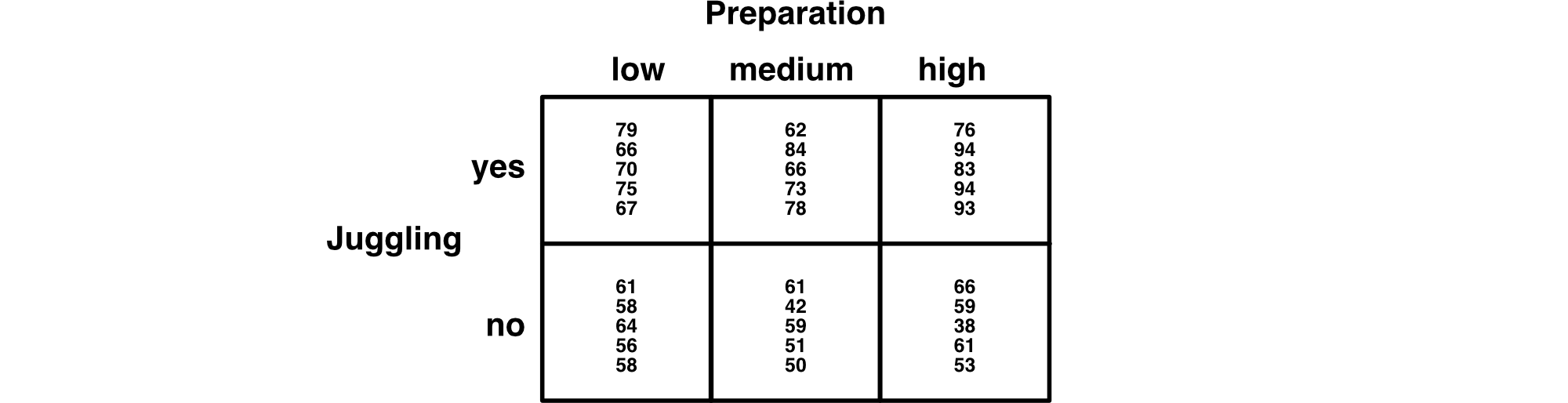
As mentioned previously, an advantage of conducting a 2-way ANOVA over two 1-way ANOVAs is that we get to look at how calmness scores are influenced by the combined effect of the two independent variables. You can see this in the diagram below - there are six cells each of which is created by the combination of one level of juggling and one level of preparation. We call this a fully-crossed design because there are people at every combination of juggling and preparation levels. When we examine cells we are looking at the combined effect of independent variables on the dependent variable. When we do this, we typically say we are examining how the independent variables interact to influence the dependent variable. You can this of the six cells are another set of populations. We will see people that you can think of each set of populations as a frame of reference.
16.3 Output
We begin by creating the output for this design in R. First we activate the required packages:
library(tidyverse)
library(apaTables)
nway_data = read_csv("data_crf.csv")
# Turn character columns into factors
nway_data <- nway_data %>%
mutate_if(is.character, as.factor)Next we conduct the analysis:
# set contrasts to values match SPSS
options(contrasts = c("contr.sum", "contr.poly"))
# Conduct analysis
lm_nway <- lm(calm ~ preparation*juggling,
data = nway_data)Then we create the output using:
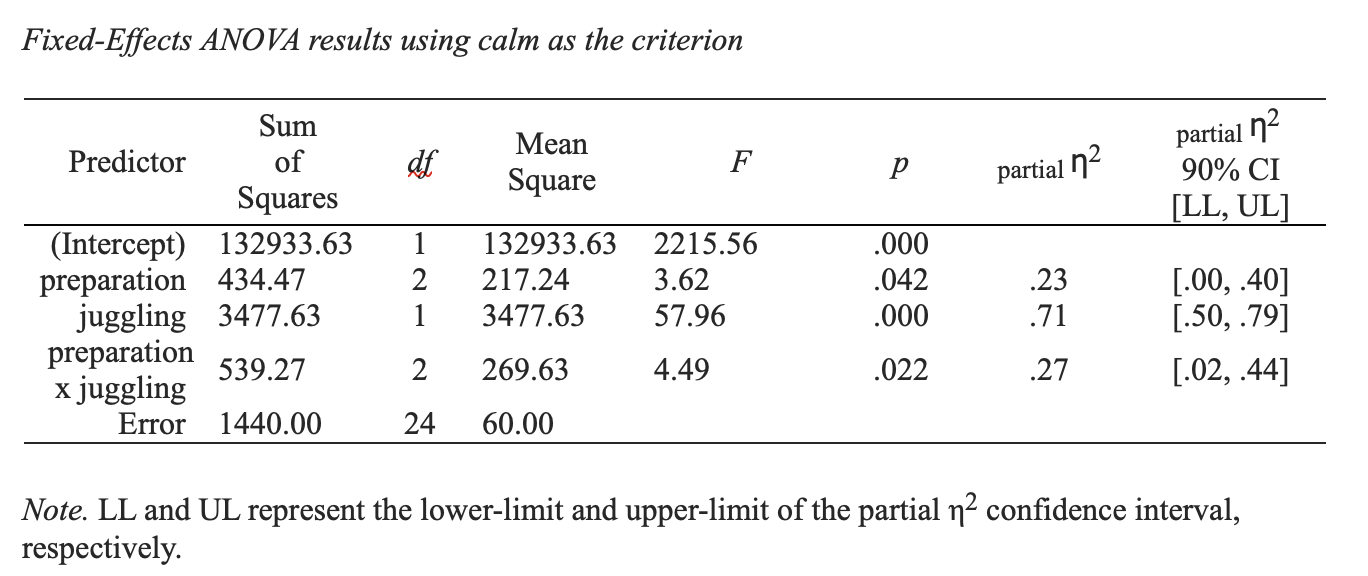
Notice the preparation, juggling, and preparation x juggling rows on this table. In particular, the \(F\)-value for each of these rows. In the remainder of the chapter we will review how these values are obtained - and their conceptual meaning.
16.4 Multiple frames of reference
A complication many students experience with understanding the different frames of reference that can be used with N-way ANOVA is the notation. Particularly when it comes the different sample sizes involved in this design. Therefore, prior to continuing we’ll review some key notation.
The notation is general in nature because each experiment will have different independent variables. A common way to refer to the first independent variable using symbolic notation is by using an uppercase \(A\). Likewise, we refer to the number of levels in that independent variable using lowercase \(a\). Thus, for the first independent variable \(A\) = “Juggling” and \(a = 2\) because there are two levels of juggling (yes or no). So instead of saying we are examining the effect of juggling on calmness we might say we are examining the effect of Independent Variable \(A\) on the dependent variable. For the second independent variable we use uppercase \(B\) and lowercase \(b\), and so on. The table below illustrates how we represent both independent variables in this experiment.
| Effect | Letter designation | Number of levels | Levels |
|---|---|---|---|
| Independent variable 1 | \(A\) = Juggling | \(a = 2\) | yes, no |
| Independent variable 2 | \(B\) = Preparation | \(b = 3\) | low, medium, high |
There are three frames of reference we will use for this 2-way ANOVA. The key to understanding these frames of reference is to think in terms of populations that are represented in your experiment. These population were mentioned previously, but we’ll review them in more detail below.
16.5 Frame 1: Cell Populations
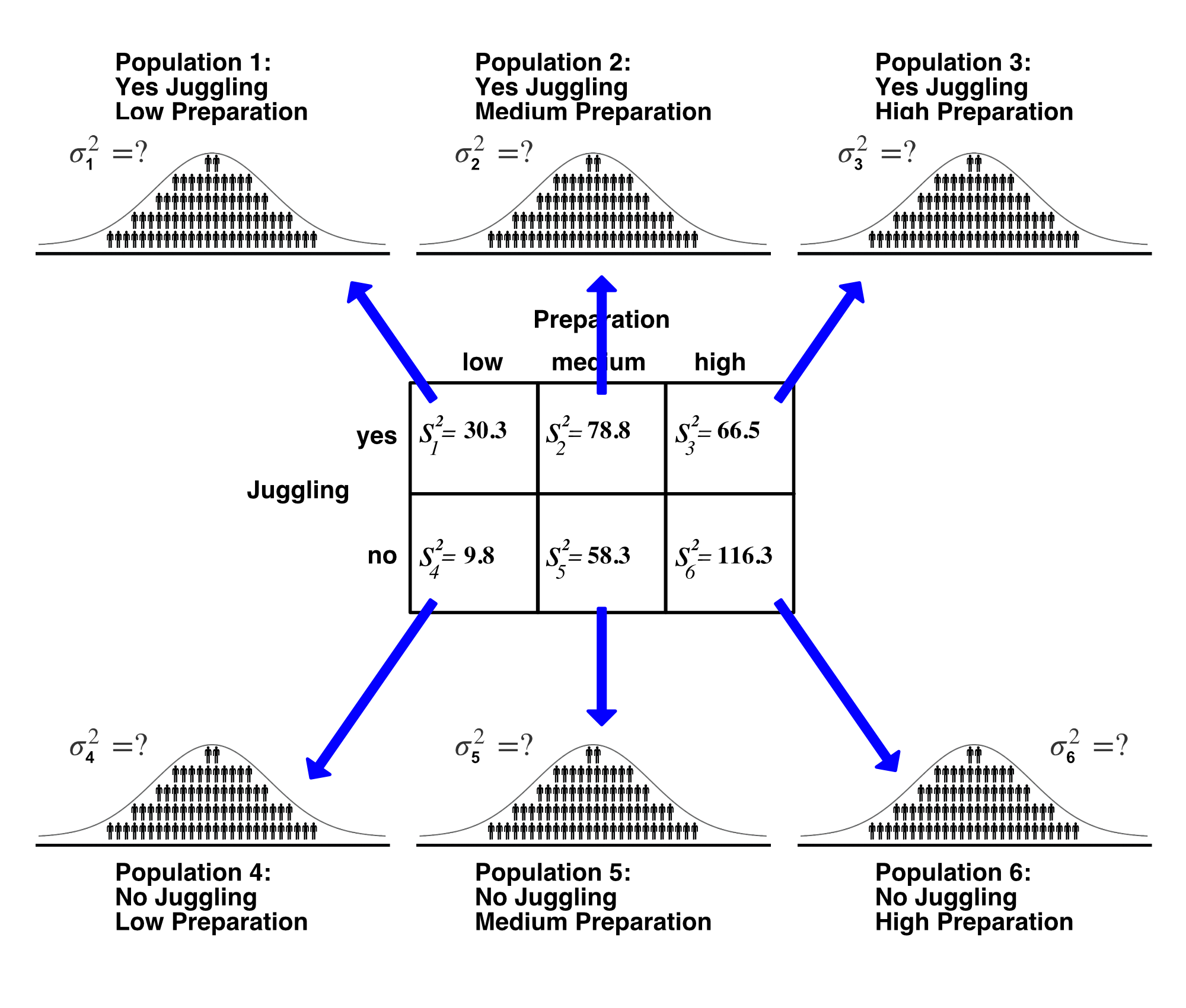
With this first frame of reference we look at combinations of the levels of the \(A\) and \(B\) independent variables (i.e., juggling and preparation). Recall we refer to each combination of levels as a cell. For example, individuals that both juggled during breaks (i.e., yes level of juggling) and prepared for a low amount of time (i.e., low level of preparation), would be in one cell. As mentioned previously, be sure to think in terms of populations. In this study, for this frame of reference, we can calculate the total number of populations by multiplying the number of levels for the independent variables. Here, \(a = 2\) (two levels of juggling) and \(b =3\) (three levels of preparation). Thus, \(ab=(2)(3)=6\), so there are six cell populations. The participants in each cell are a sample from a corresponding cell population. The six cell populations are illustrated below.
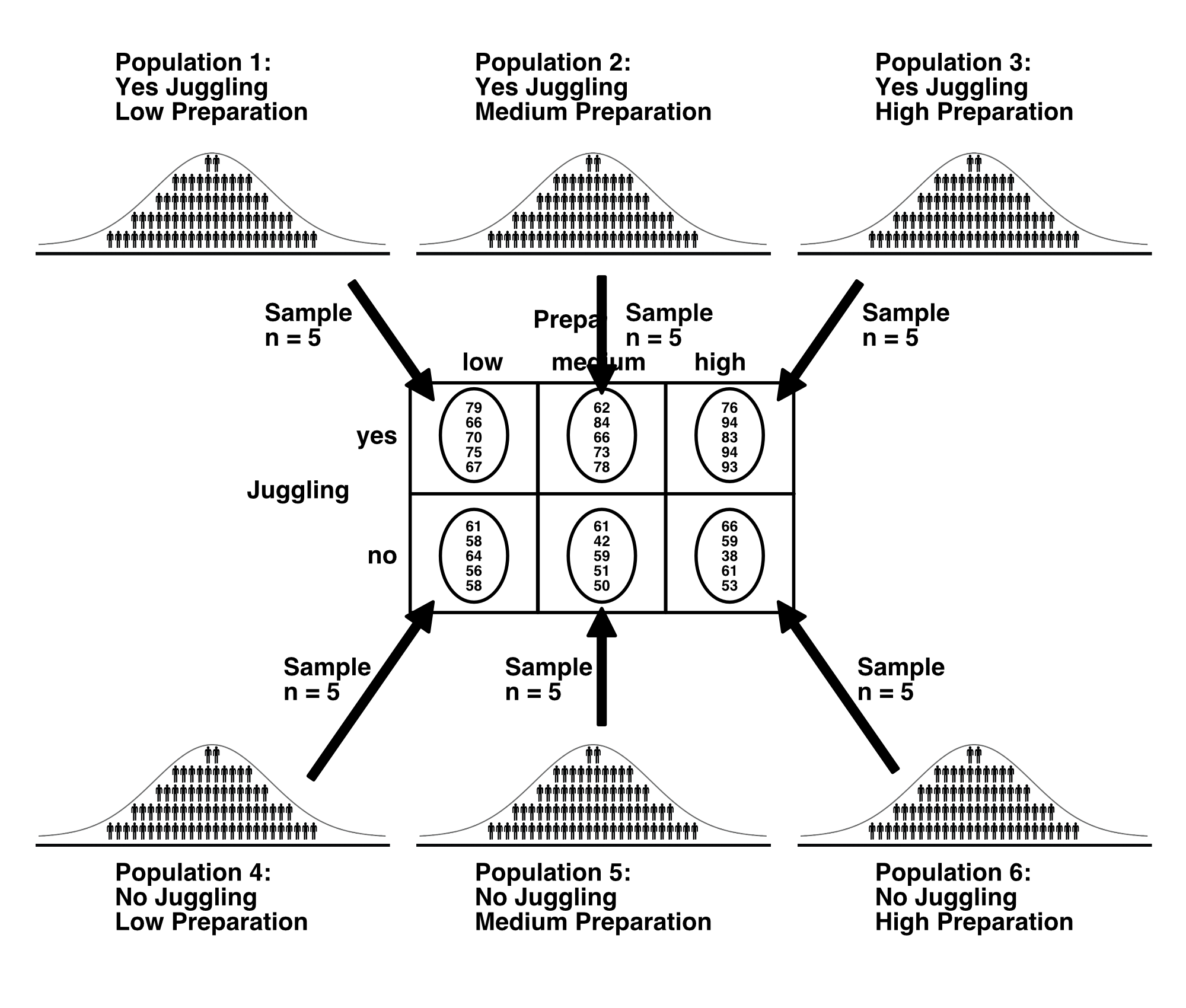
For example, there is a single population (Population 1) that is composed of people who juggled during breaks and prepared for a low amount of time. The participants in Cell 1 are a sample (\(n = 5\) ) from the No Juggling Low Preparation Population.
