Chapter 23 Next Step Resources
23.1 OSF
You can pre-register your study and upload your study materials via a free account:
Don’t forget you should also pre-register your outlier strategy. See (Leys et al. 2019) for guidance.
Also don’t forget to pre-register any analyses involving control variables. Control variables should be pre-registered with very specific predictions. See (Breaugh 2008) and (Spector and Brannick 2011) for guidance.
23.2 Transparency checklist
Be sure to check out the Transparency checklist. This is a great tool to help you ensure your process is transparent.
Also see Open Science: A Practical Guide for Early-Career Researchers.
23.3 Helpful web apps
Daniel Lakens has a number of very helpful web apps to help you with sample size planning and other issues. I encourage you to check them out here.
As well, check out Designing Experiments for some other helpful tools. Sampling size planning, effect size calculations, and more!
23.4 Minimizing mistakes
I strongly encourage you to check out (Rouder, Haaf, and Snyder 2019) and (Strand 2021) to learn how to minimize mistakes in your research.
23.5 Avoiding p-hacking
See both of these articles (Wicherts et al. 2016; Stratton and Neil 2005) to obtain advice on how to avoid p-hacking and other problems.
Stratton, I. M., & Neil, A. (2005). How to ensure your paper is rejected by the statistical reviewer. Diabetic medicine, 22(4), 371-373. Obviously, the advice in this article is “reverse-keyed”.
Also don’t forget about the Guelph Psychology Department Thesis Guidelines Website. The website is largely based on the advice of (Wicherts et al. 2016) but is slightly broader in focus and provides Department specific advice.
23.6 Writing articles
I suggest you check out (Gernsbacher 2018) “Writing empirical articles: Transparency, reproducibility, clarity, and memorability. Advances in methods and practices in psychological science” for excellent advice on writing articles (pictured below). Conversely, I suggest you AVOID “Writing the Empirical Journal Article” by Daryl Bem because this article has been described by some as a “how to guide” for p-hacking (i.e., finding the prettiest path in the garden of forking analysis paths).

23.7 Writing with R
The packages described below are very helpful for learning to write papers within RStudio.
23.7.1 rmarkdown / bookdown
One approach to avoiding errors in your article/thesis is to create a dynamic document. In this type of document you do not type the numbers into the document. Rather the document contains your analysis script (hidden from readers) and it inserts the calculated values into the text of the document. The exciting part of this type of document is that a single rmarkdown document and produce a number output formats such as PDF, Word, Power Point, HTML - as illustrated in the diagram below.
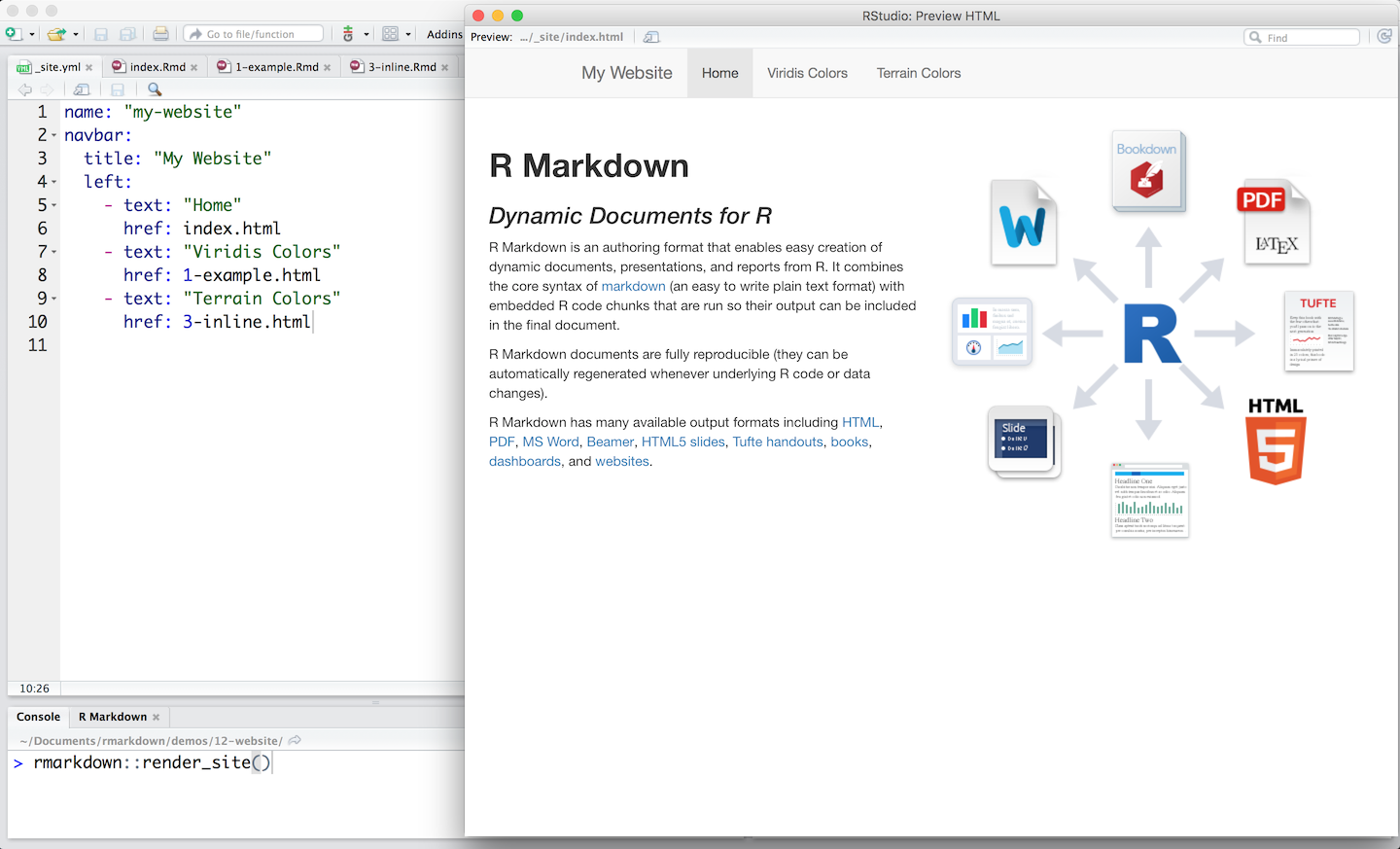
You can learn more about rmarkdown in this video. I suggest you read the official documentation to get started. Incidently, the PDF course assignments are made with rmardown - as well as this website!