We look at the means of these six cells when we are examining an interaction among the independent variables.
16.6 Frame 2: \(A\) Populations (Juggling)
The second frame of reference we examine is that of the first independent variable (i.e., \(A\)). We examine the effect of juggling (i.e., \(A\)) on calmness ignoring the effect of preparation (i.e., \(B\)).
Within this frame of reference we imagine that there are two populations of calmness scores; one for each level of juggling. Note that the sample size is different for this frame of reference. For each level of juggling, the sample size is 15. Thus, if you were comparing the yes juggling population to the no juggling population each sample mean would would be based on 15 people. This should be clear when you look at the diagram below.
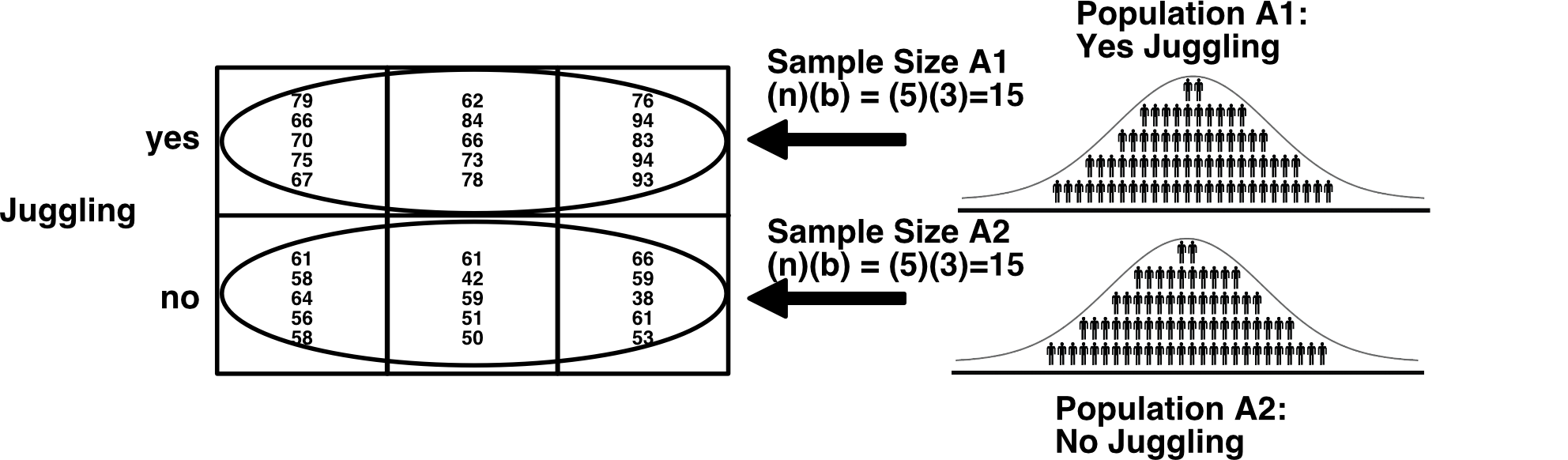
Unfortunately, students often struggle when presented with the sample size as a calculation with symbolic notation. Recall that we we use \(n = 5\) to refer the number of people in each cell, \(a = 2\) to refer to the number of juggling levels, and \(b = 3\) to refer to the number of preparation levels.
When we want to know the sample size for an \(A\) mean we simply multiply the cell size (\(n = 5\)) by the number of levels of B (i.e., \(b = 3\)) to obtain 15. This is confusing for some people because even though you want to calculate the sample size of the means for \(A\) you use \(b\) in the calculation. But if you look at the diagram above, it should be clear why this is the case.
\[ \begin{aligned} \text{Sample Size A} &= nb\\ &= 5\times3\\ &= 15\\ \end{aligned} \]
Note when you examine the means for Juggling we refer to this using a few different phrases:
- Examining the Main effect of \(A\)
- Examining the Margin means for \(A\)
- Examining the Main effect of Juggling
- Examining the Margin means for Juggling
But again remember we are using sample means to make inferences about population means. Never forget the conclusions we make are at the population level - not the sample level.
16.7 Frame 3: \(B\) Populations (Preparation)
The third frame of reference we examine is that of the second independent variable (i.e., \(B\)). That is, we examine the effect of preparation (i.e., \(B\)) ignoring the effect of juggling (i.e., \(A\)).
Within this frame of reference we imagine that there are three populations; one for each level of preparation. Note that the sample size is again different for this frame of reference. For each level of preparation, the sample size is 10. Thus, if you were comparing the mean for the low preparation population to the medium population each sample mean would would be based on 10 people. This should be clear when you look at the diagram below.
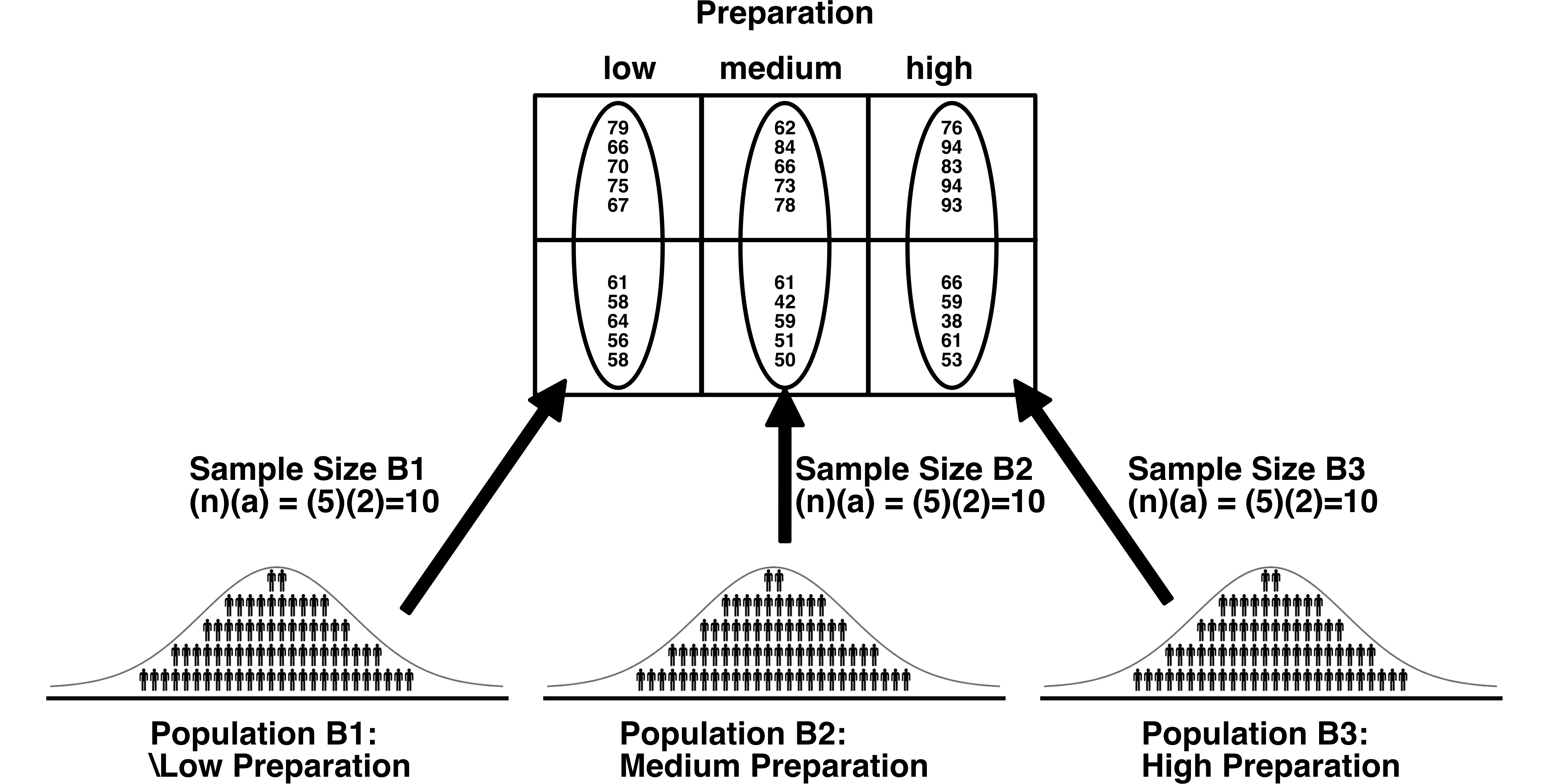
When we want to know the sample size for a \(B\) mean we simply multiply the size size (\(n = 5\)) by the number of levels of \(A\) (i.e., \(a =2\)). This is confusing for some people because even though you want to know the sample size of the means for \(B\) you use \(a\) in the calculation. But if you look the diagram above, it should be clear why this is the case.
\[ \begin{aligned} \text{Sample Size B} &= na\\ &= 5\times2\\ &= 10\\ \end{aligned} \]
Note when you examine the means for Preparation we refer to this using a few different phrases:
- Examining the Main effect of \(B\)
- Examining the Margin means for \(B\)
- Examining the Main effect of Preparation
- Examining the Margin means for Preparation
But again remember we are using sample means to make inferences about population means. Never forget the conclusions we make are at the population level - not the sample level.
16.8 ANOVA by another name
A rose by another name would smell as sweet
ANOVA by another name would be just as useful
As noted, some researchers use the world factor to refer to an independent variable. An implication of this is that instead of using the term N-way ANOVA they use the term Completely Randomized Factorial Design or CRF Design. So be aware there are many ways to refer to an ANOVA design.
Likewise, note that in some research areas, they use a different word for interaction, namely the synonym moderation. That is, although many research areas would say: “We examined how juggling and preparation interacted to influence calmness scores”. Other research areas might phrase it as 1) “We examined how the effect of juggling on calmness scores was moderated by preparation” or, the other way around, 2) “We examined how the effect of preparation on calmness scores was moderated by juggling”. Mathematically, these three ways of describing the combined effect of the independent variables (or factors) on the dependent variable are identical. Conceptually, the two moderation examples differ, but surprisingly not in the math we use to test them.
16.9 Homogeneity of variance
As we saw in previous sections, depending on the effect you are interested in, the relevant populations (i.e., frame of reference) can be quite different. However, regardless of the frame of reference, we assume the variance of people’s calmness scores (\(\sigma_{people}^2\)) is the same across populations.
For the cell frame of reference, we assume the variance of calmness scores in all six populations of calmness scores (\(\sigma_1^2,\sigma_2^2,\sigma_3^2,\sigma_4^2,\sigma_5^2,\sigma_6^2\)) is the same. Using symbols, we indicate that there a single value, \(\sigma_{cells}^2\), for the variance of calmness scores at the population level across the six cells:
\(\sigma_{cells}^2=\sigma_1^2=\sigma_2^2=\sigma_3^2=\sigma_4^2=\sigma_5^2=\sigma_6^2\)
For the effect of \(A\) frame of reference (i.e., juggling), we assume the variance of calmness scores in both juggling populations (\(\sigma_{A1}^2,\sigma_{A2}^2\)) is the same. Using symbols, we indicate that there a single value, \(\sigma_{A}^2\), for the variance of calmness scores at the population level across the both populations.
\(\sigma_{A}^2=\sigma_{A1}^2=\sigma_{A2}^2\)
For the effect of \(B\) frame of reference (i.e., preparation), we assume the variance of calmness scores in all three preparation populations (\(\sigma_{B1}^2=\sigma_{B2}^2=\sigma_{B3}^2\)) is the same. Using symbols, we indicate that there a single value, \(\sigma_{B}^2\), for the variance of calmness scores at the population level across the three populations.
\(\sigma_{B}^2=\sigma_{B1}^2=\sigma_{B2}^2=\sigma_{B3}^2\)
But most importantly we assume the variance of calmness scores is the same across all three frames of reference. That is, there is a single value that represents the variance of population-level calmness scores regardless of the population set. We refer to this as value the variance of people’s calmness score and represent it with the symbol: \(\sigma_{people}^2\)
So:
\(\sigma_{people}^2 =\sigma_{cells}^2=\sigma_{A}^2=\sigma_{B}^2\)
We typically refer to this as the homogeneity of POPULATION variances assumption. With this assumption, in this example, we are referring the variance of participants calmness scores across the populations in the variance frames of reference.
16.10 Estimating population variance
Let’s start by considering the cell frame of reference. Within this frame of reference there are six populations of calmness scores and we have a sample (\(n =5\)) from each population. We can estimate each of the six population variances using this data. To do so, however, we need the sample mean for each of the six cells. So we calculate those means (\(\bar{x}\)) first.
16.10.1 Sample means
We calculate the sample means for each cell using the formula below:
\[ \bar{x} = \frac{\sum x_i}{n} \]
We use this formula in each of the cells:

Each of these six cell means (i.e., sample means) is an estimate of the corresponding six population means.
16.10.2 Population variance estimates
Now that we have the mean for each cell we can estimate the variance of calmness scores for the six populations. We do this with the usual equation below:
\[ s^2 = \frac{\sum (x_i - \bar{x}^2)}{n-1} \]
We use this formula in each of the cells:

As noted above, it’s important to remember that each sample variance (e.g., \(s_1^2\)) is an estimate of the corresponding population variance (e.g., \(\sigma_1^2\)). This is illustrated in the figure below.
16.10.3 Averaging variances
In the previous section, we started from the premise that there were six populations. The populations variances (\(\sigma^2\)) are unknown but we calculated an estimate of each population variance (\(s^2\)) using sample data. These are presented in the table below:
| Cell | Juggling level | Preparation level | Population variance | Sample estimate |
|---|---|---|---|---|
| 1 | yes | low | \(\sigma_1^2\) | \(s_1^2 = 30.3\) |
| 2 | yes | medium | \(\sigma_2^2\) | \(s_2^2 = 78.8\) |
| 3 | yes | high | \(\sigma_3^2\) | \(s_3^2 = 66.5\) |
| 4 | no | low | \(\sigma_4^2\) | \(s_4^2 = 9.8\) |
| 5 | no | medium | \(\sigma_5^2\) | \(s_5^2 = 58.3\) |
| 6 | no | high | \(\sigma_6^2\) | \(s_6^2 = 116.3\) |
Recall, however, the homogeneity of population variances assumption. We assume \(\sigma_{people}^2=\sigma_1^2=\sigma_2^2=\sigma_3^2=\sigma_4^2=\sigma_5^2=\sigma_6^2=\sigma^2=?\).
Consequently, the sample variance estimates (\(s_1^2\), \(s_2^2\), \(s_3^2\), \(s_4^2\), \(s_5^2\), \(s_6^2\)) are estimates of the same population value of calmness scores, \(\sigma_{people}^2\).
Therefore, a better way to display the population variance estimates is with the table below.
| Population Variance | Sample Estimates |
|---|---|
| \(\sigma_{people}^2\) | \(s_1^2 = 30.3\), \(s_2^2 = 78.8\), \(s_3^2 = 66.5\) \(s_4^2 = 9.8\), \(s_5^2 = 58.3\), \(s_6^2 = 116.3\) |
CRITICAL: When we ASSUME the six sample estimates (\(s_1^2\), \(s_2^2\), \(s_3^2\), \(s_4^2\), \(s_5^2\), \(s_6^2\)) are all estimates of the same population value, \(\sigma_{people}^2\), we can combine the sample estimates (i.e., average them) to get a best estimate of the population value (i.e., \(s_{people}^2\)). This makes sense because, with the identical population variances assumption, each sample variance estimate (e.g., \(s_1^2\)) only differs from the population variance (\(\sigma_{people}^2\)) due to random sampling error. By averaging the sample estimates (\(s_1^2\), \(s_2^2\), \(s_3^2\), \(s_4^2\), \(s_5^2\), \(s_6^2\)) we are “averaging out” the random sampling error.
We use the formula below to average the cell variances when the sample sizes for the 6 cells are identical. That is, all \(n = 5\).:
\[ \begin{aligned} s_{people}^2 =\frac{s_1^2 + s_2^2 + s_3^2 + s_4^2 + s_5^2 + s_6^2}{6}\\ &= \frac{30.3 + 78.8 +66.5 +9.8 +58.3 +116.3 }{6} \\ &= 60 \end{aligned} \]
Thus, our best sample-based estimate of the variance of calmness scores in the population is \(s_{people}^2 = 60.00\).
We averaged, or took the mean of, six sample based estimates to obtain \(s_{people}^2\). Most people refer to \(s_{people}^2\) as Mean Squared Error or MSE. You can think of Mean Squared Error as a synonym for estimated population variance.
\(\text{Mean Squared Error} = MSE = s_{people}^2 = 60.0\)
CRITICAL: Note that averaging the sample variances estimates ONLY MAKES SENSE if we assume the six population variances are all the same. It only makes sense to average the sample variance estimates if they are all estimates of a single population value. Thus, calculation of Mean Squared Error only makes sense if the homogeneity of population variances assumption is true. Also note that when the cell sizes are unequal you need to created a weighted average of the sample variance estimates - this math is not reviewed in detail for the sake of a simple narrative.
We now in the following situation:
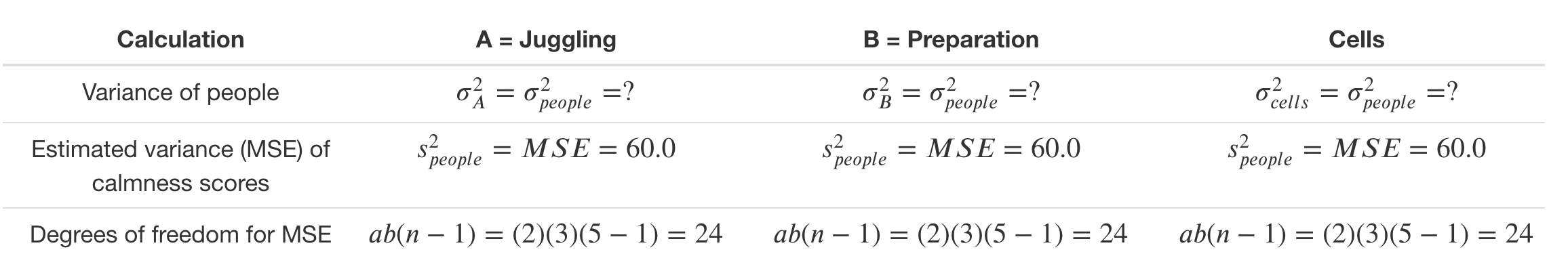
Notice the degrees of freedom for MSE. Recall that when we calculated MSE (i.e., \(s_{people}^2\)) we averaged 6 cell variance estimates (e.g., \(s_1^2\)). Each of those six estimates had \(n-1\) degrees for freedom. You know it’s \(n-1\) degrees of freedom for each cell variance (e.g., \(s_1^2\)) because that’s the denominator of the variance formula (\(s^2 = \frac{\sum (x_i - \bar{x}^2)}{n-1}\)). So the degrees of freedom for \(s_{people}^2\) (i.e., MSE) is \(6(n-1)\) because there were six cell estimates we combined.
Symbolically, we express the calculation of degrees of freedom as \((3)(2)(n-1)\) which is \(ab(n-1)\). So the degrees of freedom for \(s_{people}^2\) (i.e., MSE) is \(ab(n-1)\). It’s important to know this tidbit so that you will understand where all the numbers in a 2-way ANOVA table come from when we examine it later.
16.11 Random Sampling Variance
As we learned in the 1-way ANOVA chapters, an important part of ANOVA is determining if the variability in sample means is greater than could be expected due to random sampling error. Consequently, we have to estimate how much random sampling error variance there would be (on average) in sample means for each of the three frames of reference (main effect of \(A\) means, main effect of \(B\) means, and cell means).
To estimate the expected variability in sample means due to sampling error we need an estimate (\(s_{people}^2\)) of the population variance (\(\sigma_{people}^2\)). That’s why we spent so much time obtaining \(s_{people}^2\) in the previous section. Recall the general form of the formula for the expected variance in sample means, due to sampling error, from previous chapters:
\[ \begin{aligned} \text{Sampling error variance for means} &= \sigma_{\bar{x}}^2 \\ &= \frac{\sigma_{people}^2}{\text{sample size}}\\ \end{aligned} \]
The formula above, for the variability due to sampling error alone, is called Expected Variance, and is reviewed extensively in past chapters.
16.11.1 Expect Variance \(A\): Juggling
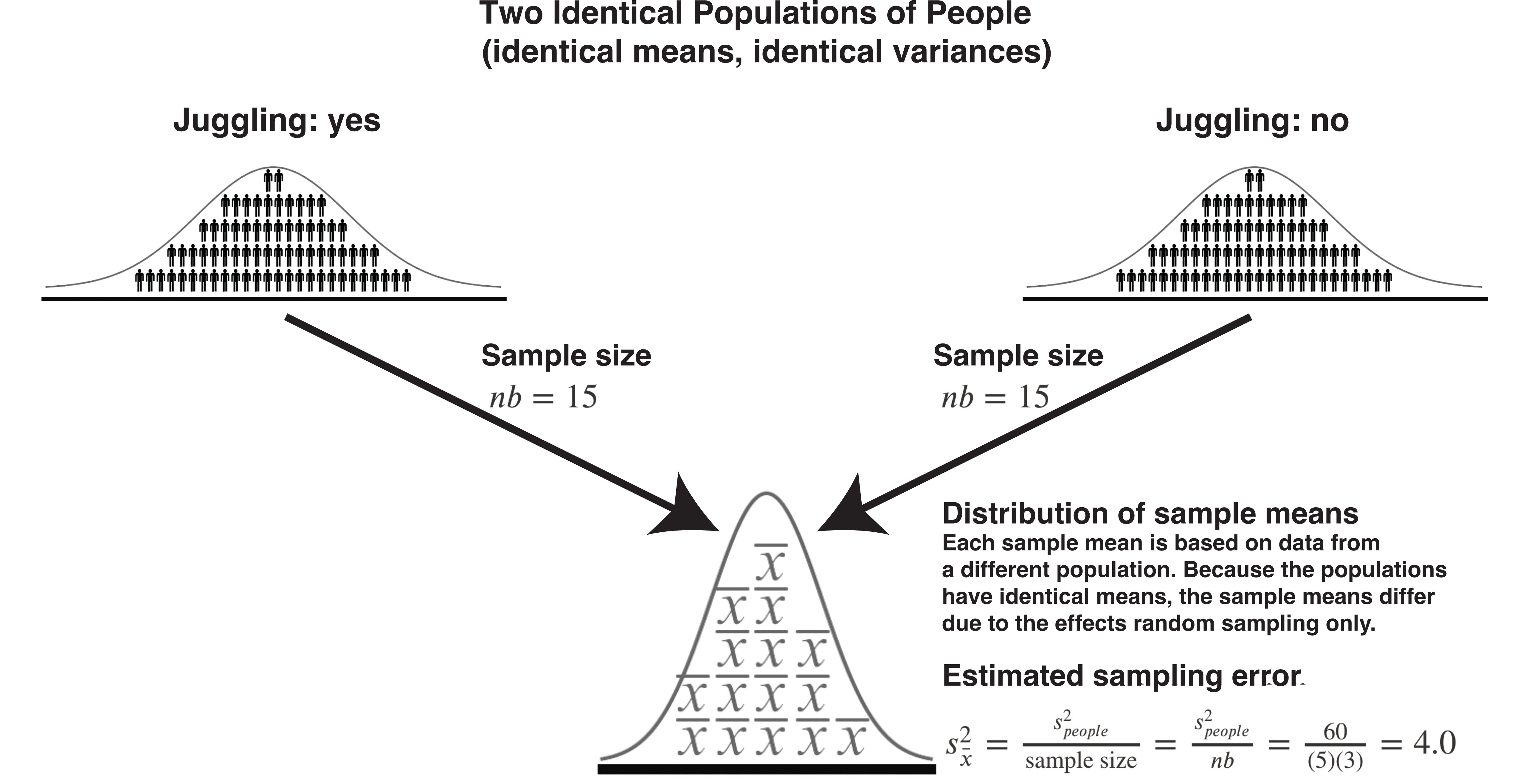
In the context of the juggling main effect means, each juggle mean is based on \(nb=(5)(3)=15\) people. Therefore, for these juggling main effect means the general formula for the variance due to sampling error is below:
\[ \begin{aligned} \text{Sampling error variance for means for A} &= \sigma_{\bar{x}}^2 \\ &= \frac{\sigma_{people}^2}{\text{sample size}}\\ &= \frac{\sigma_{people}^2}{nb}\\ \end{aligned} \]
We don’t know the population variance (\(\sigma_{people}^2\)) though, but we use an estimate below (\(s_{people}^2\)):
\[ \begin{aligned} \text{Estimated sampling error variance for means for A} &= s_{\bar{x}}^2\\ &= \frac{s_{people}^2}{nb}\\ &= \frac{s_{people}^2}{(5)(3)}\\ &= \frac{60.0}{15}\\ &= 4.0 \end{aligned} \]
Thus, when we have two juggling populations from which we obtained samples of 15 people, we would expect the variance of sample means to be 4.0; assuming the population means are the same.