Some other great resources:
pagedreport. If you are writing a consulting report this package could be very useful.
posterdown Instructions in case you want to make an academic poster using rmarkdown.
R Markdown: The Definitive Guide by Xie, Allaire, and Grolemund. Free.
R Markdown Cookbook by Xie, Dervieux, and Riederer. Free.
bookdown: Authoring Books and Technical Documents with R Markdow by Xie. Free.
Karl Broman’s website has many helpful tips. Especially this page.
23.7.2 LaTex
As you learn more about creating PDF document using rmarkdown - you will eventually want to learn about using LaTex. You can insert LaTex codes into your rmarkdown document to adjust the formatting (e.g., font size, etc.). Here are a few LaTex resources.
23.7.3 papaja
You may also find the rmarkdown template papaja package by Frederik Aust helpful. It’s an easy way to use rmarkdown. It is a based on the rmarkdown extension called bookdown. This package is specifically designed to make it easy to use rmarkdown/bookdown to make an APA style paper. Indeed that’s the basis for the odd package name: Preparing APA Journal Articles (papaja).
I suggest you read the extensive papaja (documentation)[https://crsh.github.io/papaja_man/introduction.html]. It will be worth your while!
The only slight complication with papaja is the fact it is not on the CRAN and can’t be installed in the usual way. But it’s still straight forward. You can install papaja with the commands below - taken from the papaja website.
# Install devtools package if necessary
if(!"devtools" %in% rownames(installed.packages())) install.packages("devtools")
# Install the stable development verions from GitHub
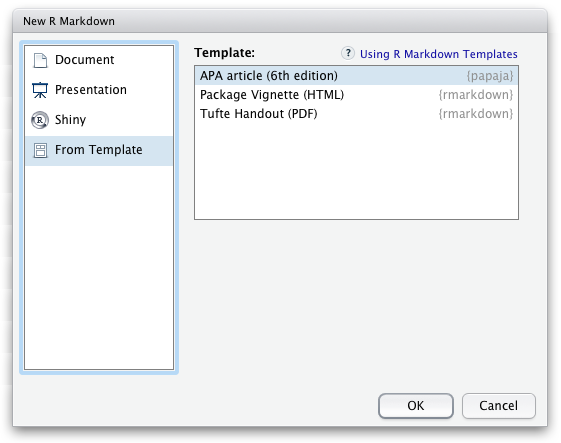
devtools::install_github("crsh/papaja")Indeed, once papaja is installed - you simply have to select the APA template before you enter your rmarkdown, as illustrated below:
23.7.4 Quarto
The rmarkdown language for document creation has evolved into Quarto. Quarto is more or less the same but is cross-platform statistically (i.e., Python, Julia, etc.). It represents the next step in this approach to document creation. I suggest you check it out - but Quarto is still in the early days. There are not nearly as many blogs, posts, or YouTube videos on Quarto as there are on rmarkdown - yet. So right now, I suggest you still learn rmarkdown, but realize the future is a slightly tweaked version of rmarkdown called Quarto.
Check out Mine Çetinkaya-Rundel’s video Get started with Quarto.
Also see Create & Publish a Quarto Blog on Quarto Pub in 100 Seconds.
You might also want to check a package for Quarto APA 7 papers.
23.7.5 apaTables
If you don’t want to learn rmarkdown you may find the apaTables package useful - it can easily create the most commonly used APA tables formatted for Microsoft Word. The documentation has extensive examples. You can also see the published guide by Stanley and Spence (2018).

23.8 Writing with statcheck
One concern associated with the replicability crisis is that the numbers reported in published articles are simply wrong. The numbers could be wrong due to typos or due to deliberate alteration (to ensure p < .05). Interestingly, one study decided to check if the p-values published in articles were correct (Nuijten et al. 2016). The authors checked the articles using the software statcheck. You can think of statcheck as a statistical spell checker that independently recreates the p-values in an article and checks if the reported p-value is correct. The authors used this process on over 250,000 p-values reported in eight major journals between 1985 and 2013. They found that roughly 50% of journal articles had a least one reporting error. Moreover, one in eight journal articles had a reporting error sufficiently large that it likely altered the conclusions of the paper. Note that incorrect p-values reported were typically smaller than they should been such that the incorrectly reported p-value was less than .05. That’s quite a large number of studies with incorrect p-values!
23.8.1 statcheck software
Fortunately, you can use statcheck on your own work before submitting it to an adviser or a journal. The statcheck software is available, as a website, a plug-in for Microsoft Word, and as an R package. You can see the GitHub page for statcheck here.