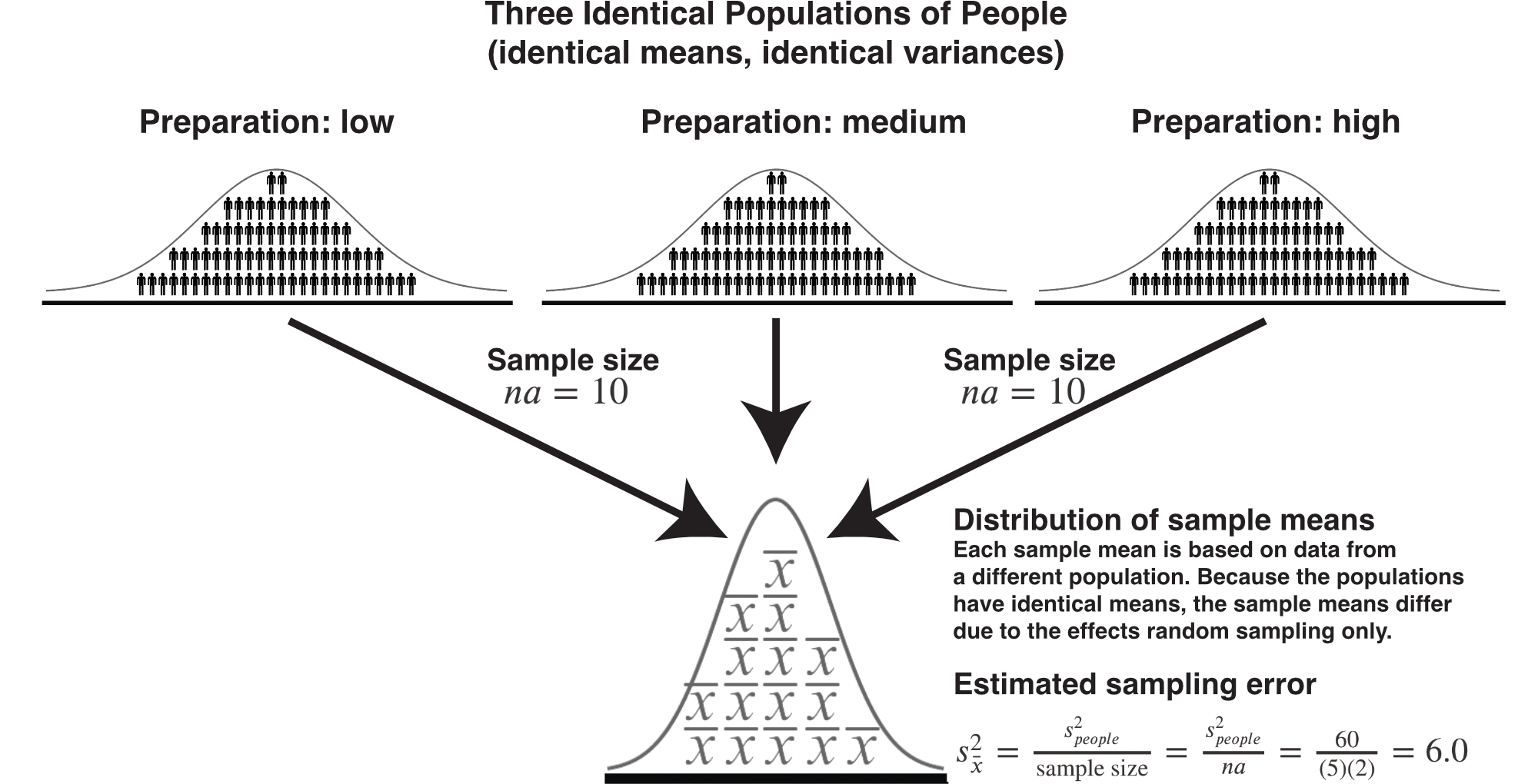
16.11.2 Expected Variance \(B\): Preparation
In the context of the preparation main effect means, each preparation mean is based on \(na=(5)(2)=10\) people. Therefore, for these preparation main effect means the general formula for the variance due to sampling error is below:
\[ \begin{aligned} \text{Sampling error variance for means for B} &= \sigma_{\bar{x}}^2 \\ &= \frac{\sigma_{people}^2}{\text{sample size}}\\ &= \frac{\sigma_{people}^2}{na}\\ \end{aligned} \]
We don’t know the population variance (\(\sigma_{people}^2\)) though, but we use an estimate below (\(s_{people}^2\)):
\[ \begin{aligned} \text{Estimated sampling error variance for means for B} &= s_{\bar{x}}^2\\ &= \frac{s_{people}^2}{na}\\ &= \frac{s_{people}^2}{(5)(2)}\\ &= \frac{60.0}{10}\\ &= 6.0 \end{aligned} \]
Thus, when we have three preparation populations from which we obtained samples of 10 people, we would expect the variance of sample means to be 6.0; assuming the population means are the same.
16.11.3 Expected Variance Cells
In the context of the cell means, each cell mean is based on \(n=5\) people. Therefore, for these cell means the general formula for the variance due to sampling error is below:
\[ \begin{aligned} \text{Sampling error variance for cell means} &= \sigma_{\bar{x}}^2 &= \frac{\sigma_{people}^2}{\text{sample size}}\\ &= \frac{\sigma_{people}^2}{n}\\ \end{aligned} \]
\[ \begin{aligned} \text{Estimated sampling error variance for cell means} &= s_{\bar{x}}^2\\ &= \frac{s_{people}^2}{n}\\ &= \frac{60.0}{5}\\ &= 12.0 \end{aligned} \]
I omit the diagram for cells populations and sample mean distributions. This is done because there are so many different ways cells might be examined. There would be too many diagrams - and it would be misleading to present just one diagram. But don’t worry we will return to this issue, with diagrams, when we start talking about interactions in more detail.
16.11.4 Expected Variance Summary

You can see in the table above that we have estimated the variability we will see in the sample means for different effects. The estimated sampling error differs for each effect because the sample size differs for each effect.
Notice that the degrees of freedom for the sampling error variance is the same for all the effects. This is because the degrees of freedom is based on the \(s_{people}^2\) calculation (i.e., MSE calculation). Sampling error variance is just \(s_{people}^2\) (i.e., MSE) divided by sample size. Consequently, the degrees for freedom for sampling error variance the same as MSE, \(ab(n-1)\).
16.12 Main Effect \(A\): Juggling
16.12.1 Observed Variance \(A\) (total variance)
We might wonder if there is an effect of juggling on calmness scores ignoring the effect of preparation. Said another way, we might wonder if the mean of the yes juggling population (\(\mu_{A1}\)) is different from the mean of the no juggling population (\(\mu_{A2}\)). We examine this question by looking the variance in the population means.
If we knew the population means we could:
- Calculate the grand mean (i.e., \(\mu_A\)). That is, the mean of the two juggling population means. Recall because there are two levels of juggling (i.e., two populations), \(a = 2\). Note that this is the same as the taking the mean of all participants from both populations (assuming equal population sizes).
\[ \begin{aligned} \text{Grand mean} &= \mu_A \\ &= \frac{\sum\mu_{A_i}}{a} \\ &= \frac{\mu_{A_1}+\mu_{A_2}}{2}\\ &= \frac{? + ?}{2} \end{aligned} \]
But, as the question marks clearly illustrate - we don’t know the population means. We don’t have everyone in the population. But if we did have the population means we could proceed as below.
- Use the grand mean to calculate the variance in the means:
\[ \begin{aligned} \sigma_{\mu_A}^2 &= \frac{\sum (\mu_{A_i}-\mu_{\mu_A})^2}{a} \\ &= \frac{(\mu_{A_1} - \mu_{\mu_A})^2 + (\mu_{A_2} - \mu_{\mu_A})^2}{2} \\ &= ?\\ \end{aligned} \]
If the variance of the population means is zero than the populations means are the same. If the variance of the populations means is greater than zero than the population means are different.
Unfortunately, we don’t have access to population-level means. So we need to rely upon sample-level information to estimate the variability in population means. You can check out the sample-level means in the diagram below. As we discussed previously. For the \(A\) independent variable, these means have a sample size of \(15\).
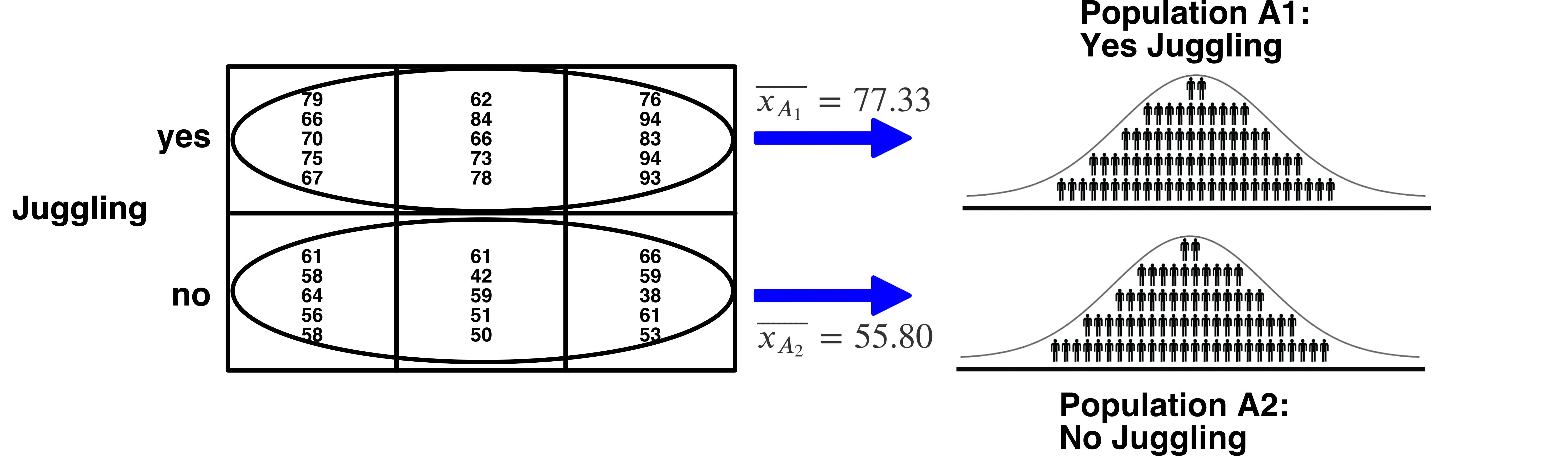
- We ESTIMATE the grand mean using the mean of the sample-level means. We refer to our grand mean estimate using \(\bar{bar{bar}}\). There are two bars about the \(x\) to indicate that it is the mean of means. Note that this “grand mean” of participants is the same as taking the mean of all participants (assuming equal cell sizes).
\[ \begin{aligned} \text{Grand mean estimate} &= \bar{\bar{x}} \\ &= \frac{\sum \overline{x_{A_i}}}{a} \\ &= \frac{\overline{x_{A_1}}+\overline{x_{A_2}}}{2}\\ &= \frac{77.33333 + 55.8}{2} \\ &= 66.56667\\ \end{aligned} \]
- Now estimate the total variance in populations means:
\[ \begin{aligned} s_{\mu_A}^2 &= \frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1} \\ &= \frac{(\overline{x_{A_1}} - \bar{\bar{x}})^2 + (\overline{x_{A_2}} - \bar{\bar{x}})^2}{a-1} \\ &= \frac{(77.33333 - 66.56667)^2 + (55.8 - 66.56667)^2}{2-1} \\ &= 231.8422 \end{aligned} \]
When you estimate the variance is sample means this way (using the total variance formula) the number you obtain will reflect two things:
- Variability in sample means due to random sampling: \(\frac{\sigma_{people}^2}{nb}\)
- Variability in sample means due differences among the population means \(\sigma_{\mu_A}^2\)
In mathematical terms we say the Expected Mean Square is:
\(\text{Expected Mean Square} = \frac{\sigma_{people}^2}{nb} + \sigma_{\mu_A}^2\)
16.12.2 \(F\)-value for \(A\)
Recall that we now have two estimates for the variability in juggling means (total variance estimate, random sampling variance estimate).
In the section immediately above, we obtained a variance \(\frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1}=231.8422\). This value reflects random sampling error variance and the variance of the population mean.
Previously, we obtained a variance of estimate of \(\frac{s_{people}^2}{nb} = 4.0\). This value reflects random sampling variance only.
These two values are summarized in the table below.
| Juggling | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Estimated total variance | \(\frac{\sum(\bar{x_i}-\bar{\bar{x}})^2}{a-1}=231.8422\) | \(\frac{\sigma_{people}^2}{nb} + \sigma_{A}^2\) | \((a-1) = 1\) |
| Estimated variance sampling error | \(\frac{s_{people}^2}{nb} = 4.0\) | \(\frac{\sigma_{people}^2}{nb}\) | \(ab(n-1) = 24\) |
We calculate an \(F\)-value to compare these two values:
\[ \begin{aligned} F &= \frac{\text{estimated total variance}}{\text{estimated variance due to random sampling}} \\ &= \frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}}\\ &= \frac{\frac{\sum (\overline{x_{Ai}}-\bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}}\\ &= \frac{\frac{(\overline{x_{A_1}} - \bar{\bar{x}})^2 + (\overline{x_{A_2}} - \bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}}\\ &=\frac{\frac{(77.33333 - 66.56667)^2 + (55.8 - 66.56667)^2}{2-1}}{\frac{60}{(5)(3)}}\\ &=\frac{231.8422}{\frac{60}{(5)(3)}}\\ &=\frac{231.8422}{\frac{60}{15}}\\ &=\frac{231.8422}{4}\\ &= 57.96\\ \end{aligned} \]
16.12.3 \(p\)-value for \(A\)
This sample \(F\)-value tells us that, with these data, the estimated total variance of juggling means is 57.96 times larger than than we would estimate due to random sampling alone. This sounds like a large number - but it may not be. Notice the use of word estimate(d) in the previous sentences. We are looking at estimates that themselves may vary due to random sampling error. So we need to know how likely this is, when the population means are equal, in the context of the number of populations and the sample sizes. Recall Central \(F\)-distributions from a previous chapter.
To interpret an \(F\)-value for the main effect of \(A\), you need to think about all the \(F\)-values that could have occurred - when the population means are equal (i.e., \(\sigma_{A}^2=0\)). More specifically, we have to imagine all of the \(F\)-values with 1 and 24 degrees of freedom in the Central \(F\)-distribution. This distribution is illustrated below. It reflects, for this main effect, all the \(F\)-values that could occur when the populations means are equal - due to the fact we are using random samples.
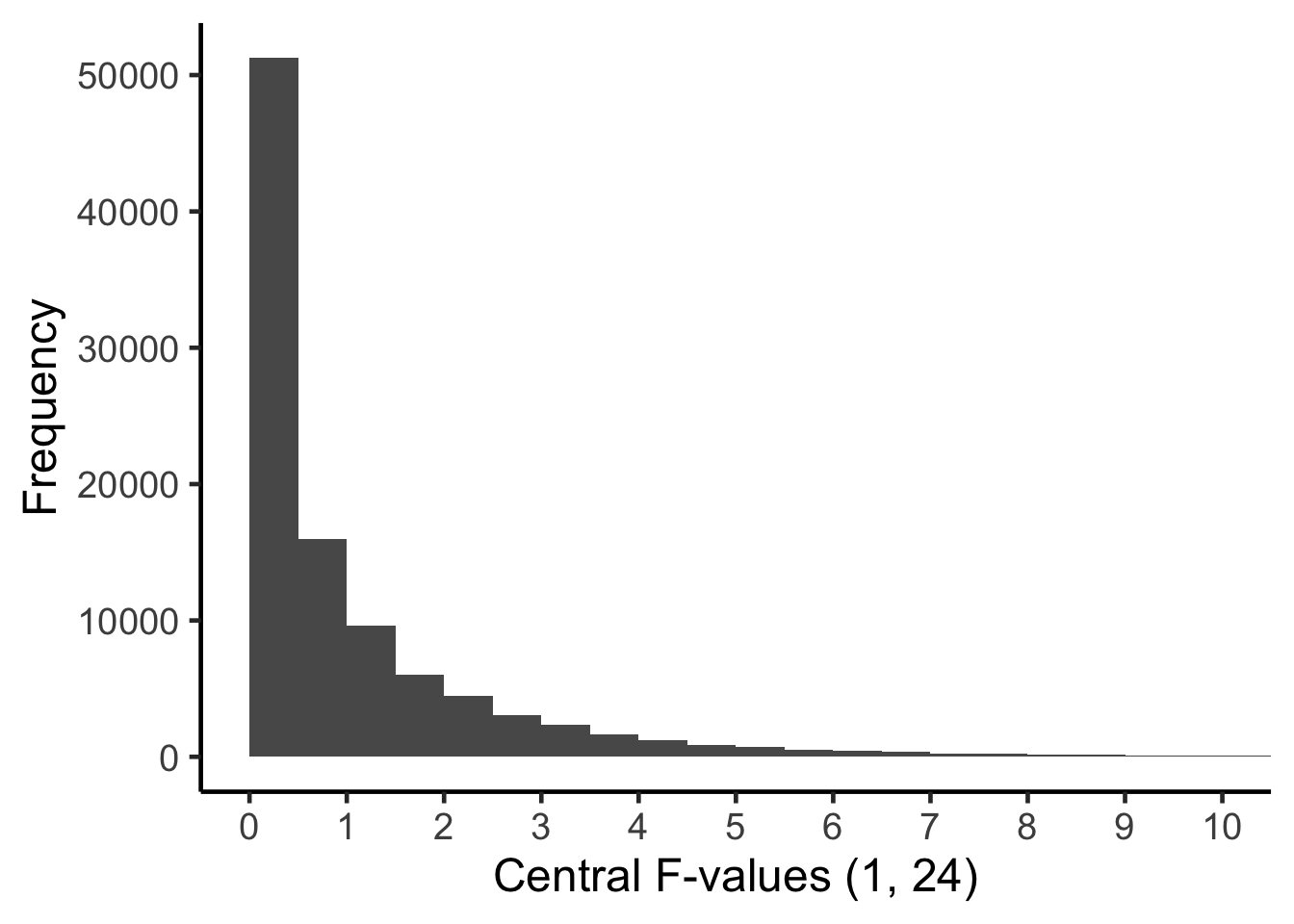
To assign a \(p\)-value to the \(F\)-value that we obtained, \(F = 57.96\) we determine the proportion of the Central \(F\)-distribution (with 1 and 24 degrees of freedom) that is equal to, or more extreme, than the \(F\)-value we obtained in our study. If you inspect the Central \(F\)-distribution above you can see that the current \(F\)-value of 57.96 doesn’t even fit on the graph - because the x-axis only goes to 10. We need a new graph with a wider range of values on the x-axis. This graph is presented below:
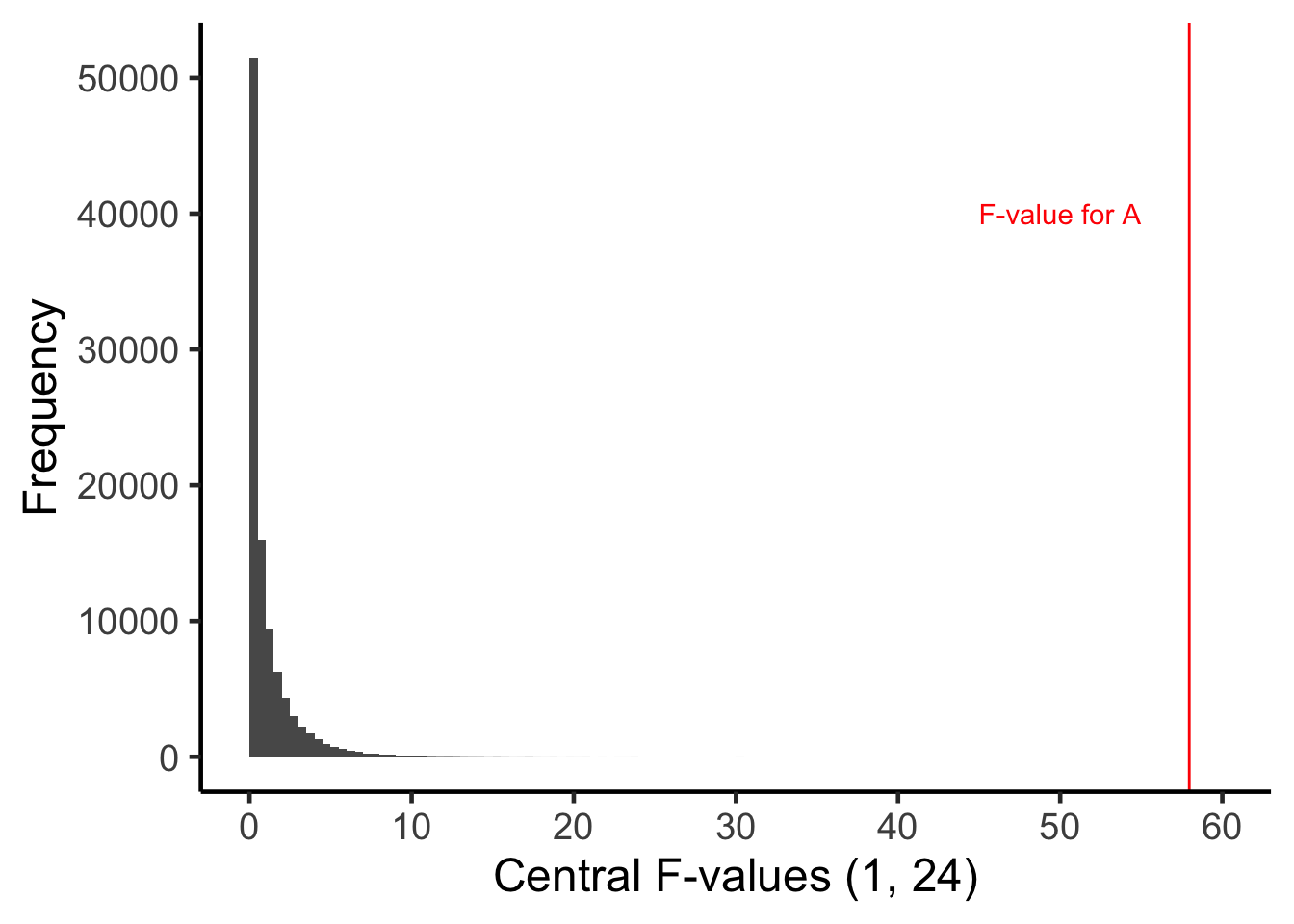
In this graph you can see the \(F\)-value we obtained (57.96) is completely to the right of Central \(F\)-distribution. In fact, the proportion of the \(F\)-distribution that is equal to, or more extreme, than 57.96 is < .001. So we say the \(p\)-value is \(p < .001\).
Consequently, under the assumption of equal population means, our data (or more extreme data) is very unlikely (\(p < .001\)). Therefore, we reject the assumption that the population means (i.e., the population means for yes and no juggling) are equal. We conclude those population means may be different.
To assign a \(p\)-value to the \(F\)-value that we obtained, \(F = 57.96\) we determine the proportion of the Central \(F\)-distribution (with 1 and 24 degrees of freedom) that is equal to, or more extreme, than the \(F\)-value we obtained in our study. If you inspect the Central \(F\)-distribution above you can see that the current \(F\)-value of 57.96 doesn’t even fit on the graph - because the x-axis only goes to 10. We need a new graph with a wider range of values on the x-axis. This graph is presented below:
Remember the \(p\)-value is the probability of our data, or more extreme data, assuming the null hypothesis is true.
WARNING: A small \(p\)-value (\(p<.001\)) does NOT indicate that an effect is a large effect. If you want to know the size of the effect you need to look at an effect size (e.g., partial \(\eta^2\) or partial \(\omega^2\).)
16.12.4 \(A\) conceptual recap (juggling)
A recap of the conceptual basis for the calculations we’ve done for juggling is provided below. In the next section we map these conceptual calculations onto the typical way ANOVA information is presented – which obscures the conceptual meaning.
| Juggling | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Estimated total variance | \(\frac{\sum(\bar{x_i}-\bar{\bar{x}})^2}{a-1}=231.8422\) | \(\frac{\sigma_{people}^2}{nb} + \sigma_{A}^2\) | \((a-1) = 1\) |
| Estimated variance sampling error | \(\frac{s_{people}^2}{nb}=\frac{60}{15} = 4.0\) | \(\frac{\sigma_{people}^2}{nb}\) | \(ab(n-1) = 24\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{a-1}}{ \frac{s_{people}^2}{nb}}= \frac{231.8422}{4.0}= 57.96\) | \(\frac{\frac{\sigma_{people}^2}{nb} + \sigma_{A}^2}{ \frac{\sigma_{people}^2}{nb}}\) | \([(a-1),ab(n-1)]=[1,24]\) |
16.12.5 \(A\) typical (juggling)
The conceptual formula are algebraically rearranged in typical ANOVA output - due to the fact in the “old days” it made hand calculations somewhat easier. This typical rearrangement obscures the conceptual meaning of the calculations though. But it is relatively simply algebra (see below). Note, the \(F\)-value does not change.
\[ \begin{aligned} F &= \frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}}\\ &= \frac{\frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}} \times 1\\ &= \frac{\frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1}}{\frac{s_{people}^2}{nb}} \times \frac{nb}{nb}\\ &= \frac{nb\frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1}}{s_{people}^2}\\ &= \frac{(5)(3)(231.8422)}{60}\\ &= \frac{(15)(231.8422)}{60}\\ &= \frac{3477.633}{60}\\ &= 57.96\\ \end{aligned} \]
From this rearrangement we use the labels below. Notice the inclusion of \(nb\) in the \(MS_{juggling}\) this is hard to explain unless you first understood the conceptual version of the equations above. Indeed, people who tend to explain ANOVA using a “between vs within” explanation usually need to skip over or “brush away” the \(nb\) term in their explanations.
\(MS_{juggling} = nb\frac{\sum (\overline{x_{A_i}}-\bar{\bar{x}})^2}{a-1} = 3477.633\)
and
\(MSE = s_{people}^2 = 60.0\)

Summarized below:
| Juggling | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Sample size multiplied by estimated total variance (i.e., \(MS_{juggling}\)) | \(\frac{nb\sum(\bar{x_i}-\bar{\bar{x}})^2}{a-1}=3477.633\) | \(\sigma_{people}^2 + nb \sigma_{A}^2\) | \((a-1)\) |
| Estimated population variance (i.e., \(MSE\)) | \(s_{people}^2=60.0\) | \(\sigma_{people}^2\) | \(ab(n-1)\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{nb\sum(\bar{x_i}-\bar{\bar{x}})^2}{a-1}}{s_{people}^2}=\frac{3477.633}{60}=57.96\) | \(\frac{\sigma_{people}^2 + nb \sigma_{A}^2}{\sigma_{people}^2}\) | \([(a-1),ab(n-1)]\) |
16.13 Main Effect \(B\): Preparation
16.13.1 Observed Variance \(B\) [total variance]
Let’s look at the other independent variable: preparation. As before, we might wonder if there is an effect of preparation on calmness scores ignoring the effect of juggling. Said another way, we might wonder if the means of the three preparation populations (low [\(\mu_{B1}\)], medium [\(\mu_{B2}\)], high [\(\mu_{B3}\)]) are different from each other. We examine this question by looking the variance in the population means.
If we knew the population means we could:
- Calculate the grand mean (i.e., \(\mu_B\)). That is, the mean of the three preparation population means. Recall because there are three levels of preparation (i.e., three populations), \(b = 3\). Note that this is the same as the taking the mean of all participants from the three populations (assuming equal population sizes).
\[ \begin{aligned} \text{Grand mean} &= \mu_B \\ &= \frac{\sum\mu_{B_i}}{b} \\ &= \frac{\mu_{B_1}+\mu_{B_2}+\mu_{B_3}}{3}\\ &= \frac{? + ? + ?}{3} \end{aligned} \]
But, as the question marks clearly illustrate - we don’t know the population means. We don’t have everyone in the population. But if we did have the population means we could proceed as below.
- Use the grand mean to calculate the variance in the means:
\[ \begin{aligned} \sigma_{\mu_B}^2 &= \frac{\sum (\mu_{B_i}-\mu_{\mu_B})^2}{b} \\ &= \frac{(\mu_{B_1} - \mu_{\mu_B})^2 + (\mu_{B_2} - \mu_{\mu_B})^2 (\mu_{B_3} - \mu_{\mu_B})^2}{3} \\ &= ?\\ \end{aligned} \]
If the variance of the population means is zero than the populations means are the same. If the variance of the populations means is greater than zero than the population means are different.