23.8.2 statcheck website
The statcheck website is easy to use. Just upload your PDF or Word document and it will perform the statcheck scan to determine if the numbers in your papers are correct / internally consistent. You can try it out with the PDF of a published article.
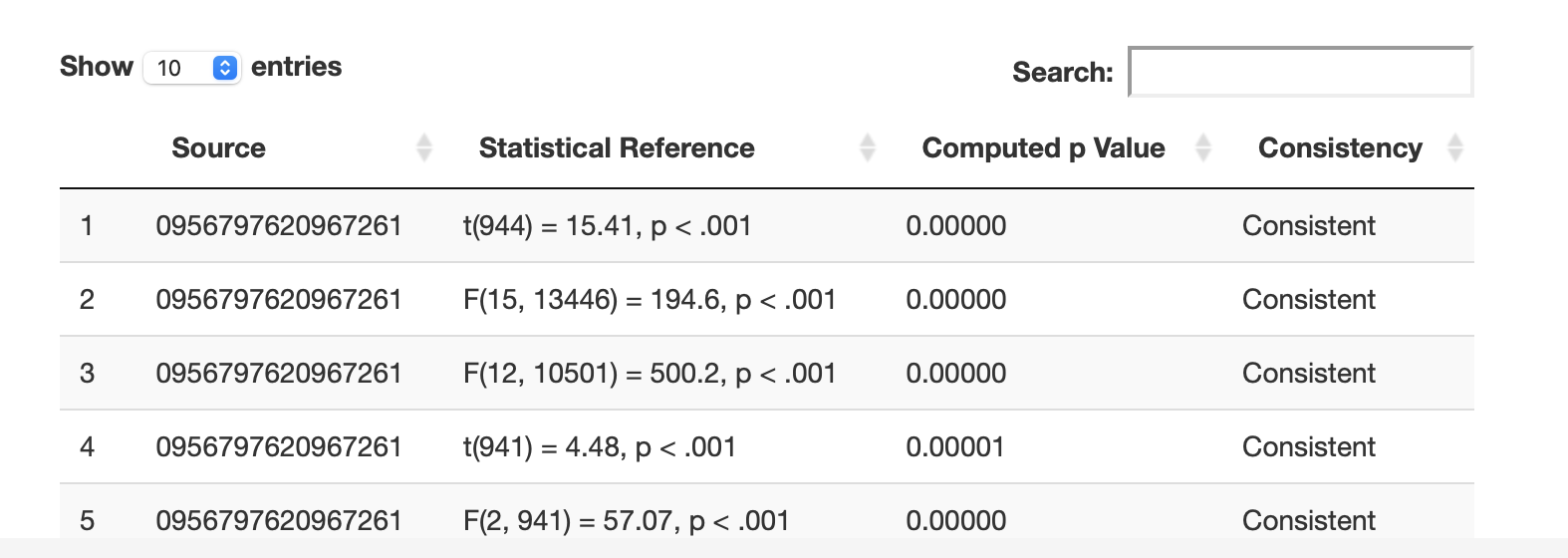
You can see the first few rows of the statcheck output for an article below:
23.8.3 statcheck and Word
Interestingly, statcheck will soon be available as plug-in for Word – as illustrated below. As you type it will perform the statcheck scan to determine if the numbers in your papers are correct / internally consistent. You can see the GitHub page for statcheck Word plug-in here.
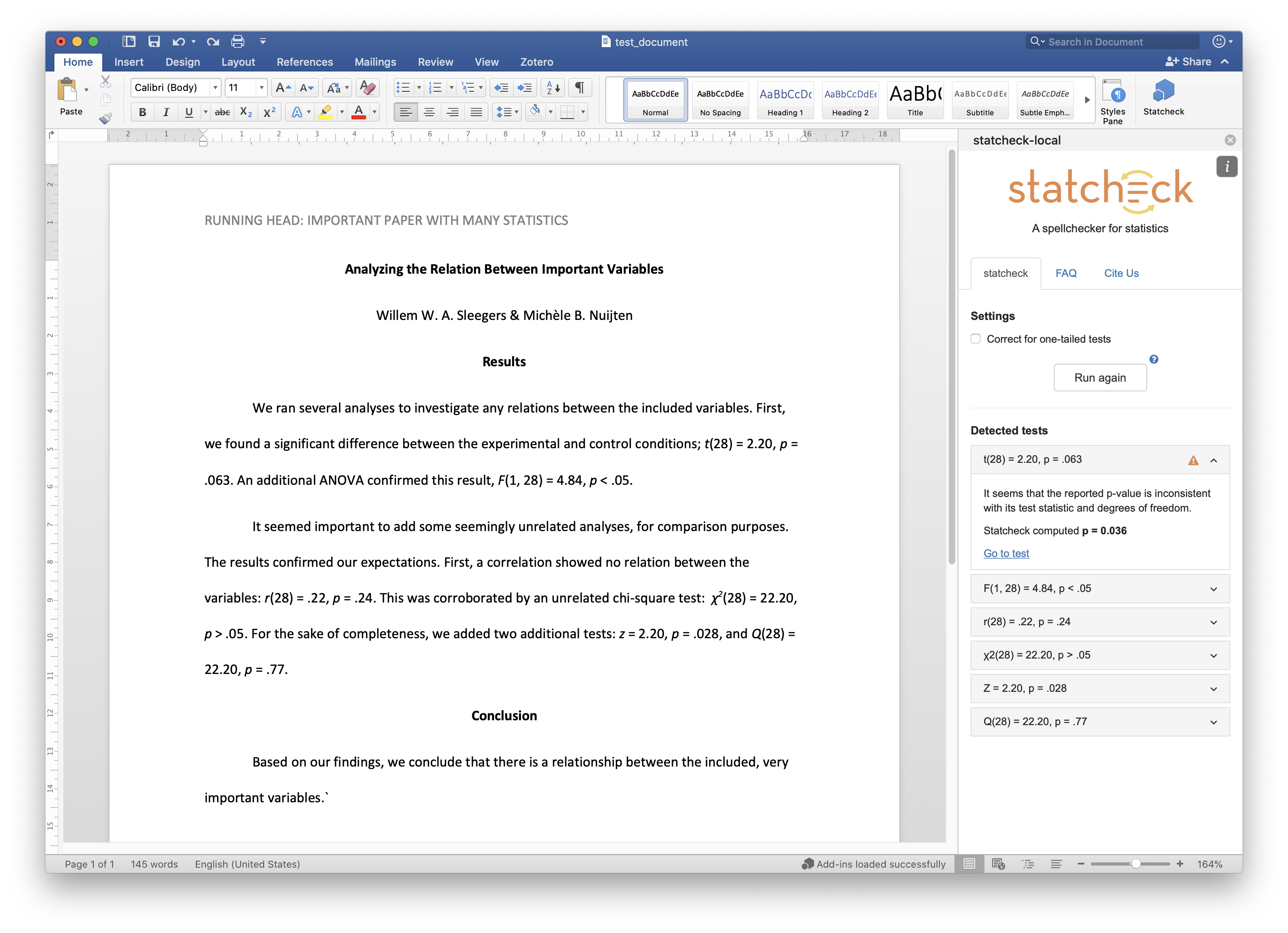
23.8.4 statcheck process
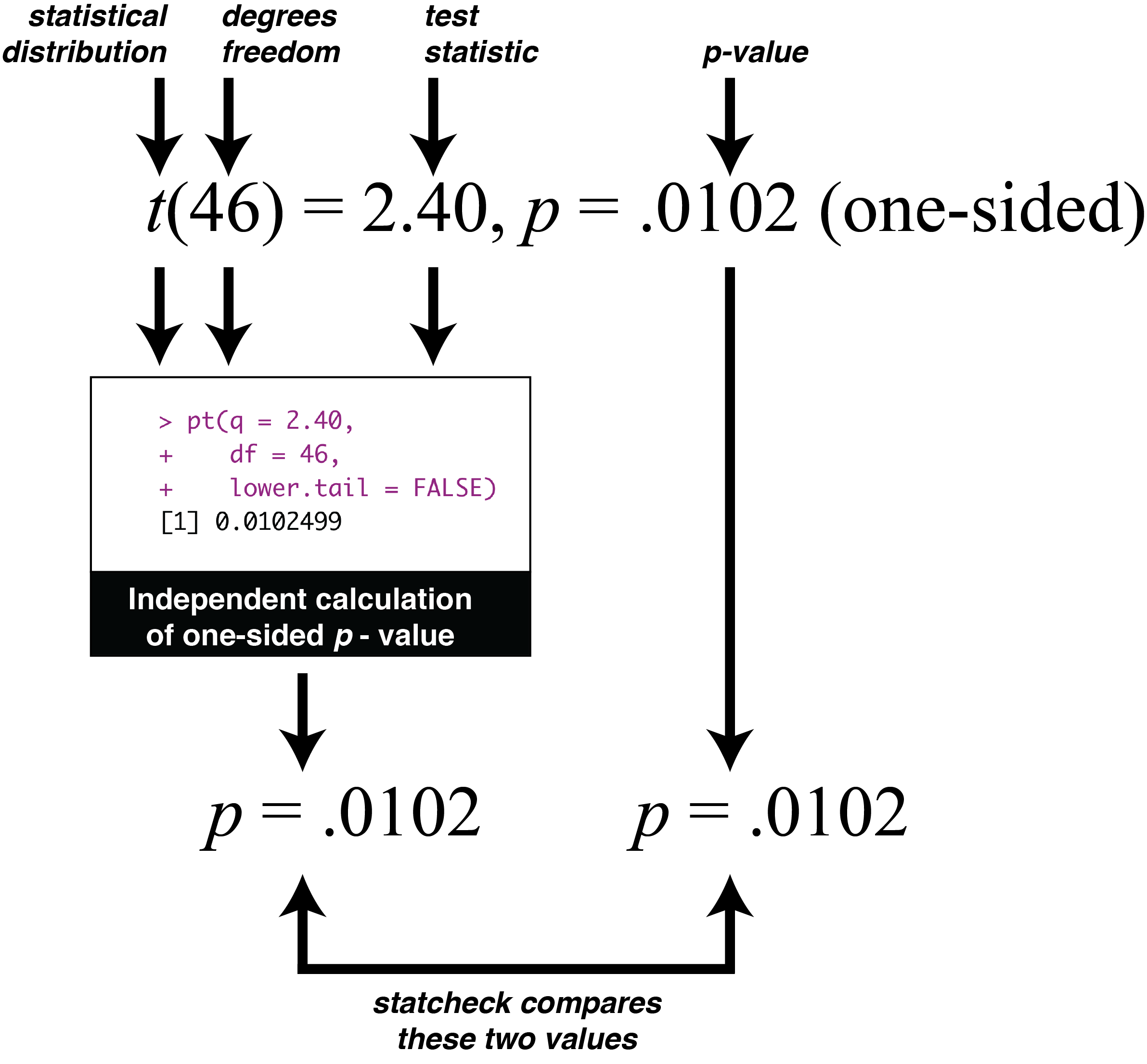
Exactly how does statcheck work? Statcheck is based on the fact that authors report redundant information in their papers. For example, an author might report the statistics: t(46) = 2.40, p = .0102 (one-sided). Or in the past report this information using a p-value threshold: t(46) = 2.40, p < .05 (one-sided). The first part of this reporting, t(46) = 2.40, can be used to independently generate the p-value, as illustrated below. The software does so and then simply compares the independently generated p-value with the reported p-value (e.g., p = 0102) or p-value threshold (p < .05). You would think the independently generated p-value and the reported p-value would always match. But as illustrated by (Nuijten et al. 2016) at least 50% of papers of a problem with the p-values reported matching the correct p-value.