Unfortunately, we don’t have access to population-level means. So we need to rely upon sample-level information to estimate the variability in population means. You can check out the sample-level means in the diagram below. As we discussed previously. For the \(B\) independent variable, these means have a sample size of \(10\).
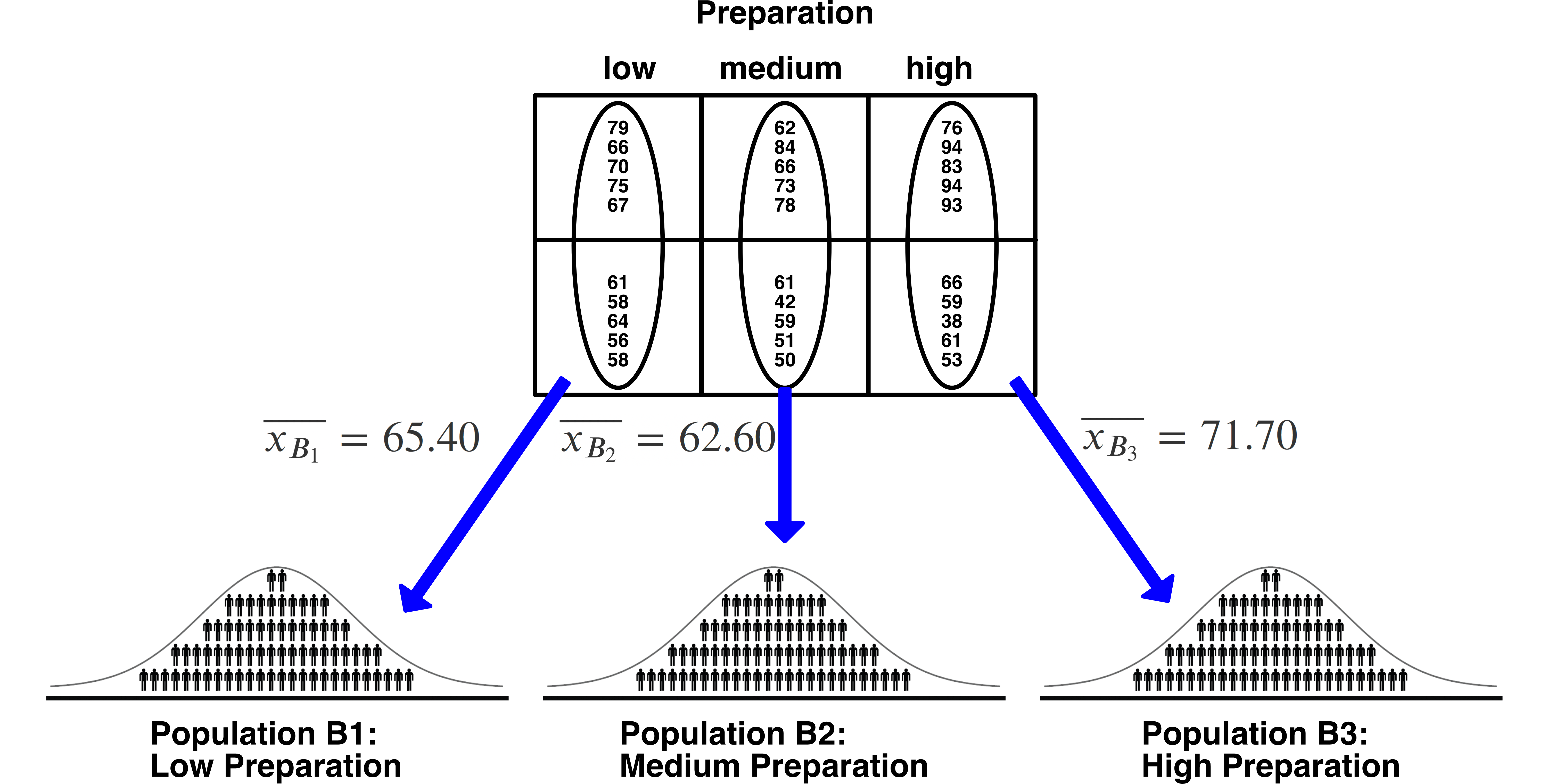
- We ESTIMATE the grand mean using the mean of the sample-level means. We refer to our grand mean estimate using \(\bar{bar{bar}}\). There are two bars about the \(x\) to indicate that it is the mean of means. Note that this “grand mean” of participants is the same as taking the mean of all participants (assuming equal cell sizes).
\[ \begin{aligned} \text{Grand mean estimate} &= \bar{\bar{x}} \\ &= \frac{\sum \bar{x}_{B_i}}{b} \\ &= \frac{\overline{x_{B_1}}+\overline{x_{B_2}} +\overline{x_{B_3}} }{3}\\ &= \frac{65.4 + 62.6 + 71.7}{3} \\ &= 66.56667\\ \end{aligned} \]
- Now estimate the total variance in populations means:
\[ \begin{aligned} s_{\mu_B}^2 &= \frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1} \\ &= \frac{(\overline{x_{B_1}} - \bar{\bar{x}})^2 + (\overline{x_{B_2}} - \bar{\bar{x}})^2+ (\overline{x_{B_3}} - \bar{\bar{x}})^2}{b-1} \\ &= \frac{(65.4 - 66.56667)^2 + (62.6 - 66.56667)^2 + (71.7 - 66.56667)^2}{3-1} \\ &= 21.72333 \end{aligned} \]
When you estimate the variance is sample means this way (using the total variance formula) the number you obtain will reflect two things:
- Variability in sample means due to random sampling: \(\frac{\sigma_{people}^2}{na}\)
- Variability in sample means due differences among the population means \(\sigma_{\mu_B}^2\)
In mathematical terms we say the Expected Mean Square is:
\(\text{Expected Mean Square} = \frac{\sigma_{people}^2}{na} + \sigma_{\mu_B}^2\)
16.13.2 \(F\)-value for \(B\)
Recall that we now have two estimates for the variability in juggling means (total variance estimate, random sampling variance estimate).
In the section immediately above, we obtained a variance \(\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1}=21.72333\). This value reflects random sampling error variance and the variance of the population mean.
Previously, we obtained a variance of estimate of \(\frac{s_{people}^2}{na} = 6.0\). This value reflects random sampling variance only.
These two values are summarized in the table below.
| Juggling | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Estimated total variance | \(\frac{\sum(\bar{x_i}-\bar{\bar{x}})^2}{b-1}=21.72333\) | \(\frac{\sigma_{people}^2}{na} + \sigma_{B}^2\) | \((b-1) = 2\) |
| Estimated variance sampling error | \(\frac{s_{people}^2}{na} = 6.0\) | \(\frac{\sigma_{people}^2}{na}\) | \(ab(n-1) = 24\) |
We calculate an \(F\)-value to compare these two values:
\[ \begin{aligned} F &= \frac{\text{estimated total variance}}{\text{estimated variance due to random sampling}} \\ &= \frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}}\\ &= \frac{\frac{\sum (\overline{x_{Bi}}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}}\\ &= \frac{\frac{(\overline{x_{B_1}} - \bar{\bar{x}})^2 + (\overline{x_{B_2}} - \bar{\bar{x}})^2 + (\overline{x_{B_3}} - \bar{\bar{x}})^2 }{b-1}}{\frac{s_{people}^2}{na}}\\ &=\frac{\frac{(65.4 - 66.56667)^2 + (62.6 - 66.56667)^2 + (71.7 - 66.56667)^2}{3-1}}{\frac{60}{(5)(2)}}\\ &=\frac{21.72333}{\frac{60}{(5)(2)}}\\ &=\frac{21.72333}{\frac{60}{10}}\\ &=\frac{21.72333}{6}\\ &= 3.62\\ \end{aligned} \]
16.13.3 \(p\)-value for \(B\)
This sample \(F\)-value tells us that, with these data, the estimated total variance of juggling means is 3.62 times larger than than we would estimate due to random sampling alone. Is this large or small? It’s hard to tell. As well, notice the use of word estimate(d) in the previous sentences. We are looking at estimates that themselves may vary due to random sampling error. So we need to know how likely this is, when the population means are equal, in the context of the number of populations and the sample sizes. Recall Central \(F\)-distributions from a previous chapter.
To interpret an \(F\)-value for the main effect of \(B\), you need to think about all the \(F\)-values that could have occurred - when the population means are equal (i.e., \(\sigma_{B}^2=0\)). More specifically, we have to imagine all of the \(F\)-values with 2 and 24 degrees of freedom in the Central \(F\)-distribution. This distribution is illustrated below. It reflects, for this main effect, all the \(F\)-values that could occur when the populations means are equal - due to the fact we are using random samples.
To assign a \(p\)-value to the \(F\)-value that we obtained, \(F = 3.62\) we determine the proportion of the Central \(F\)-distribution (with 2 and 24 degrees of freedom) that is equal to, or more extreme, than the \(F\)-value we obtained in our study. The \(F\)-value we obtained is position in Central \(F\)-distribution below.
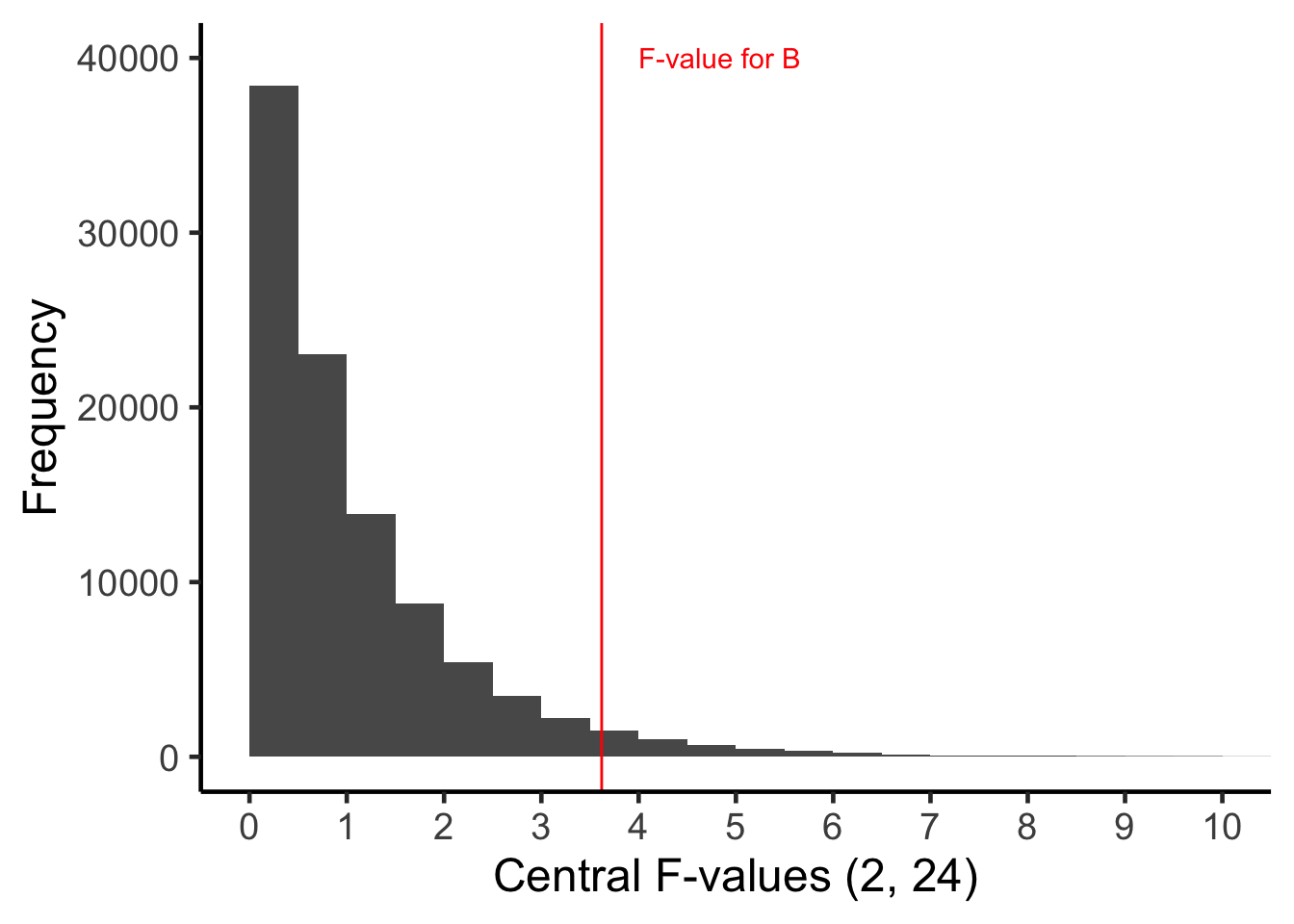
In the graph above you can see the \(F\)-value we obtained (3.62) is somewhat to the right side of the Central \(F\)-distribution. In fact, the proportion of the \(F\)-distribution that is equal to, or more extreme, than 3.62 is .042 (i.e. 4.2%). So we say the \(p\)-value is \(p = .042\).
Consequently, under the assumption of equal population means, our data (or more extreme data) is very unlikely (\(p = .042\)). Therefore, we reject the assumption that the population means (i.e., the population means for low, medium, and high preparation) are equal. We conclude those population means may be different.
Remember the \(p\)-value is the probability of our data, or more extreme data, assuming the null hypothesis is true.
16.13.4 \(B\) conceptual recap (preparation)
A recap of the conceptual basis for the calculations we’ve done for preparation is provided below. In the next section we map these conceptual calculations onto the typical way ANOVA information is presented – which obscures the conceptual meaning.
| Preparation | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Estimated total variance | \(\frac{\sum(\bar{x_i}-\bar{\bar{x}})^2}{b-1}=21.72333\) | \(\frac{\sigma_{people}^2}{na} + \sigma_{B}^2\) | \((b-1)\) |
| Estimated variance sampling error | \(\frac{s_{people}^2}{na}= \frac{60}{10}=6.0\) | \(\frac{\sigma_{people}^2}{na}\) | \(ab(n-1)\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{b-1}}{ \frac{s_{people}^2}{na}} = \frac{21.72333}{6.0}=3.62\) | \(\frac{\frac{\sigma_{people}^2}{na} + \sigma_{B}^2}{ \frac{\sigma_{people}^2}{na}}\) | \([(b-1),ab(n-1)\) |
16.13.5 \(B\) typical (preparation)
The conceptual formula are algebraically rearranged in typical ANOVA output - due to the fact in the “old days” it made hand calculations somewhat easier. This typical rearrangement obscures the conceptual meaning of the calculations though. But it is relatively simply algebra (see below). Note, the \(F\)-value does not change.
\[ \begin{aligned} F &= \frac{\frac{\sum (\bar{x_i}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}}\\ &= \frac{\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}}\\ &= \frac{\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}} \times 1\\ &= \frac{\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1}}{\frac{s_{people}^2}{na}} \times \frac{na}{na}\\ &= \frac{na\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1}}{s_{people}^2}\\ &= \frac{(5)(2)(21.72333)}{60}\\ &= \frac{(10)(21.72333)}{60}\\ &= \frac{217.2333}{60}\\ &= 3.62\\ \end{aligned} \]
From this rearrangement we use the labels below. Notice the inclusion of \(na\) in the \(MS_{preparation}\) this is hard to explain unless you first understood the conceptual version of the equations above. Indeed, people who tend to explain ANOVA using a “between vs within” explanation usually need to skip over or “brush away” the \(na\) term in their explanations.
\(MS_{preparation} = na\frac{\sum (\overline{x_{B_i}}-\bar{\bar{x}})^2}{b-1} = 217.2333\)
and
\(MSE = s_{people}^2 = 60.0\)

Summarized below:
| Preparation | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Sample size multiplied by estimated total variance (i.e., \(MS_{preparation}\)) | \(\frac{na\sum(\bar{x_i}-\bar{\bar{x}})^2}{b-1}= 217.2333\) | \(\sigma_{people}^2 + na \sigma_{B}^2\) | \((b-1)\) |
| Estimated population variance (i.e., \(MSE\)) | \(s_{people}^2=60.0\) | \(\sigma_{people}^2\) | \(ab(n-1)\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{na\sum(\bar{x_i}-\bar{\bar{x}})^2}{b-1}}{s_{people}^2} = \frac{217.2333}{60}=3.62\) | \(\frac{\sigma_{people}^2 + na \sigma_{B}^2}{\sigma_{people}^2}\) | \([(b-1),ab(n-1)]\) |
16.14 Interaction Preparation
Interaction calculations are similar to main effect calculations. However, there is a substantial amount of work we need to do before being able to do those calculations. When we say two variable interact to predict the dependent variable we are saying there is more going on than the two main effects. So when we seek to determine if there is an interaction we work with residual cell means. That is, cell means were the main effects have been removed. That’s the work we need to do before proceeding with the calculations used above. In the section below we create the residual means. In the subsequent section we return to the familiar calculations we used for main effects.
16.14.1 Obtaining residualized means
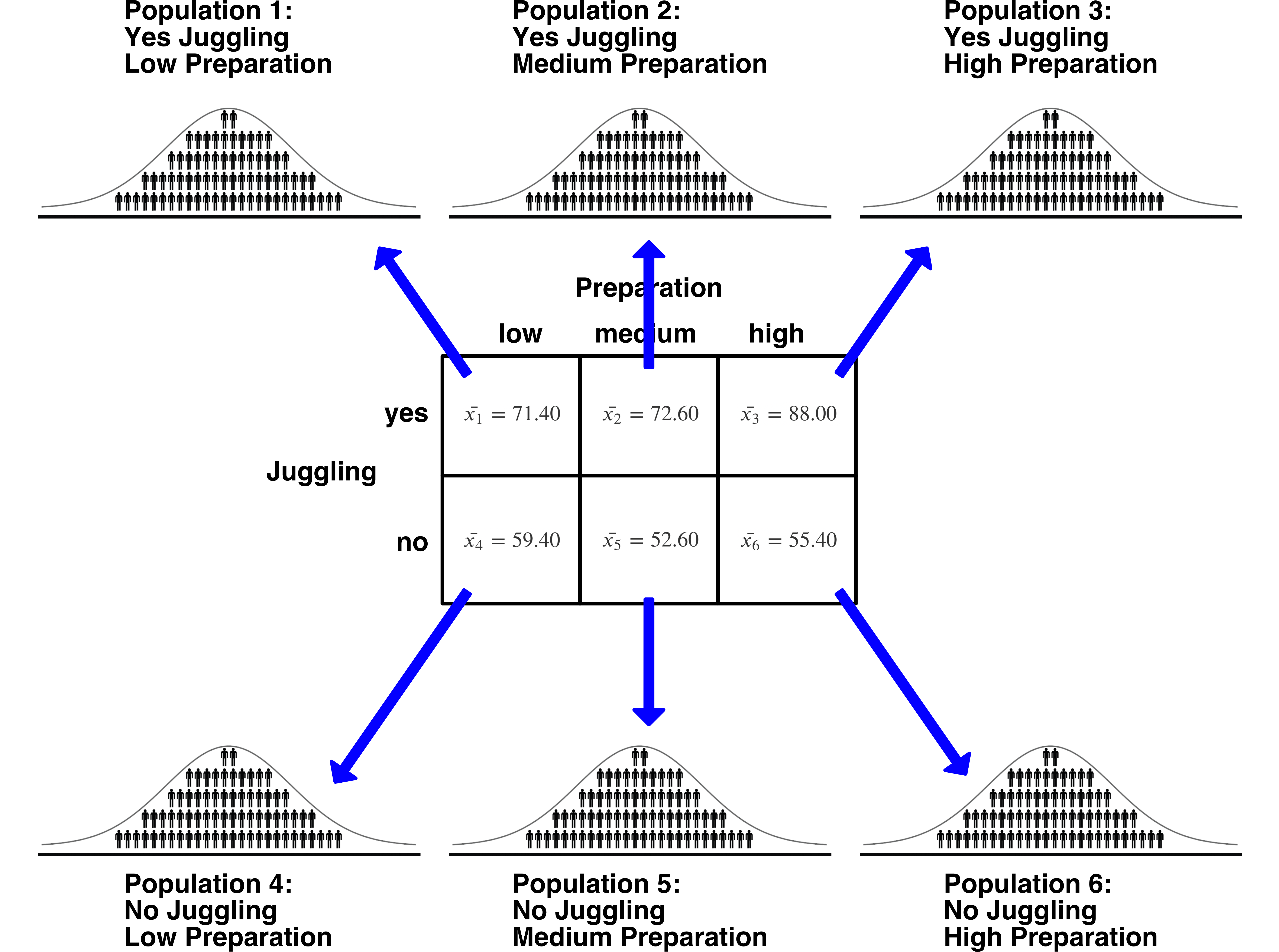
We begin with the cell means:
16.14.1.1 Subtract \(A\) marginal means
The cell means are illustrated below. Recall the overall marginal mean for yes_juggling is 77.33 and the overall marginal mean for no_juggling is 55.8. Be begin by removing these main effect means for \(A\) from the marginal means.
| Effect | low_prep | medium_prep | high_prep |
|---|---|---|---|
| yes_juggle | \(71.4 - 77.33 = -5.93\) | \(72.6 - 77.33 = -4.73\) | \(88 - 77.33 = 10.67\) |
| no_juggle | \(59.4 - 55.8 = 3.6\) | \(52.6 - 55.8 = -3.2\) | \(55.4 - 55.8 = -0.4\) |
16.14.1.2 Subtract \(B\) marginal means
Next, we take the residual. means from the previous step and remove the main effect of \(B\). Recall the marginal means for low, medium, and high preparation were 65.4, 62.6, and 71.7, respectively. We subtract these main effect means from the residual. means from the previous step.
| Effect | low_prep | medium_prep | high_prep |
|---|---|---|---|
| yes_juggle | \(-5.93 - 65.4 = -71.33\) | \(-4.73 - 62.6 = -67.33\) | \(10.67 - 71.7 = -61.03\) |
| no_juggle | \(3.6 - 65.4 = -61.8\) | \(-3.2 - 62.6 = -65.8\) | \(-0.4 - 71.7 = -72.1\) |
16.14.1.3 Add grand mean
In the previous steps, we removed the main effect means for \(A\) and then we removed the main effect means for \(B\). In effect, though each time we did this we removed the “grand mean” twice. We only want to remove the grand mean once though - because this makes so later calculations easier. So now we add the grand mean back in:
| Effect | low_prep | medium_prep | high_prep |
|---|---|---|---|
| yes_juggle | \(-71.33 + 66.57 = -4.77\) | \(-67.33 + 66.57 = -0.77\) | \(-61.03 + 66.57 = 5.53\) |
| no_juggle | \(-61.8 + 66.57 = 4.77\) | \(-65.8 + 66.57 = 0.77\) | \(-72.1 + 66.57 = -5.53\) |
16.15 Interaction (\(AB\))
16.15.1 Observed Variance \(AB\) [total variance]
The residual cell means calculated in the previous section are presented below – as a starting point for the interaction calculations.
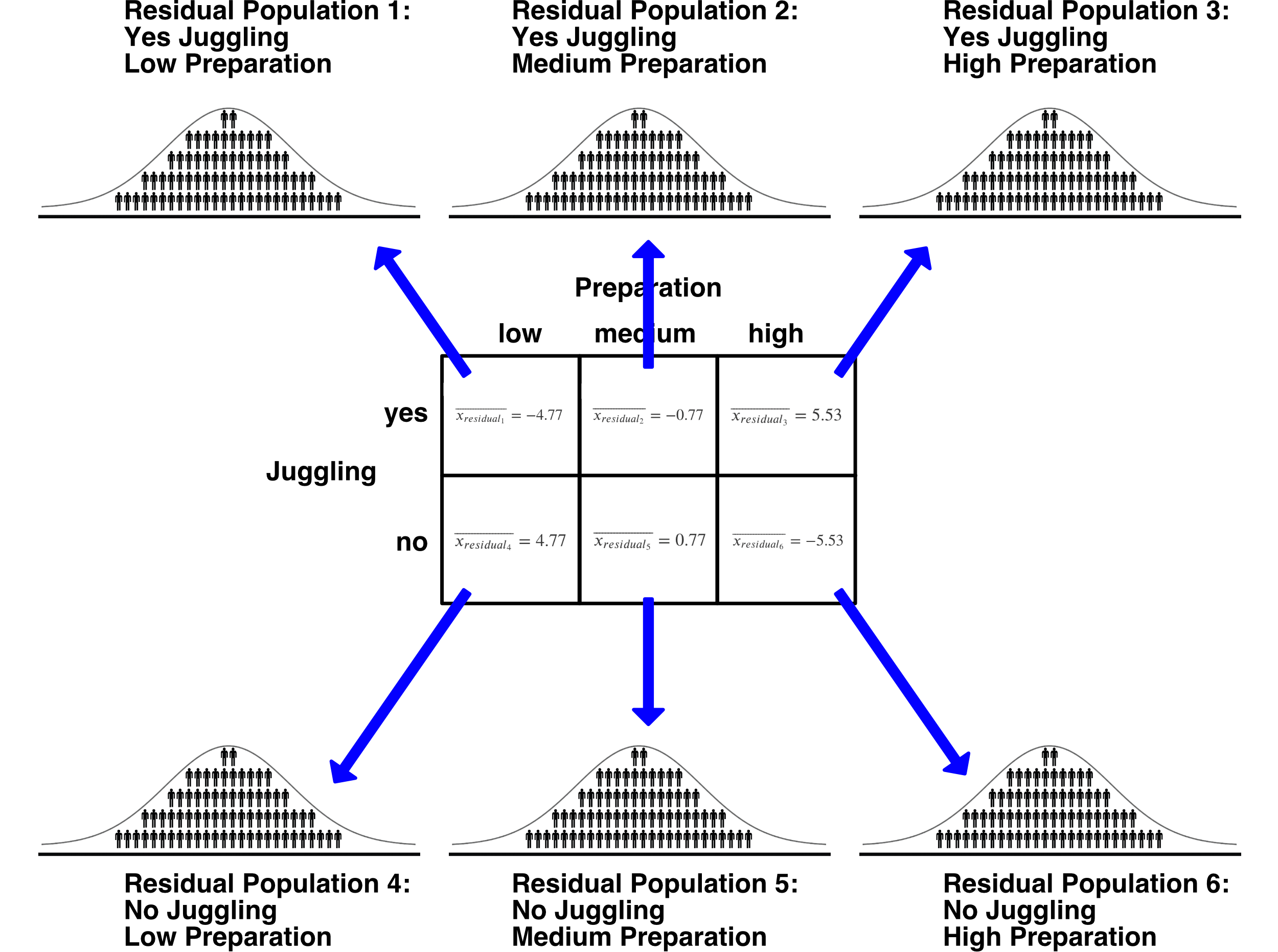
It’s important to remember that the above table of residual cell means is a table of sample-level residual means. That means, the values in the cells are influenced by both the population means (for the cell and the main effects) as well as sampling error.
Consider two situations, at the population-level, where: 1) There is no interaction, only main effects 2) There is an interaction
Imagine the population-level scenario where there is no interaction and only main effects. In this scenario, the values in the population-level cells are entirely the result of the main effects. Further imagine that we we subtracted out the main effects – and created population-level residual means (as we did above, but at the population-level). In this scenario, the population-level residual cells means would all have a value of exactly zero. That value is zero, because the only thing influence scores is the main effects and when the main effects are removed there’s nothing left.
Now consider the population-level scenario where there is an interaction. In this case, when we create residual population-level cell means, they would not all be equal to zero. That’s because there is more going on than the main effects.