23.8.5 statcheck validity
Although there were some initial concerns about the validity of statcheck, subsequent research on the package indicates an impressive validity level of roughly 90% (or a little higher/lower depending on the settings used). Indeed, in July of 2016, the journal Psychological Science started using statcheck on all submitted manuscripts - once they passed an initial screen. Journal editor, Stephen Lindsey, reports there has been little resistance to doing so “Reaction has been almost non-existent.”
23.9 Journal rankings via the TOP Factor
When you’re done writing - you need to decide upon a journal. You can see journal rankings based on the Transparency and Openness Promotion Guidelines at the Top Factor website.
23.10 Statistics books
If you want to learn more about statistics I suggest (Maxwell, Delaney, and Kelley 2017), (Cohen et al. 2014), and (Baguley 2012).
Maxwell, S. E., Delaney, H. D., & Kelley, K. (2017). Designing experiments and analyzing data: A model comparison perspective. Routledge. by Maxwell, Delaney, and Kelley. This book has a fantastic website (https://designingexperiments.com) with online tools and R scripts.
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2014). Applied multiple regression/correlation analysis for the behavioral sciences. Psychology press. by Cohen, Cohen, West, and Aiken. This is the “go to” resource if you are conducting moderated multiple regression. A great book on regression beyond just moderation though.
Baguley, T. (2012). Serious stats: A guide to advanced statistics for the behavioral sciences. Macmillan International Higher Education. by Baguley. The book title tells you everything you need to know about this one.
Hayes, A. F. (2017). Introduction to mediation, moderation, and conditional process analysis: A regression-based approach. Guilford publications.. Many people use the approach in this book when they have multiple mediators and moderators. The PROCESS [website]((https://processmacro.org/index.html) has the R-script for the PROCESS macro.
Check out Daniel Lakens great free book Improving Your Statistical Inferences.
23.11 General R books
There are many R books out there. I believe that you will find these most helpful:
Data Visualization by Healy. Free.
Fundamentals of Data Visualization by Wilke. Free.
R Graphics Cookbook by Chang. Free.
ggplot2 by Wickham. Free.
R for Data Science by Wickham and Grolemund. Free.
Hands-On Programming with R by Grolemund. Free.
Advanced R by Wickham. Free.
Art of R Programming by Matloff.
Then some books that are great but less likely to by used by psychology folks:
Mastering Shiny by Wickham. Free.
R packages by Wickham Free.
Efficient R Programming by Lovelace. Free.
Text Mining with R by Silge and Robinson. Free.
Javascript for R by Coene. Free.
Practical Data Science with R by Zumel and Mount.
Functional Programming in R by Mailund.
Deep learning with R Chollet and Allaire.
Extending R by Chambers.
23.12 Retracted articles
As you write-up your research you need to be concerned with the problem of citing research papers that have been retracted. This problem is substantially larger than you might first expect; indeed, one group of researchers found that retracted papers often received the majority their citations after retraction (Madlock-Brown and Eichmann 2015). Therefore, take the extra time to confirm the papers you cite have not been retracted! Moreover, don’t assume because an article was published in a high-impact journal that it is a high quality article - and not likely to be retracted. The truth is the opposite. Retraction rates correlate positively with journal impact factor (how often articles in that journal are cited). Specifically, journals with high impact factors have the higest retraction rate (Fang and Casadevall 2011).

23.12.1 DOI
But how do you go about determining if a paper has been retracted? There are websites you can check like retraction watch. It can, however, be time consuming to check for every article in this website. There is an easier approach but it requires you know the DOI number for each article you cite.
What is a DOI number? All modern journal articles have a DOI (digital object identifier) number associated with them. This is a unique number that identifies the article and can be used to access the document.
You can see a DOI number on a PDF:

Or you can see a DOI number on the website:
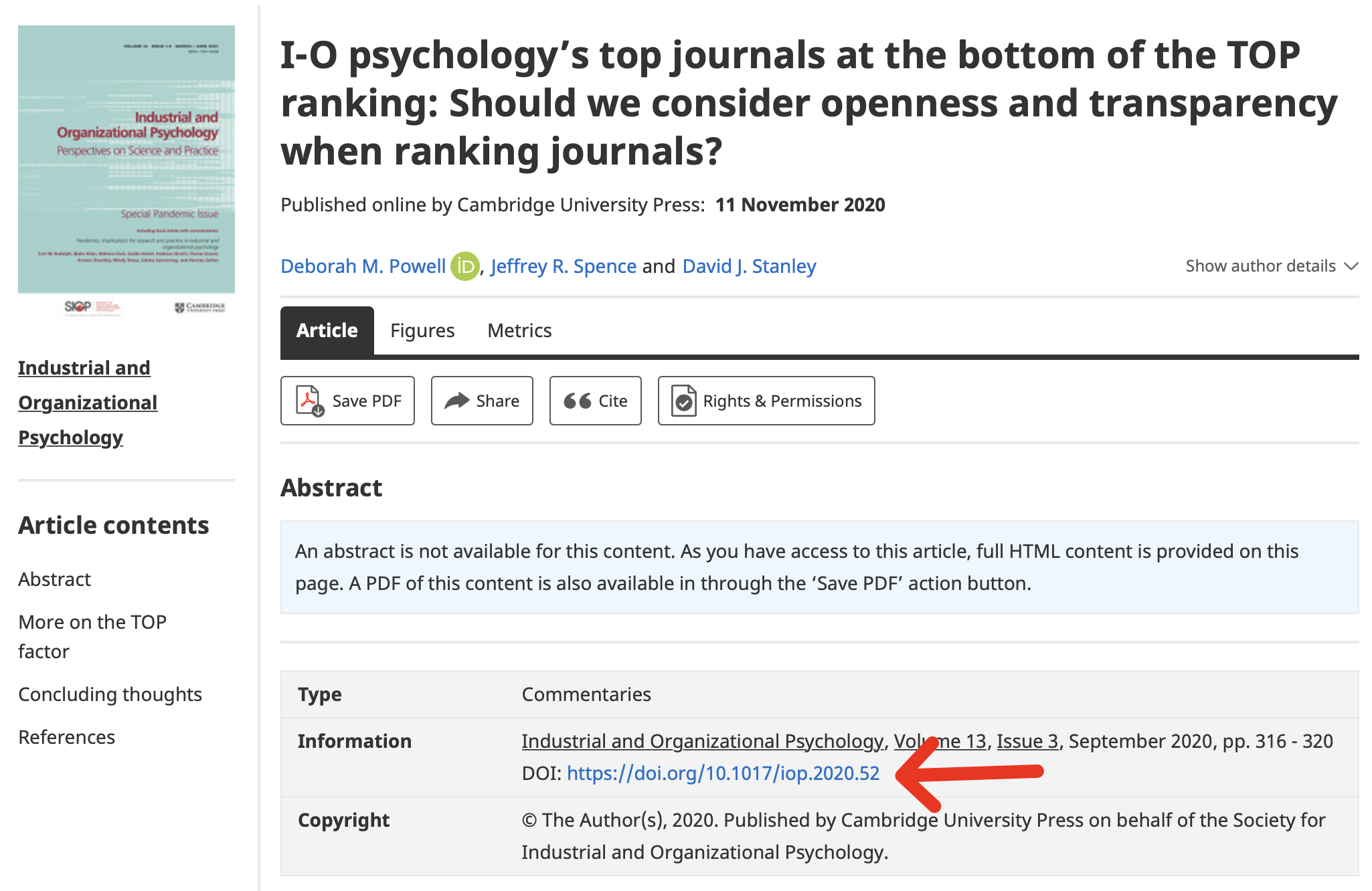
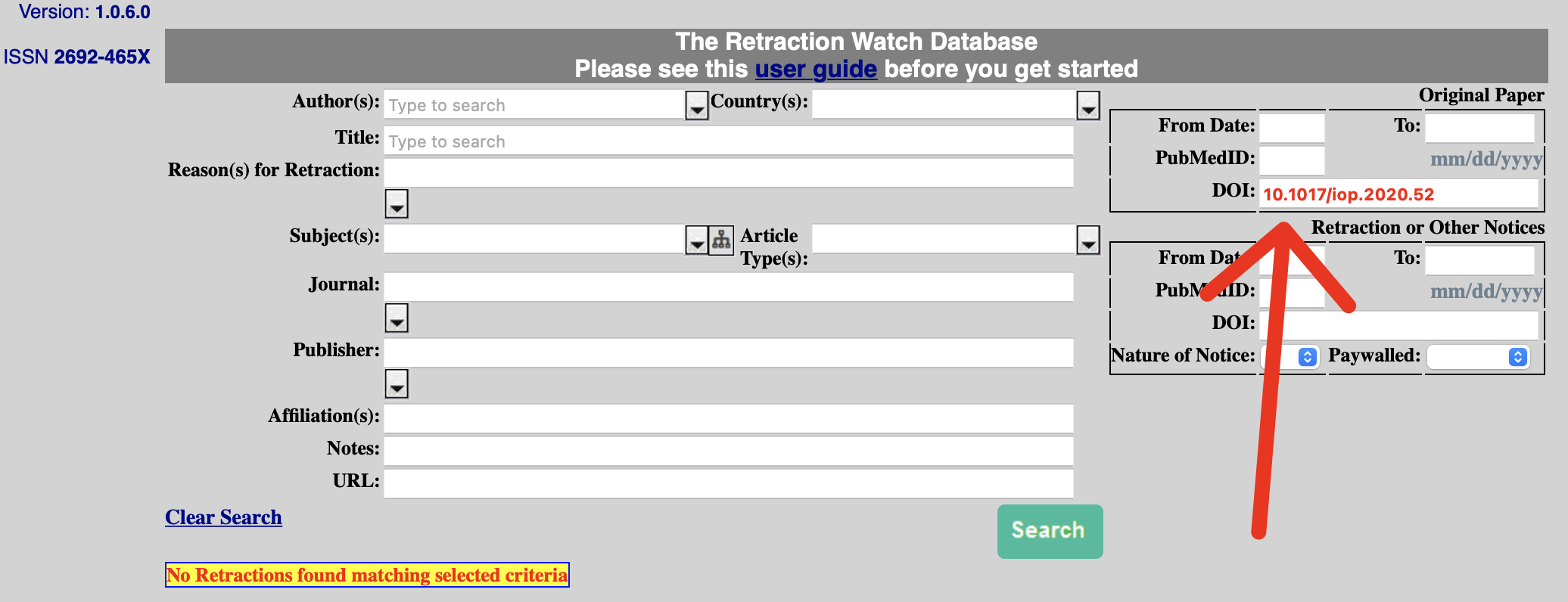
Retraction search with DOI
You can enter the DOI up on the search site as illustrated below. Then click the Search button. You will get the search output. Notice the yellow box in the lower left which indicates this article has NOT been retracted.