The interpretation challenge occurs when we move to the sample level because the sample-level residuals may differ, due to random sampling, from the population-residuals. To help distinguish between these two situations we calculate a \(p\)-value. The \(p\)-value tells us how likely we are to have sample-level cell means this large (or larger) if the population-level residual cell means are zero.
16.15.1.1 Degrees of freedom for \(AB\) total variance
Recall how we calculated the total number of cells. There were two levels of juggling so \(a = 2\). There were three levels of preparation so \(b = 3\).
\(\text{Total number of cells} = ab = (2)(3) = 6\)
We use the same logic when determining the degrees of freedom for the interaction. The degrees of freedom for juggling is \(a-1\) where as the degrees of freedom for preparation are \(b-1\). We use the same general approach to the total degrees of freedom:
\(\text{Degrees of freedom for total variance} = (a-1)(b-1)=(2-1)(3-1)=(1)(2)=2\)
We use this degrees of freedom in the total variance formula. This is the same total variance formula we’ve used before but adjusted to use the residual cell means.
\[ s_{residual}^2 = \frac{\sum (\overline{x_{residual_i}} - \overline{\overline{x_{residual}}})^2}{(a-1)(b-1)} \]
We apply the formula above the means in the residual mean table. These are the cell means with the main effects removed. The estimated population variance is:
\[ \begin{aligned} s_{residual}^2 &= \frac{\sum (\overline{x_{residual_i}} - \overline{\overline{x_{residual}}})^2}{(a-1)(b-1)}\\ &= \frac{(-4.77 - 0)^2 + (-0.77 - 0)^2 + (5.53 - 0)^2 + (4.77 - 0)^2 + (0.77 - 0)^2 + (-5.53 - 0)^2}{(2-1)(3-1)} \\ &= \frac{(-4.77)^2 + (-0.77)^2 + (5.53)^2 + (4.77)^2 + (0.77)^2 + (-5.53)^2}{(2-1)(3-1)} \\ &= \frac{107.85}{2} &= 53.92667 \end{aligned} \]
Each residual mean is based on \(n=5\). Therefore, the estimated variance due to sampling error is:
\[ \frac{s_{people}^2}{n} \]
16.15.2 \(F\)-value for \(AB\)
So F-ratio comparing these two estimates is:
\[ \begin{aligned} F &= \frac{\text{estimated total variance}}{\text{estimated variance due to random sampling}} \\ &= \frac{\frac{\sum (\overline{x_{residual_i}} - \overline{\overline{x_{residual}}})^2}{(a-1)(b-1)}}{\frac{s_{people}^2}{n}}\\ &= \frac{53.92667}{\frac{60}{5}}\\ &= 4.49\\ \end{aligned} \]
16.15.3 \(p\)-value for \(AB\)
This sample \(F\)-value tells us that, with these data, the estimated total variance of juggling means is 4.49 times larger than than we would estimate due to random sampling alone. Is this large or small? It’s hard to tell. As well, notice the use of word estimate(d) in the previous sentences. We are looking at estimates that themselves may vary due to random sampling error. So we need to know how likely this is, when the population means are equal, in the context of the number of populations and the sample sizes. Recall Central \(F\)-distributions from a previous chapter.
To interpret an \(F\)-value for the main effect of \(AB\), you need to think about all the \(F\)-values that could have occurred - when the population means are equal (i.e., \(\sigma_{AB}^2=0\)). More specifically, we have to imagine all of the \(F\)-values with 2 and 24 degrees of freedom in the Central \(F\)-distribution. This distribution is illustrated below:
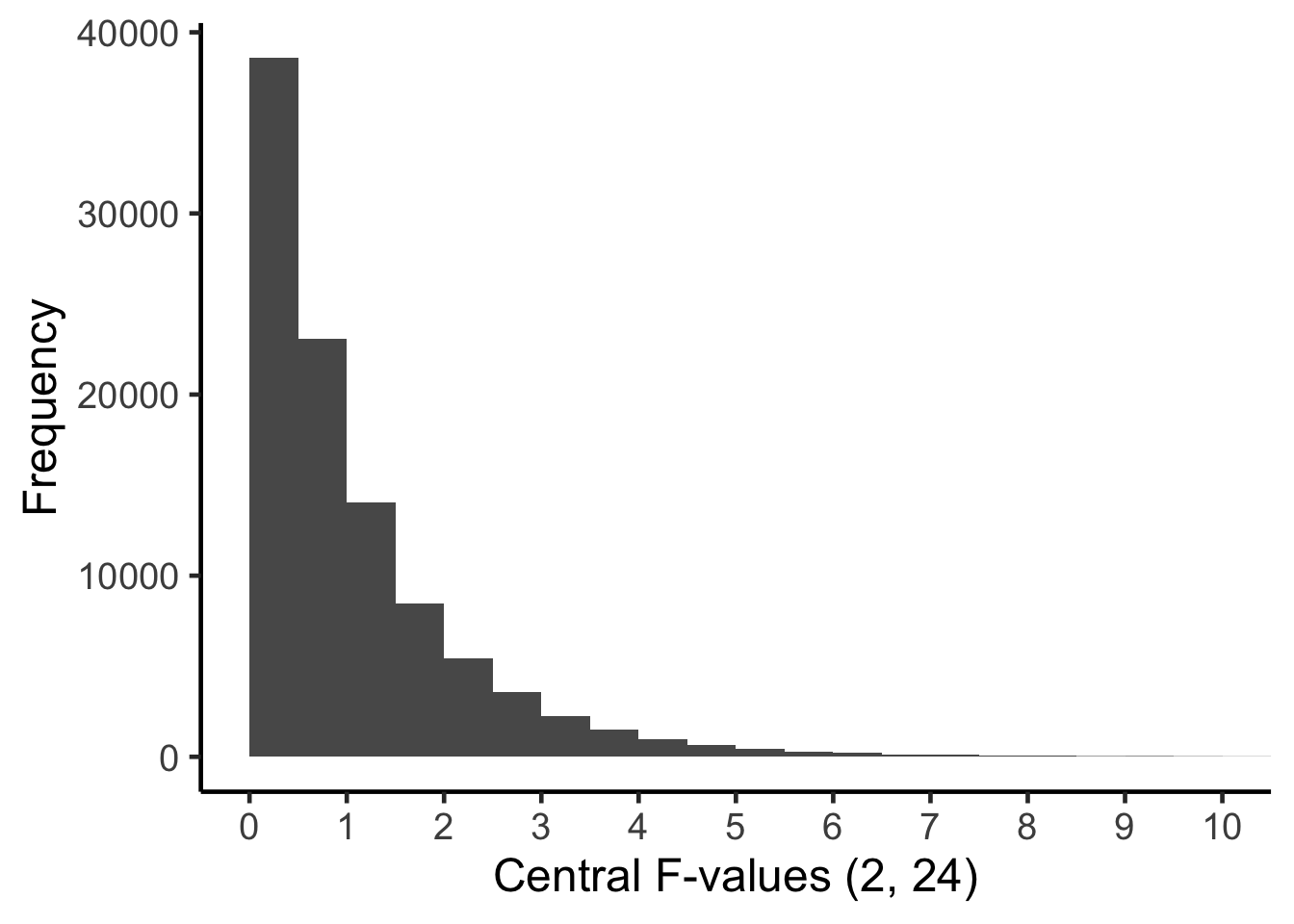
To assign a \(p\)-value to the \(F\)-value that we obtained, \(F = 4.49\) we determine the proportion of the Central \(F\)-distribution (with 2 and 24 degrees of freedom) that is equal to, or more extreme, than the \(F\)-value we obtained in our study. The \(F\)-value we obtained is positioned in Central \(F\)-distribution below.
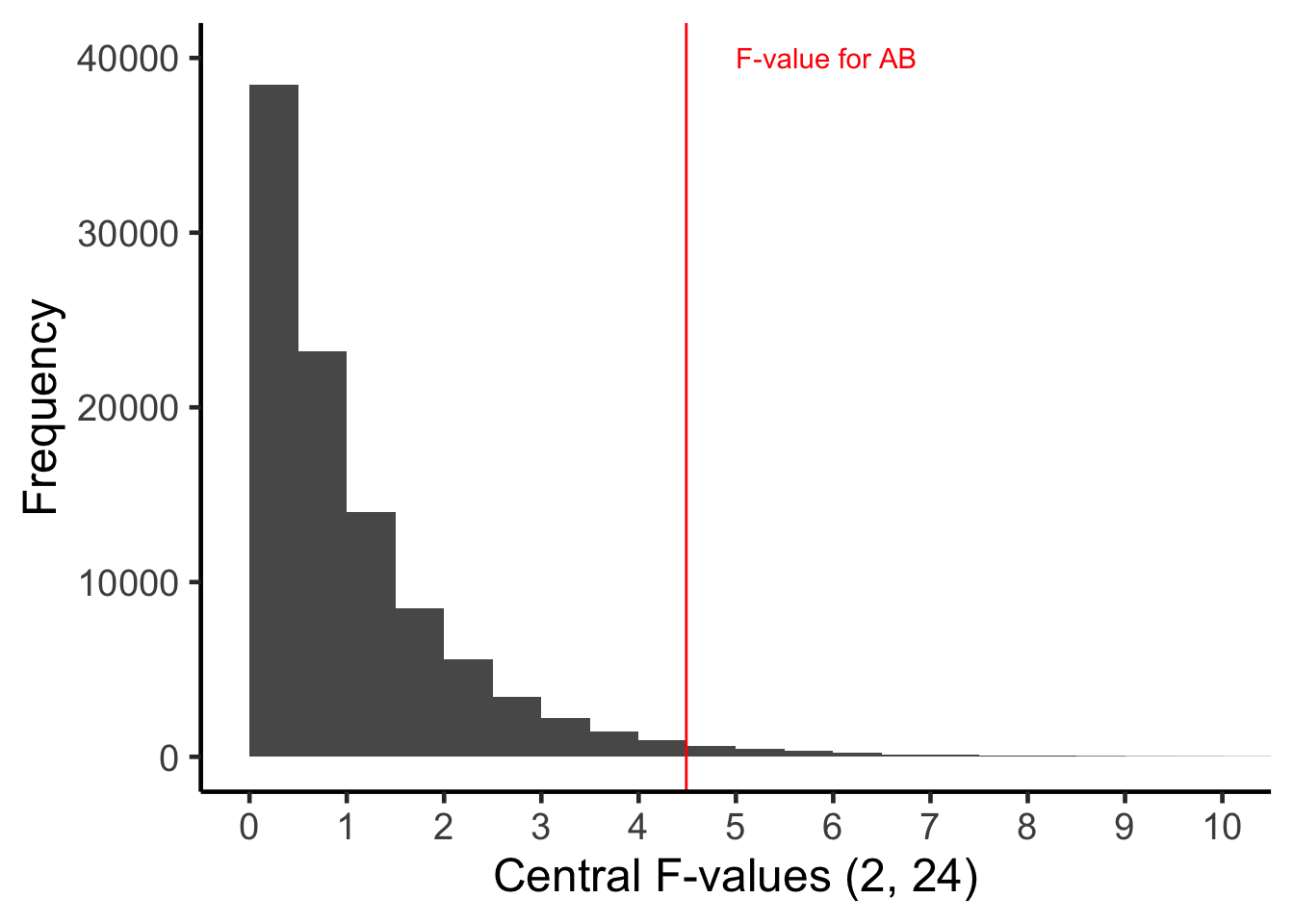
In the graph above you can see the \(F\)-value we obtained (4.49) is somewhat to the right side of the Central \(F\)-distribution. In fact, the proportion of the \(F\)-distribution that is equal to, or more extreme, than 4.49 is .022 (i.e. 2.2%). So we say the \(p\)-value is \(p = .022\).
Consequently, under the assumption of equal residual population means, our data (or more extreme data) is very unlikely (\(p = .022\)). Therefore, we reject the assumption that the population residual means are equal. We conclude those population means may be different. Which implies there is an interaction.
When there is an interaction you are concluding the two independent variables combine to influence the dependent variable. In our example study, you could say the impact of juggling on calmness before the exam depends on how much students prepared. Or you also say the impact of preparation on calmness before the exam depends on whether students juggled or not during breaks.
Remember the \(p\)-value is the probability of our data, or more extreme data, assuming the null hypothesis is true.
16.15.4 \(AB\) conceptual (interaction)
| Preparation | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Estimated observed variance [total] | \(\frac{\sum (\overline{x_{residual_i}})^2}{(a-1)(b-1)} = 53.92667\) | \(\frac{\sigma_{people}^2}{n} + \sigma_{AB}^2\) | \((a-1)(b-1)\) |
| Estimated expected variance [sampling error] | \(\frac{s_{people}^2}{n}=\frac{60}{5}=12\) | \(\frac{\sigma_{people}^2}{n}\) | \(ab(n-1)\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{\sum (\overline{x_{residual_i}} )^2}{(a-1)(b-1)}}{ \frac{s_{people}^2}{n}}=\frac{53.92667}{12}=4.49\) | \(\frac{\frac{\sigma_{people}^2}{n} + \sigma_{AB}^2}{ \frac{\sigma_{people}^2}{n}}\) | \([(a-1)(b-1),ab(n-1)]\) |
16.15.5 \(AB\) typical (interaction)

| Juggling | Formula | Expected value | degrees of freedom |
|---|---|---|---|
| Sample size multiplied by estimated total variance | \(\frac{n\sum (\overline{x_{residual_i}})^2}{(a-1)(b-1)}\) | \(\sigma_{people}^2 + n \sigma_{AB}^2\) | \((a-1)(b-1)\) |
| Estimated population variance | \(s_{people}^2\) | \(\sigma_{people}^2\) | \(ab(n-1)\) |
| Comparison using \(F\)-ratio | \(\frac{\frac{\sum (\overline{x_{residual_i}})^2}{(a-1)(b-1)}}{s_{people}^2}\) | \(\frac{\sigma_{people}^2 + n \sigma_{AB}^2}{\sigma_{people}^2}\) | \([(a-1)(b-1),ab(n-1)]\) |