23.12.2 retractiondatabase.org
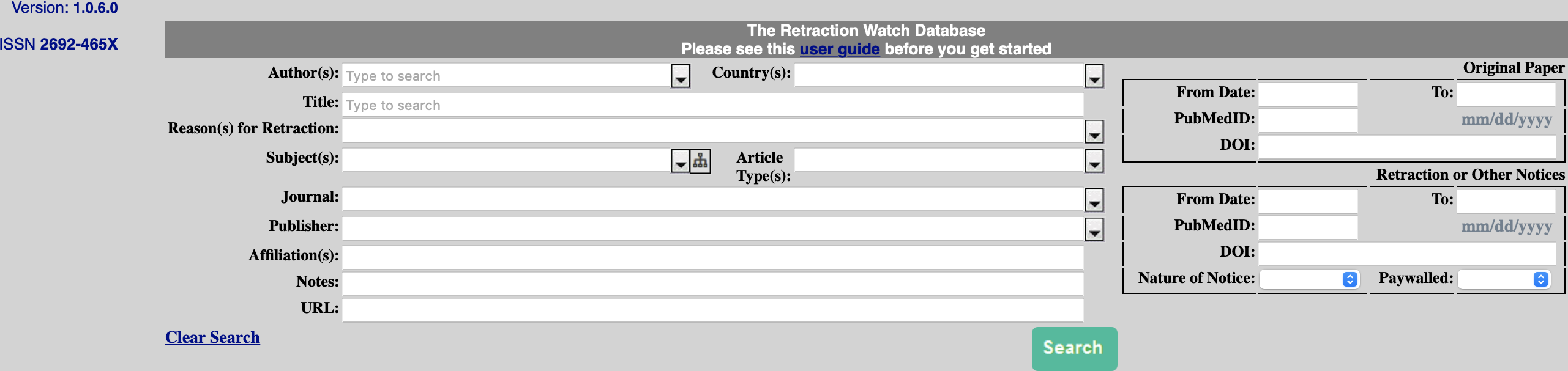
If you don’t have the DOI number for an article you can search for by article title or author at http://retractiondatabase.org as you can see from the interface below.
23.12.3 openretractions.com
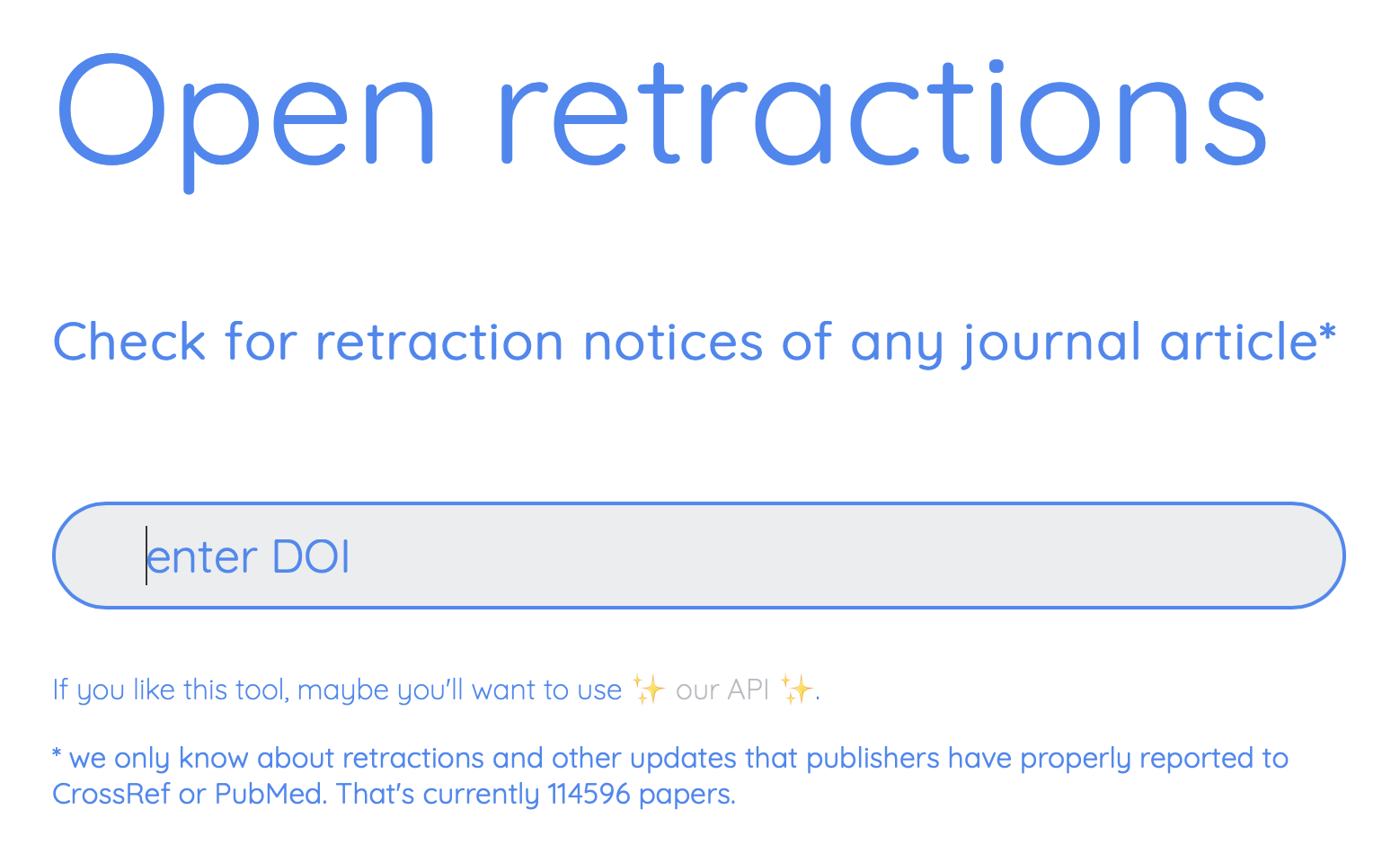
However, if you have the DOI number for an article, an easier approach is use the http://openretractions.com website. At this website you type in the DOI number for an article and it checks if that article has been retracted.
23.12.4 retractcheck
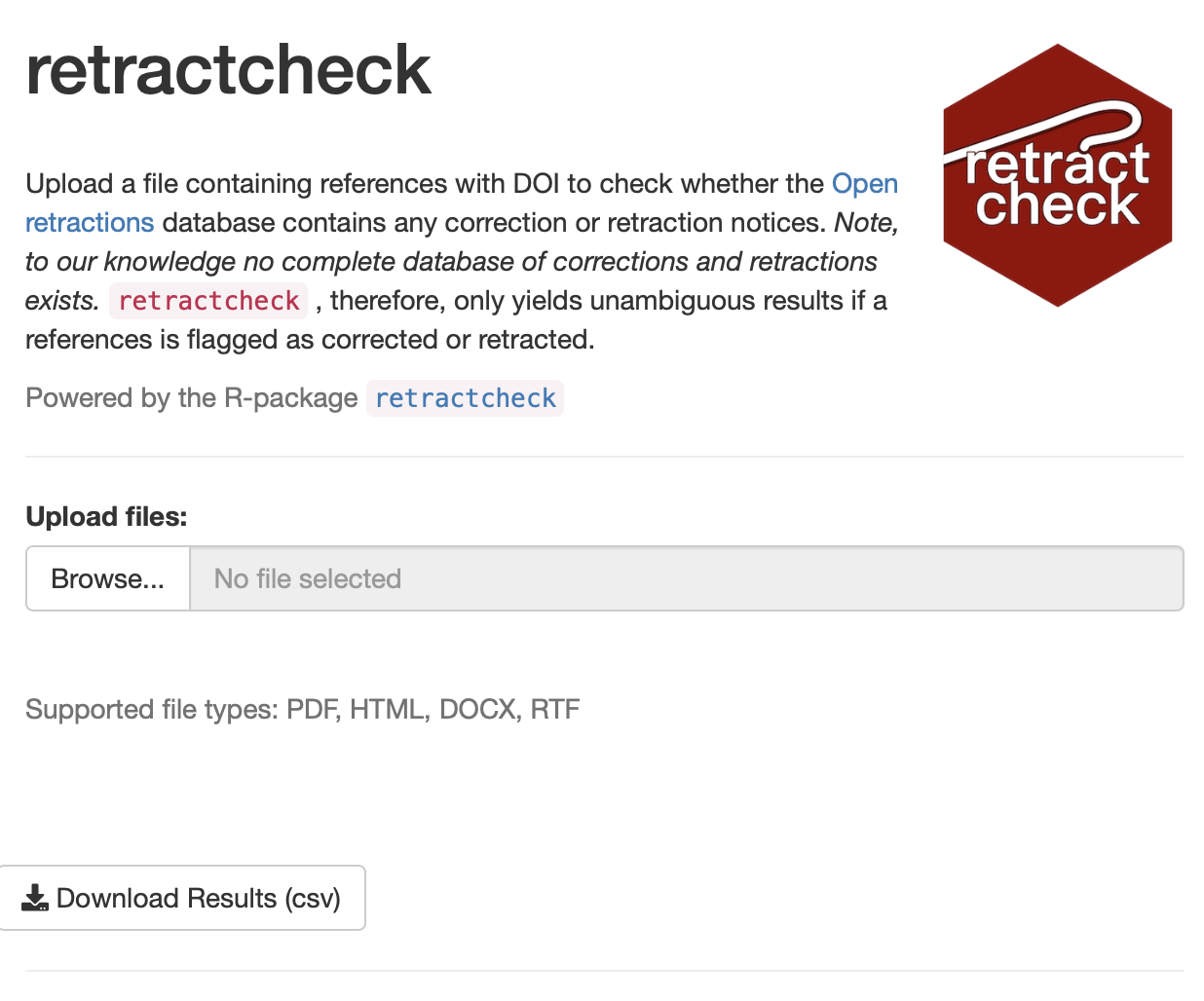
Even better, you can use the retractcheck R package. With this package you can check large batches of DOI numbers with openretractions.com to see if the corresponding articles have been retracted. You can use this package by the command line or via the website illustrated below.
23.13 Big data
Occasionally psychology researchers deal with big data. File sizes can be quite large with big data. Check out the arrow package, specifically, the write_parquet() command as means of using smaller file sizes. This approach can make sharing a file on GitHub, or emailing it to a colleague, substantially easier.
![]()